







强力推荐:https://github.com/langgenius/dify/releases
这也是我自己跟着学的,来源:
https://www.bilibili.com/video/BV1SHwCevEqv/?spm_id_from=333.1387.collection.video_card.click&vd_source=c47fbb8166930edc486d8fdc405bf569
以下是我自己的笔记
文章目录
使用指南
1、下载文件夹Excel_Flask_Dify到本地任意目录;
2、在Excel_Flask_Dify文件夹上右键单击,选择“服务——新建位于文件夹位置的终端窗口“;
3、在打开的终端命令窗口输入命令:cd Excel_flask_Service;然后执行启动flask服务命令:python3 Excel_flask_Service.py
4、运行dify,在dify中导入 “Dify AI应用:Excel_Flask_Dify.yml” DSL文件,根据flask服务生成的链接地址对应修改http请求节点;然后执行即可。
首先安装环境
我差一个pandas环境
所以安装了
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
问题1:logging.basicConfig(level=logging.DEBUG) 怎么用?
参考文章
https://blog.csdn.net/colinlee19860724/article/details/90965100
我大致了解就是说多线程的时候print他可能截断,这个Logger就不容易截断
但是我怎么看这个logg呢?
logging.info(‘这是⼀个info级别的⽇志信息’)
看流程
LLM
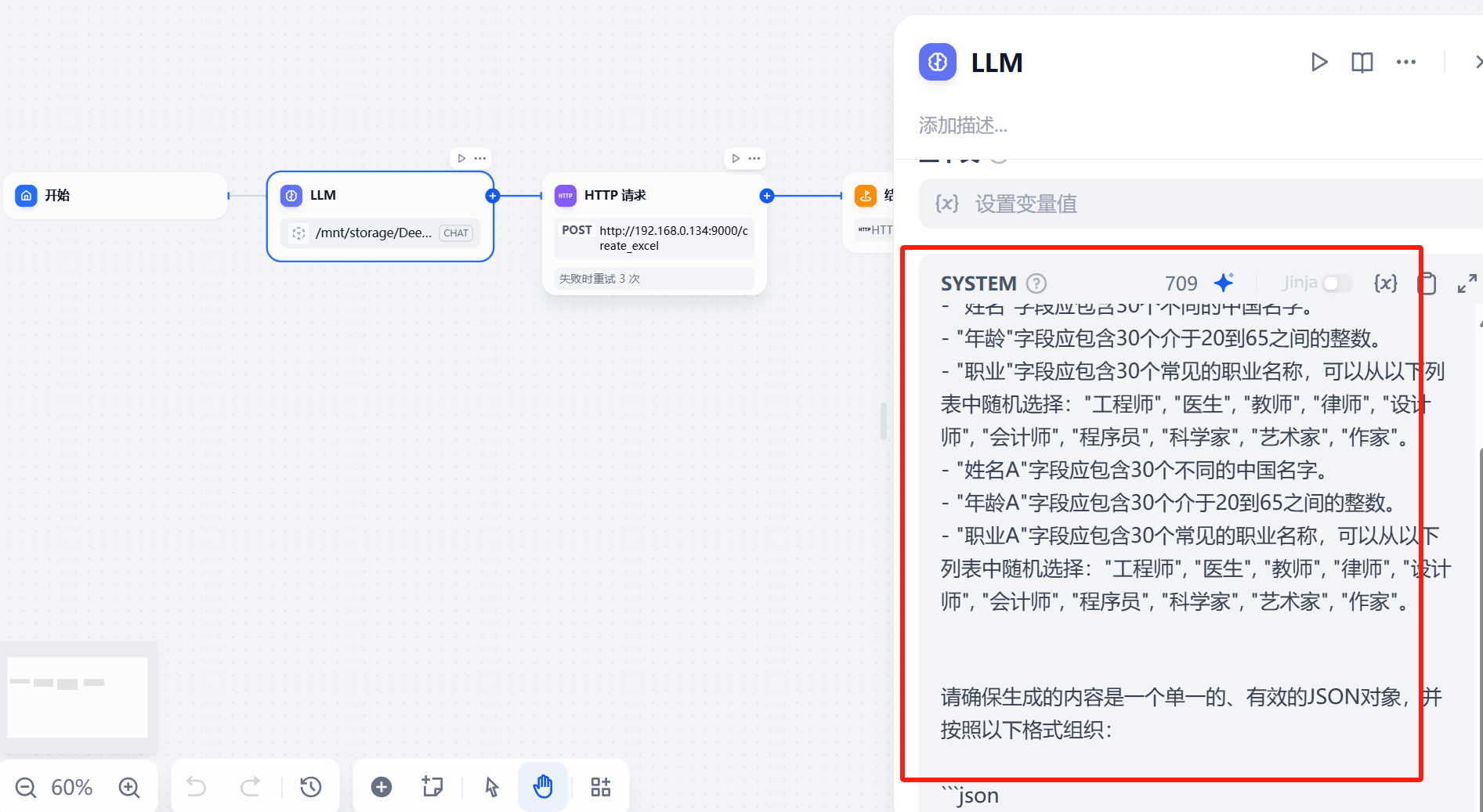
首先就是定义嘛,说有多少个条目,之后每个条目有多少个字段
记住:条目和字段!!
之后说具体的要求
最后给一个格式案例
请根据以下描述生成一个包含30个条目的JSON对象,每个条目有六个字段:"姓名"、"年龄"、"职业"、"姓名A"、"年龄A"和"职业A"。具体要求如下:
- "姓名"字段应包含30个不同的中国名字。
- "年龄"字段应包含30个介于20到65之间的整数。
- "职业"字段应包含30个常见的职业名称,可以从以下列表中随机选择:"工程师", "医生", "教师", "律师", "设计师", "会计师", "程序员", "科学家", "艺术家", "作家"。
- "姓名A"字段应包含30个不同的中国名字。
- "年龄A"字段应包含30个介于20到65之间的整数。
- "职业A"字段应包含30个常见的职业名称,可以从以下列表中随机选择:"工程师", "医生", "教师", "律师", "设计师", "会计师", "程序员", "科学家", "艺术家", "作家"。
请确保生成的内容是一个单一的、有效的JSON对象,并按照以下格式组织:
```json
{
"姓名": ["张三", "李四", "王五", ...], // 30个不同的中国名字
"年龄": [23, 34, 45, ...], // 30个介于20到65之间的整数
"职业": ["工程师", "医生", "教师", ...], // 30个常见的职业名称
"姓名A": ["张三", "李四", "王五", ...], // 30个不同的中国名字
"年龄A": [23, 34, 45, ...], // 30个介于20到65之间的整数
"职业A": ["工程师", "医生",  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2398
2398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











