







学习目标:
一、论文“Vector Quantized Diffusion Model for Text-to-Image Synthesis”的Code
二、猫狗识别、人脸识别模型
学习内容:
Code
学习时间:
12.4-12.9
学习产出:
一、论文Code
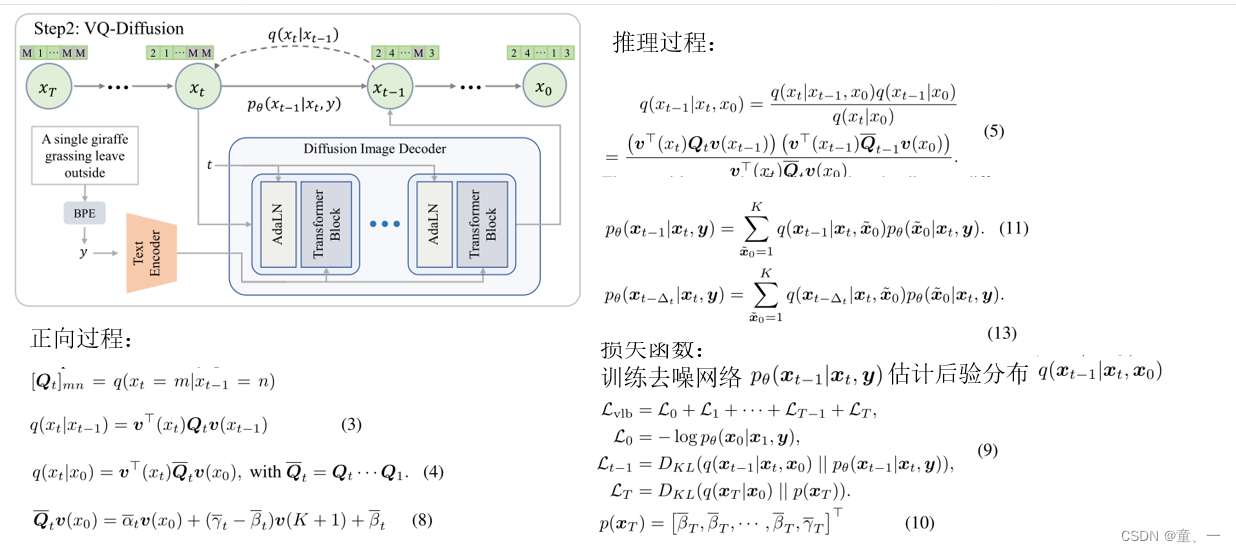
正向过程:
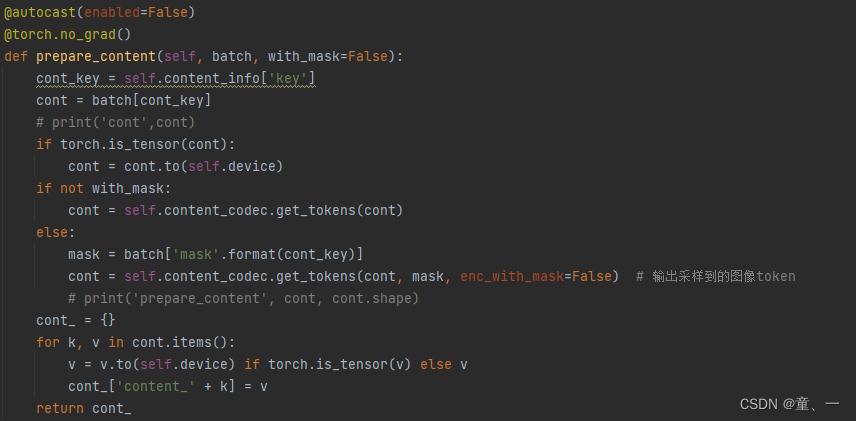
先通过TamingGumbelVQVAE采样得到图像token
然后通过Tokenize采样得到文本标记y
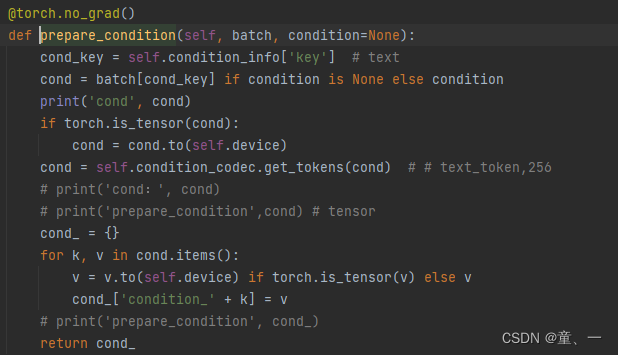
然后将文本标记y和图像token输入进DiffusionTransformer,在forward中
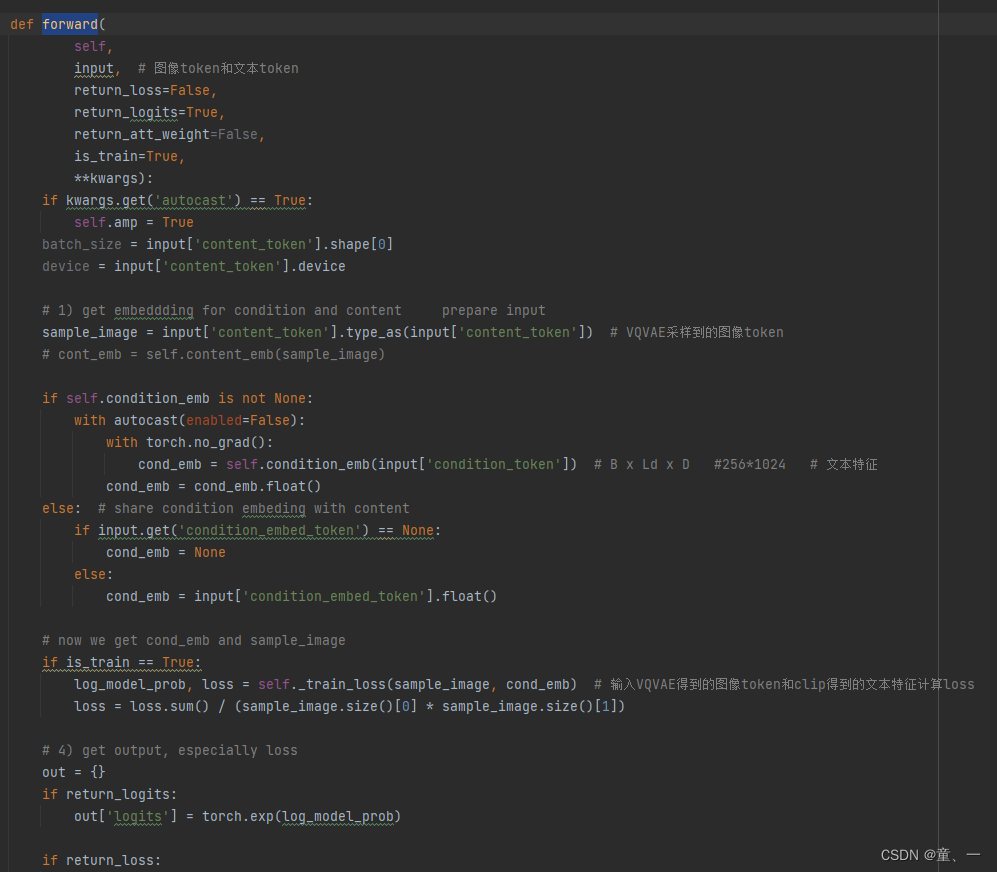
会通过
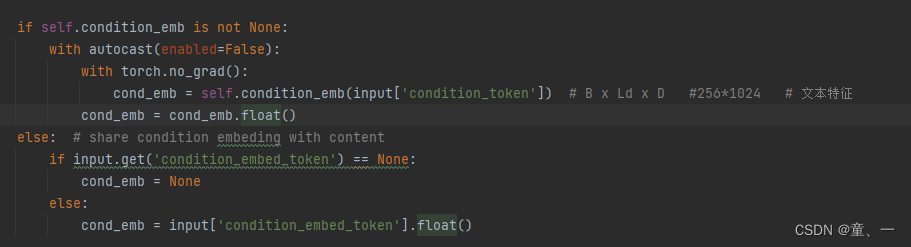
将文本标记y输入CLIPTextEmbedding中,提取文本特征

然后计算loss
def _train_loss(self, x, cond_emb, is_train=True): # get the KL loss
b, device = x.size(0), x.device
assert self.loss_type == 'vb_stochastic'
x_start = x
t, pt = self.sample_time(b, device, 'importance')
# 将图像token变为独热编码
log_x_start = index_to_log_onehot(x_start, self.num_classes)
log_xt = self.q_sample(log_x_start=log_x_start, t=t) # x0和t前向得到噪声Xt
xt = log_onehot_to_index(log_xt) # 得到Xt的索引
############### go to p_theta function ###############
log_x0_recon = self.predict_start(log_xt, cond_emb, t=t) # P_theta(x0|xt) # 网络预测得到的X0,对应11式右边
log_model_prob = self.q_posterior(log_x_start=log_x0_recon, log_x_t=log_xt,
t=t) # go through q(xt_1|xt,x0),得到P_theta分布得到的Xt-1,对应11式左边和5式
################## compute acc list ################
x0_recon = log_onehot_to_index(log_x0_recon)
x0_real = x_start
xt_1_recon = log_onehot_to_index(log_model_prob)
xt_recon = log_onehot_to_index(log_xt)
for index in range(t.size()[0]):
this_t = t[index].item()
# (网络得到的X0==原始的X0)/原始X0
# (X0'==X0) / X0
same_rate = (x0_recon[index] == x0_real[index]).sum().cpu() / x0_real.size()[1]
self.diffusion_acc_list[this_t] = same_rate.item() * 0.1 + self.diffusion_acc_list[this_t] * 0.9
# (Xt-1==X0') / X0'
same_rate = (xt_1_recon[index] == xt_recon[index]).sum().cpu() / xt_recon.size()[1]
self.diffusion_keep_list[this_t] = same_rate.item() * 0.1 + self.diffusion_keep_list[this_t] * 0.9
# compute log_true_prob now
# DDPM中加噪使用的是原始noise,因此计算的是网络预测到的噪声和原始noise之间的差异
# VQDM中计算的是网络预测的X0‘和由矩阵得到的X0之间的差异
log_true_prob = self.q_posterior(log_x_start=log_x_start, log_x_t=log_xt,
t=t) # 这里计算的是5式,X0和Xt通过q_posterior得到Xt-1
kl = self.multinomial_kl(log_true_prob, log_model_prob)
mask_region = (xt == self.num_classes - 1).float()
mask_weight = mask_region * self.mask_weight[0] + (1. - mask_region) * self.mask_weight[1]
kl = kl * mask_weight
kl = sum_except_batch(kl)
decoder_nll = -log_categorical(log_x_start, log_model_prob)
decoder_nll = sum_except_batch(decoder_nll)
mask = (t == torch.zeros_like(t)).float()
kl_loss = mask * decoder_nll + (1. - mask) * kl
Lt2 = kl_loss.pow(2)
Lt2_prev = self.Lt_history.gather(dim=0, index=t)
new_Lt_history = (0.1 * Lt2 + 0.9 * Lt2_prev).detach()
self.Lt_history.scatter_(dim=0, index=t, src=new_Lt_history)
self.Lt_count.scatter_add_(dim=0, index=t, src=torch.ones_like(Lt2))
# Upweigh loss term of the kl
# vb_loss = kl_loss / pt + kl_prior
loss1 = kl_loss / pt
vb_loss = loss1
if self.auxiliary_loss_weight != 0 and is_train == True:
kl_aux = self.multinomial_kl(log_x_start[:, :-1, :], log_x0_recon[:, :-1, :])
kl_aux = kl_aux * mask_weight
kl_aux = sum_except_batch(kl_aux)
kl_aux_loss = mask * decoder_nll + (1. - mask) * kl_aux
if self.adaptive_auxiliary_loss == True:
addition_loss_weight = (1 - t / self.num_timesteps) + 1.0
else:
addition_loss_weight = 1.0
loss2 = addition_loss_weight * self.auxiliary_loss_weight * kl_aux_loss / pt
vb_loss += loss2
return log_model_prob, vb_loss
在train_loss中,会将图像token变为独热向量,然后将图像通过q_sample函数得到Xt

在q_sample函数中得到噪声Xt
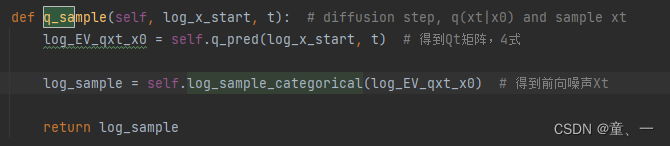
然后将噪声Xt变为独热向量和文本特征通过predict_start预测得到


在predict_start函数中,独热向量Xt和文本特征会通过Text2ImageTransformer进行注意力计算得到X0’
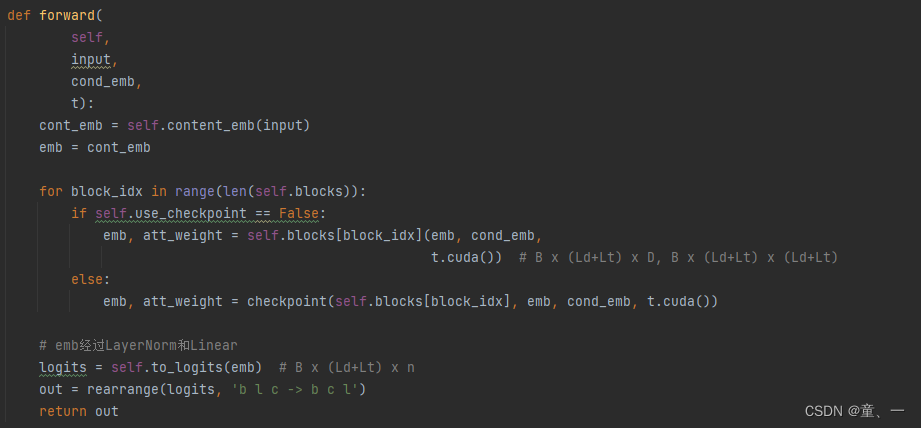
文本特征和独热向量进行注意力计算后相加
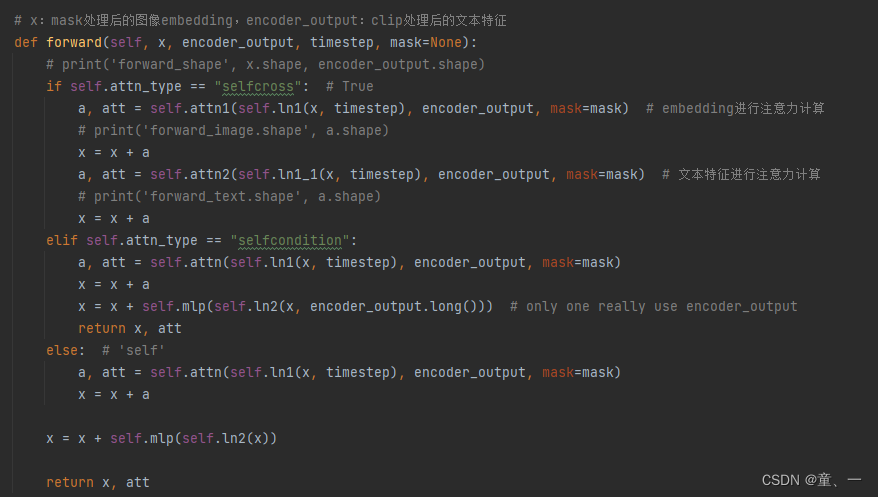
独热向量Xt进行注意力计算
# 计算图像矩阵
class FullAttention(nn.Module):
def __init__(self,
n_embd, # the embed dim
n_head, # the number of heads
seq_len=None, # the max length of sequence
attn_pdrop=0.1, # attention dropout prob
resid_pdrop=0.1, # residual attention dropout prob
causal=True,
):
super().__init__()
assert n_embd % n_head == 0
# key, query, value projections for all heads
self.key = nn.Linear(n_embd, n_embd)
self.query = nn.Linear(n_embd, n_embd)
self.value = nn.Linear(n_embd, n_embd)
# regularization
self.attn_drop = nn.Dropout(attn_pdrop)
self.resid_drop = nn.Dropout(resid_pdrop)
# output projection
self.proj = nn.Linear(n_embd, n_embd)
self.n_head = n_head
self.causal = causal
def forward(self, x, encoder_output, mask=None):
B, T, C = x.size()
k = self.key(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = self.value(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) # (B, nh, T, T)
att = F.softmax(att, dim=-1) # (B, nh, T, T)
att = self.attn_drop(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side, (B, T, C)
att = att.mean(dim=1, keepdim=False) # (B, T, T)
# output projection
y = self.resid_drop(self.proj(y))
return y, att
文本特征进行注意力计算
class CrossAttention(nn.Module):
def __init__(self,
condition_seq_len,
n_embd, # the embed dim
condition_embd, # condition dim
n_head, # the number of heads
seq_len=None, # the max length of sequence
attn_pdrop=0.1, # attention dropout prob
resid_pdrop=0.1, # residual attention dropout prob
causal=True,
):
super().__init__()
assert n_embd % n_head == 0
# key, query, value projections for all heads
self.key = nn.Linear(condition_embd, n_embd)
self.query = nn.Linear(n_embd, n_embd)
self.value = nn.Linear(condition_embd, n_embd)
# regularization
self.attn_drop = nn.Dropout(attn_pdrop)
self.resid_drop = nn.Dropout(resid_pdrop)
# output projection
self.proj = nn.Linear(n_embd, n_embd)
self.n_head = n_head
self.causal = causal
# causal mask to ensure that attention is only applied to the left in the input sequence
if self.causal:
self.register_buffer("mask", torch.tril(torch.ones(seq_len, seq_len))
.view(1, 1, seq_len, seq_len))
def forward(self, x, encoder_output, mask=None):
B, T, C = x.size()
B, T_E, _ = encoder_output.size()
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
k = self.key(encoder_output).view(B, T_E, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = self.query(x).view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = self.value(encoder_output).view(B, T_E, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) # (B, nh, T, T)
att = F.softmax(att, dim=-1) # (B, nh, T, T)
att = self.attn_drop(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side, (B, T, C)
att = att.mean(dim=1, keepdim=False) # (B, T, T)
# output projection
y = self.resid_drop(self.proj(y))
return y, att
predict_start得到X0’后与噪声Xt输入q_posterior函数得到Xt-1
# 1、得到log_model_prob(p(Xt-1|Xt,y))时:输入的是transformer中得到的X0'和噪声Xt
# 2、得到log_true_prob(q(Xt-1|Xt,X0))时:输入的是VQVAE得到的X0(无噪声)和噪声Xt
def q_posterior(self, log_x_start, log_x_t, t): # p_theta(xt_1|xt) = sum(q(xt-1|xt,x0')*p(x0'))
# notice that log_x_t is onehot
assert t.min().item() >= 0 and t.max().item() < self.num_timesteps
batch_size = log_x_start.size()[0]
onehot_x_t = log_onehot_to_index(log_x_t) # Xt编码为独热向量
mask = (onehot_x_t == self.num_classes - 1).unsqueeze(1) # 获得mask
log_one_vector = torch.zeros(batch_size, 1, 1).type_as(log_x_t)
log_zero_vector = torch.log(log_one_vector + 1.0e-30).expand(-1, -1, self.content_seq_len)
log_qt = self.q_pred(log_x_t, t) # q(xt|x0)
# log_qt = torch.cat((log_qt[:,:-1,:], log_zero_vector), dim=1)
log_qt = log_qt[:, :-1, :]
log_cumprod_ct = extract(self.log_cumprod_ct, t, log_x_start.shape) # ct~ # mask时使用的ct
ct_cumprod_vector = log_cumprod_ct.expand(-1, self.num_classes - 1, -1)
# ct_cumprod_vector = torch.cat((ct_cumprod_vector, log_one_vector), dim=1)
log_qt = (~mask) * log_qt + mask * ct_cumprod_vector # Qt经过mask处理得到有mask的内容
log_qt_one_timestep = self.q_pred_one_timestep(log_x_t, t) # q(xt|xt_1) # 得到Xt-1到Xt中间的一步
log_qt_one_timestep = torch.cat((log_qt_one_timestep[:, :-1, :], log_zero_vector), dim=1)
log_ct = extract(self.log_ct, t, log_x_start.shape) # ct
ct_vector = log_ct.expand(-1, self.num_classes - 1, -1)
ct_vector = torch.cat((ct_vector, log_one_vector), dim=1)
log_qt_one_timestep = (~mask) * log_qt_one_timestep + mask * ct_vector # 得到mask和去噪
# log_x_start = torch.cat((log_x_start, log_zero_vector), dim=1)
# q = log_x_start - log_qt
q = log_x_start[:, :-1, :] - log_qt # X0'去掉mask得到无mask的X0'
q = torch.cat((q, log_zero_vector), dim=1)
q_log_sum_exp = torch.logsumexp(q, dim=1, keepdim=True) # 返回行求和的q的对数
q = q - q_log_sum_exp
# self.q_pred(q, t - 1):去掉mask的X0'经过Qt矩阵进行去噪
log_EV_xtmin_given_xt_given_xstart = self.q_pred(q, t - 1) + log_qt_one_timestep + q_log_sum_exp # 经过
return torch.clamp(log_EV_xtmin_given_xt_given_xstart, -70, 0)
然后在train_loss中,噪声Xt和X0会通过q_posterior(即等式5)得到不含文本特征y的图像Xt-1
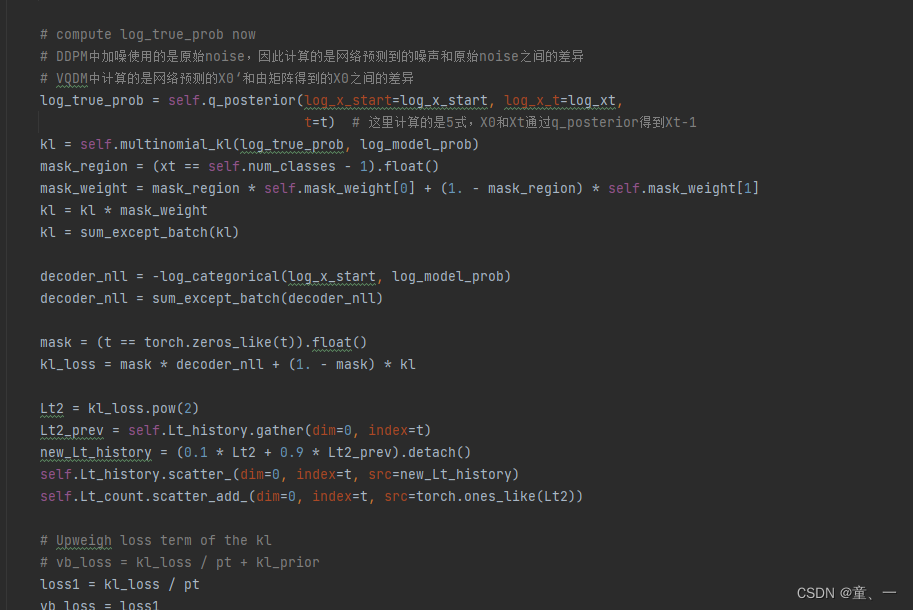
然后将两个Xt-1计算KL得到损失。
推理过程
def sample(
self,
condition_token,
condition_mask,
condition_embed,
content_token=None,
filter_ratio=0.5,
temperature=1.0,
return_att_weight=False,
return_logits=False,
content_logits=None,
print_log=True,
**kwargs):
input = {'condition_token': condition_token,
'content_token': content_token,
'condition_mask': condition_mask,
'condition_embed_token': condition_embed,
'content_logits': content_logits,
}
if input['condition_token'] != None:
batch_size = input['condition_token'].shape[0]
else:
batch_size = kwargs['batch_size']
device = self.log_at.device
start_step = int(self.num_timesteps * filter_ratio)
# get cont_emb and cond_emb
if content_token != None:
sample_image = input['content_token'].type_as(input['content_token'])
# 得到y
if self.condition_emb is not None: # do this
with torch.no_grad():
cond_emb = self.condition_emb(input['condition_token']) # B x Ld x D #256*1024
cond_emb = cond_emb.float()
else: # share condition embeding with content
if input.get('condition_embed_token', None) != None:
cond_emb = input['condition_embed_token'].float()
else:
cond_emb = None
if start_step == 0:
# use full mask sample
zero_logits = torch.zeros((batch_size, self.num_classes - 1, self.shape), device=device)
one_logits = torch.ones((batch_size, 1, self.shape), device=device)
mask_logits = torch.cat((zero_logits, one_logits), dim=1)
log_z = torch.log(mask_logits)
start_step = self.num_timesteps
with torch.no_grad():
for diffusion_index in range(start_step - 1, -1, -1):
t = torch.full((batch_size,), diffusion_index, device=device, dtype=torch.long)
log_z = self.p_sample(log_z, cond_emb, t) # log_z is log_onehot
else:
t = torch.full((batch_size,), start_step - 1, device=device, dtype=torch.long)
log_x_start = index_to_log_onehot(sample_image, self.num_classes)
log_xt = self.q_sample(log_x_start=log_x_start, t=t) # 采样得到Xt
log_z = log_xt
with torch.no_grad():
for diffusion_index in range(start_step - 1, -1, -1):
t = torch.full((batch_size,), diffusion_index, device=device, dtype=torch.long) # 得到t
log_z = self.p_sample(log_z, cond_emb, t) # log_z is log_onehot
content_token = log_onehot_to_index(log_z)
output = {'content_token': content_token}
if return_logits:
output['logits'] = torch.exp(log_z)
return output
得到时间步t和文本标记y以及采样出的噪声Xt,将这三个输入网络进行预测得到Xt-1,不断循环直到X0,然后将X0通过VQVAE的Decoder得到图像。
二、检测模型
使用yolov7进行了猫狗和人脸的识别。















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









