







 本文介绍了如何使用ChatGLM3模型进行工具调用,特别是如何自定义工具来查询MySQL数据库。通过注册工具、编写自定义代码,并在官方页面或通过API调用来使用这些工具,增强了大模型的功能,使其能执行特定任务,如查询数据库。
本文介绍了如何使用ChatGLM3模型进行工具调用,特别是如何自定义工具来查询MySQL数据库。通过注册工具、编写自定义代码,并在官方页面或通过API调用来使用这些工具,增强了大模型的功能,使其能执行特定任务,如查询数据库。

ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
什么是工具调用
大模型虽然强大,但是由于训练的时间和语料限制。大模型通常会存在以下问题:
- 只能获取训练数据集中有的事件和内容,这意味着大模型不具备访问最新资料的能力。
- ChatGLM3-6B模型以通用语料训练为主,因此,缺少专业领域的知识。
- ChatGLM3-6B体量较小,虽然拥有较强的数学,英语等能力,但仍然无法与GPT4等大模型进行抗衡,因此,会出现数学计算不准确等问题。
简而言之,就是给大模型加上“四肢“,让大模型学会使用工具,很多问题将迎刃而解。
如何进行工具调用
ChatGLM3自带了查询某地实时天气的工具,如下图所示:
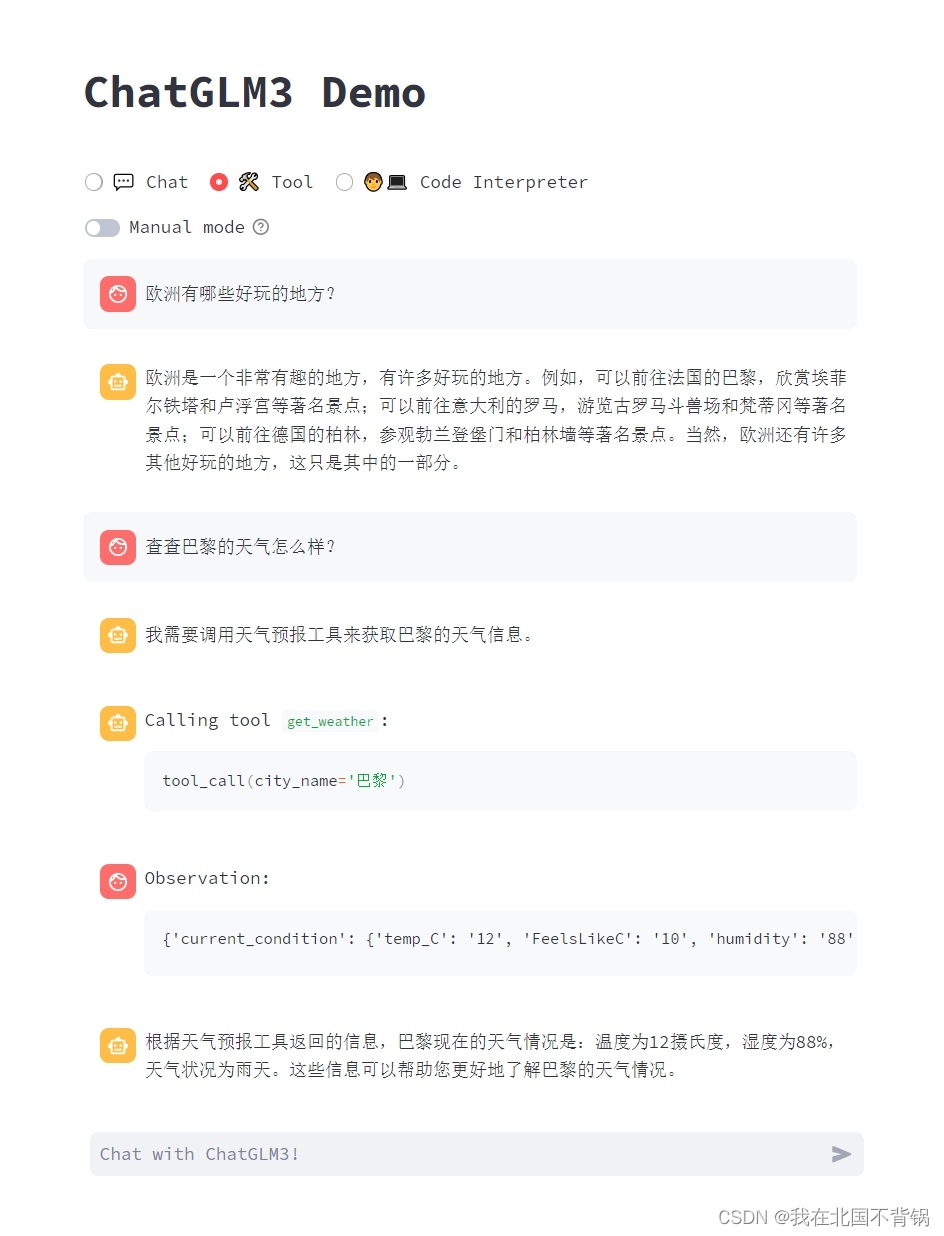
如何进行自定义工具:
(1)了解工具注册流程
在ChatGLM3项目的tool_register.py中定义了register_tool工具注册的函数,这个 Python 函数 register_tool(注册工具)的目的是将另一个函数作为参数(用 func: 可调用参数表示),注册它并收集它的元数据。感兴趣的可自行去看源码。
(2)编写自定义工具代码
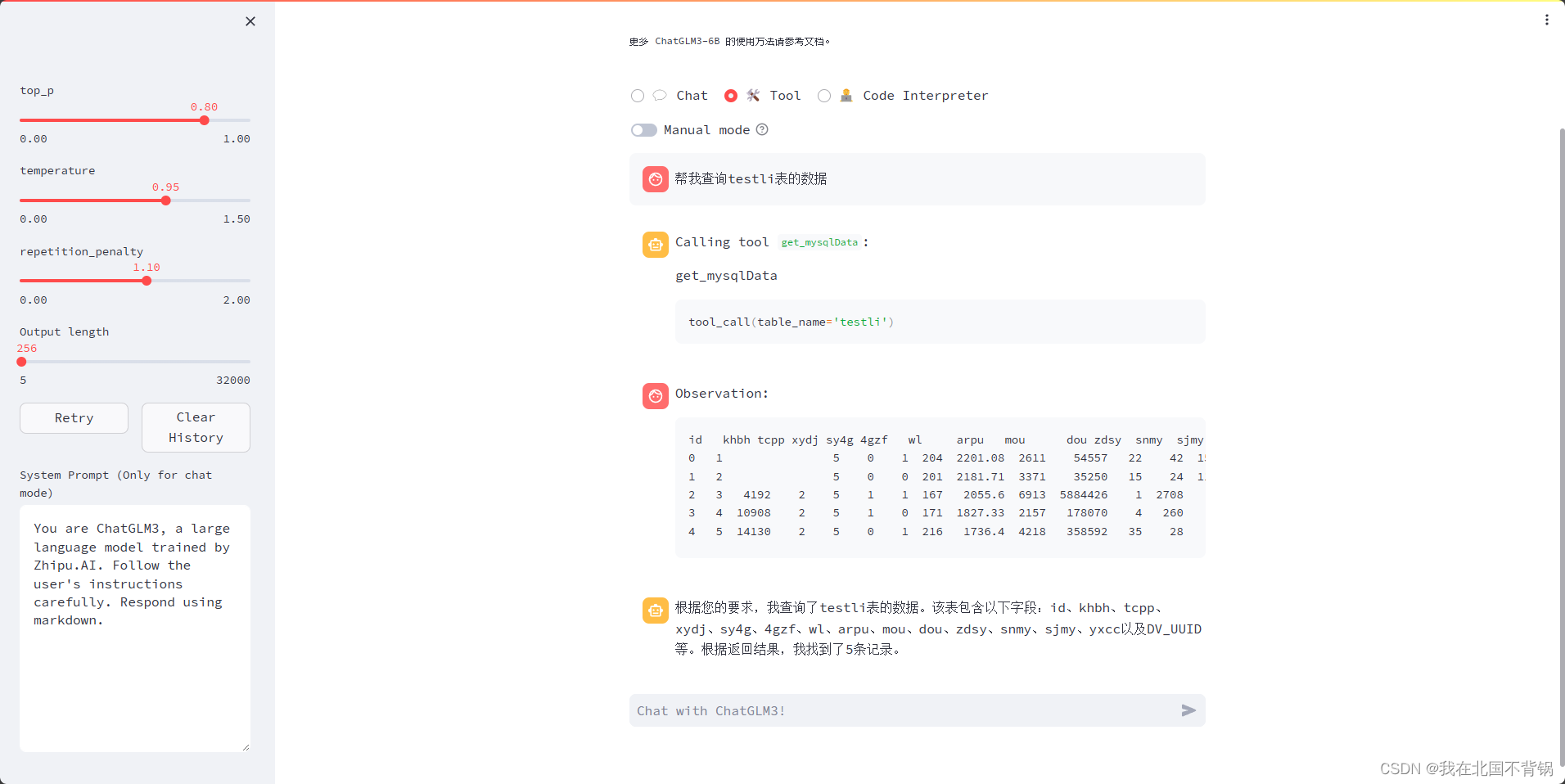
我们这里想要大模型能够返回给我一些想要看的数据库数据,代码如下:
import pymysql
import pandas as pd
def getDataFromMysql(table_name):
# 创建连接
conn = pymysql.connect(
host="10.8.xxx.xxx",
port=3306,
user='root',
passwd='123456',
db='chat',
charset='utf8mb4'
)
# 创建游标
cursor = conn.cursor()
cursor.execute("select * from "+table_name)
# 获取前n行数据
datas = cursor.fetchmany(5)
cols_info = cursor.description # 获取行相关信息
cols = [col[0] for col in cols_info] # 处理保留列名
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
df = pd.DataFrame(datas,columns=cols)
return df
@register_tool
def get_mysqlData(
table_name: Annotated[str, 'The name of the table to be queried', True],
) -> str:
"""
Get the mysql data for `table_name`
"""
data = getDataFromMysql(table_name)
return data
将以上代码全部复制到tool_registry.py中。
当然这只是很简单的查询,更多复杂的查询可根据实际需求修改;
(3)使用自定义的工具
①使用官方页面:启动问答页面:
cd composite_demo
streamlit run main.py
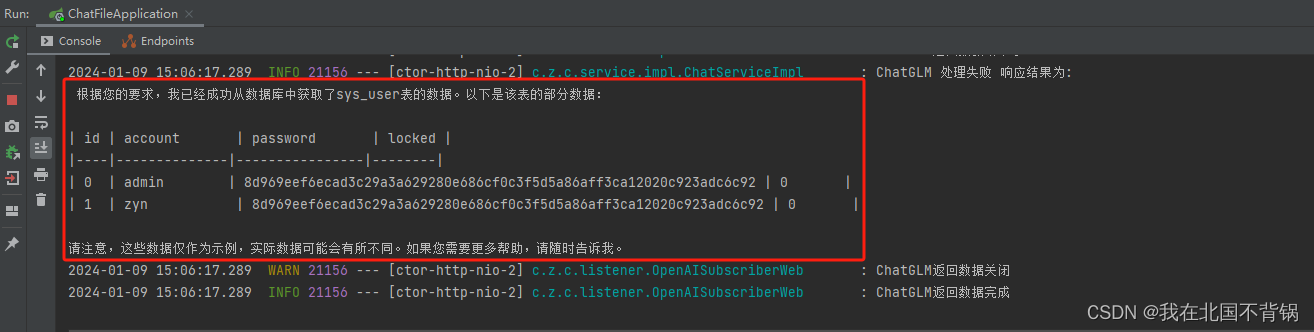
②使用api调用
官方没有给兼容openAi的接口实现,可以通过简单修改代码实现流式响应的效果:
扩展:
工具调用官方没有给兼容openAi的接口实现,可以通过简单修改openai_api_demo/openai_api_request.py代码实现,同样具备流式响应的效果:
首先,需要把tool_register.py复制到openai_api_demo目录下;
然后,修改openai_api_request.py代码:
import os
import time
from contextlib import asynccontextmanager
from typing import List, Literal, Optional, Union
import json
import torch
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from loguru import logger
from pydantic import BaseModel, Field
from sse_starlette.sse import EventSourceResponse
from transformers import AutoTokenizer, AutoModel
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
# 导入注册工具的代码
from tool_register import get_tools,dispatch_tool
# 加载所有的注册的工具
functions = get_tools()
MODEL_PATH = os.environ.get('MODEL_PATH', '/home/chatglm3-main/chatglm3-6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
@asynccontextmanager
async def lifespan(app: FastAPI): # collects GPU memory
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI(lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ModelCard(BaseModel):
id: str
object: str = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = "owner"
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = "list"
data: List[ModelCard] = []
class FunctionCallResponse(BaseModel):
name: Optional[str] = None
arguments: Optional[str] = None
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system", "function"]
content: str = None
name: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
class DeltaMessage(BaseModel):
role: Optional[Literal["user", "assistant", "system"]] = None
content: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = 0.8
top_p: Optional[float] = 0.8
max_tokens: Optional[int] = None
stream: Optional[bool] = False
functions: Optional[Union[dict, List[dict]]] = None
# Additional parameters
repetition_penalty: Optional[float] = 1.1
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal["stop", "length", "function_call"]
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: DeltaMessage
finish_reason: Optional[Literal["stop", "length", "function_call"]]
class UsageInfo(BaseModel):
prompt_tokens: int = 0
total_tokens: int = 0
completion_tokens: Optional[int] = 0
class ChatCompletionResponse(BaseModel):
model: str
object: Literal["chat.completion", "chat.completion.chunk"]
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
usage: Optional[UsageInfo] = None
@app.get("/v1/models", response_model=ModelList)
async def list_models():
model_card = ModelCard(id="chatglm3-6b")
return ModelList(data=[model_card])
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
if len(request.messages) < 1 or request.messages[-1].role == "assistant":
raise HTTPException(status_code=400, detail="Invalid request")
gen_params = dict(
messages=request.messages,
temperature=request.temperature,
top_p=request.top_p,
max_tokens=request.max_tokens or 1024,
echo=False,
stream=request.stream,
repetition_penalty=request.repetition_penalty,
# 设置functions参数
functions=functions,
)
logger.debug(f"==== request ====\n{gen_params}")
if request.stream:
# Use the stream mode to read the first few characters, if it is not a function call, direct stram output
predict_stream_generator = predict_stream(request.model, gen_params)
output = next(predict_stream_generator)
if not contains_custom_function(output):
return EventSourceResponse(predict_stream_generator, media_type="text/event-stream")
# Obtain the result directly at one time and determine whether tools needs to be called.
logger.debug(f"First result output:\n{output}")
function_call = None
# 修改为functions
if output and functions:
try:
function_call = process_response(output, use_tool=True)
except:
logger.warning("Failed to parse tool call")
# CallFunction
if isinstance(function_call, dict):
function_call = FunctionCallResponse(**function_call)
"""
In this demo, we did not register any tools.
You can use the tools that have been implemented in our `tool_using` and implement your own streaming tool implementation here.
Similar to the following method:
function_args = json.loads(function_call.arguments)
tool_response = dispatch_tool(tool_name: str, tool_params: dict)
"""
function_args = json.loads(function_call.arguments)
tool_response = dispatch_tool(function_call.name, function_args)
if not gen_params.get("messages"):
gen_params["messages"] = []
gen_params["messages"].append(ChatMessage(
role="assistant",
content=output,
))
gen_params["messages"].append(ChatMessage(
role="function",
name=function_call.name,
content=tool_response,
))
# Streaming output of results after function calls
generate = predict(request.model, gen_params)
return EventSourceResponse(generate, media_type="text/event-stream")
else:
# Handled to avoid exceptions in the above parsing function process.
generate = parse_output_text(request.model, output)
return EventSourceResponse(generate, media_type="text/event-stream")
# Here is the handling of stream = False
response = generate_chatglm3(model, tokenizer, gen_params)
# Remove the first newline character
if response["text"].startswith("\n"):
response["text"] = response["text"][1:]
response["text"] = response["text"].strip()
usage = UsageInfo()
function_call, finish_reason = None, "stop"
# 修改为functions
if functions:
try:
function_call = process_response(response["text"], use_tool=True)
except:
logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.")
if isinstance(function_call, dict) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









