







 文章介绍了Qwen1.5-72B-Chat_GGUF模型提供的8种不同量化变体,包括Q5_K_M和Q4_K_M,它们在精度、资源使用和速度上有所权衡。推荐使用Q5_K_M以保持大部分性能,或根据内存需求选择Q4_K_M。
文章介绍了Qwen1.5-72B-Chat_GGUF模型提供的8种不同量化变体,包括Q5_K_M和Q4_K_M,它们在精度、资源使用和速度上有所权衡。推荐使用Q5_K_M以保持大部分性能,或根据内存需求选择Q4_K_M。
在下载Qwen1.5-72B-Chat_GGUF模型时,发现其提供了8种不同的 GGUF模型。它们遵循特定的命名约定:“q”+ 用于存储权重的位数(精度)+ 特定变体。
下图是为了证明不同的模型质量,按照 llama.cpp 在wiki测试集上评估他们的困惑度。结果如下:
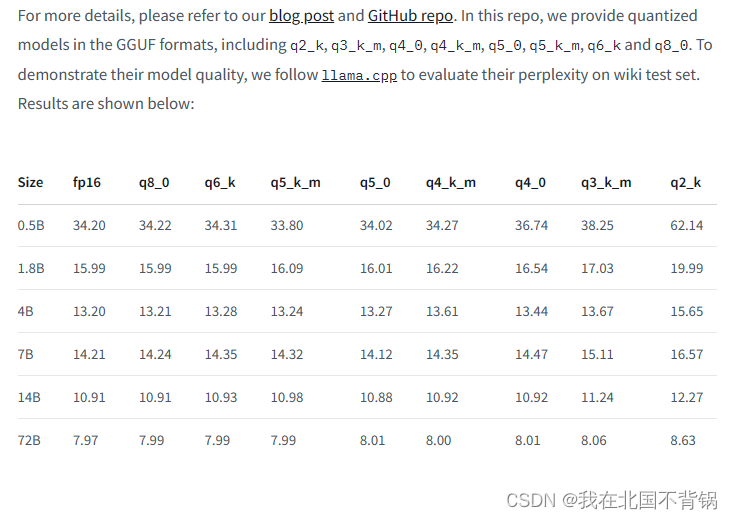
q8_0:与浮点数16几乎无法区分。资源使用率高,速度慢。不建议大多数用户使用。
q6_k:将Q8_K用于所有张量。
q5_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q5_K。
q5_0: 原始量化方法,5位。精度更高,资源使用率更高,推理速度更慢。
q4_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q4_K
q4_0:原始量化方法,4 位。
q3_k_m:将 Q4_K 用于 attention.wv、attention.wo 和 feed_forward.w2 张量,否则Q3_K
q2_k:将 Q4_K 用于 attention.vw 和 feed_forward.w2 张量,Q2_K用于其他张量。
根据经验,建议使用 Q5_K_M,因为它保留了模型的大部分性能。或者,如果要节省一些内存,可以使用 Q4_K_M。

















 2287
2287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









