






目录
发表于AAAI2021 翻译版
太长不看版本:
1.摘要
在本文中,我们顺应趋势提出了一种新的方法,利用鉴别器注意和自我训练策略来减少域偏移。鉴别器注意策略包含两个阶段的对抗性学习过程,它明确区分对齐良好(领域不变)和对齐不良(领域特定)特征,并引导模型关注后者。自训练策略自适应地改进了模型针对目标域的决策边界,隐式地促进了域不变特征的提取。通过结合两种策略,我们找到了一种更有效的方法来减少域移。大量的实验证明了该方法在众多基准数据集上的有效性。
2.引言
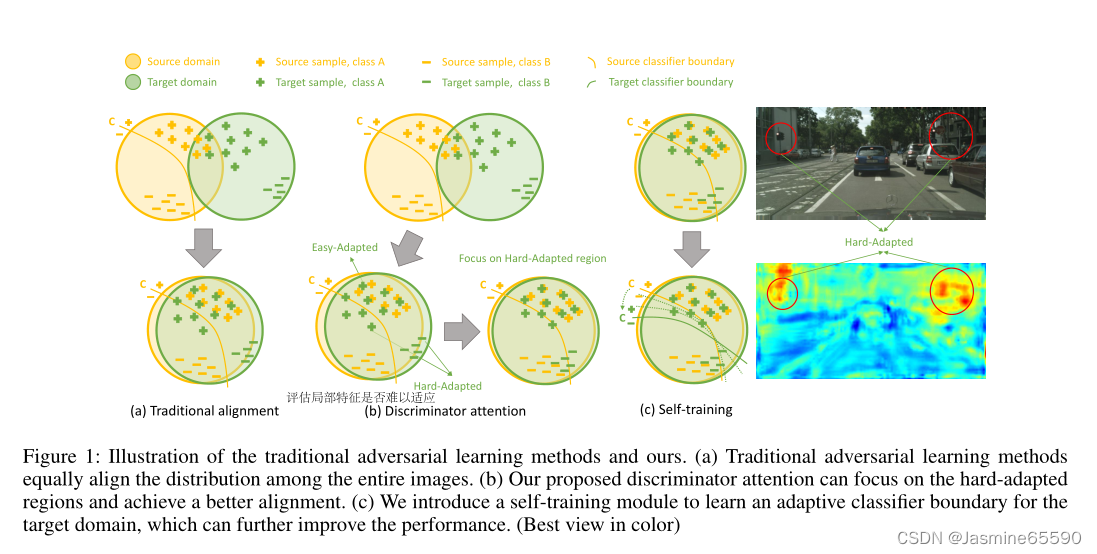
使用UDA方法进行语义分割的关键部分是对齐来自不同领域的特征(Chen et al. 2019;Hoffman等人,2018;Tsai等,2018;Vu et al. 2019)。虽然其主要思想很简单——匹配源和目标域的整体特征级分布,但实现的难度因适应图像中不同区域的特征而异。例如天空比建筑、交通灯和人行道更容易适应,因为天空的区域无论从图像上看都是相似的,而后者的特征是不同的建筑风格或交通规则。(Luo et al. 2019b)认为,对源域和目标域进行全局对齐会导致信息负转移,并破坏模型在原本对齐良好的区域的性能。因此,他们建议生成一个局部比对分数图,并允许对具有不同局部比对分数的区域使用不同的权重。
遵循(Luo et al. 2019b)的精神,在这项工作中,我们提出了一种称为鉴别器注意(DA)的策略,以直接评估局部特征是否难以适应。提出的DA学习策略包括发现和纠正两个阶段。在发现阶段,鉴别器网络(也称为发现器,D)对分割网络的中间特征进行对齐,并使用局部对齐的置信度形成一个注意图,对特征图进行重权,用于标签预测。在校正阶段,另一个鉴别器网络(称为corrector, C)根据之前的注意图进一步对齐分割网络的输出。如图1 (b)所示,该模型更关注用于领域对齐的难适应区域。考虑到真实数据(目标域)的分布过于复杂,我们进一步引入自训练策略,以保证模型的决策边界适合于目标域。如图1 (c)所示,经过UDA处理后的分割网络的决策边界仍然倾向于源域数据的分布,但应用自训练策略后,这种趋势得到了纠正。具体来说,我们通过使用先前预测生成的伪标签训练分割网络,自适应地改进模型的决策边界。
贡献点:
(1)我们提出了一种新型的两阶段对抗学习(DA),利用注意机制为难以适应的区域赋予更高的权重,并同时对齐特征空间和输出空间。
(2)我们的方法是对现有领域适应技术的补充,如自我训练。
(3)我们的方法在SYNTHIA (Ros等人2016年)/GTA5 (Richter等人2016年)数据集到真实数据集Cityscapes (Cordts等人2016年)的适应性上取得了卓越的性能。
3.相关工作
略。
4.方法
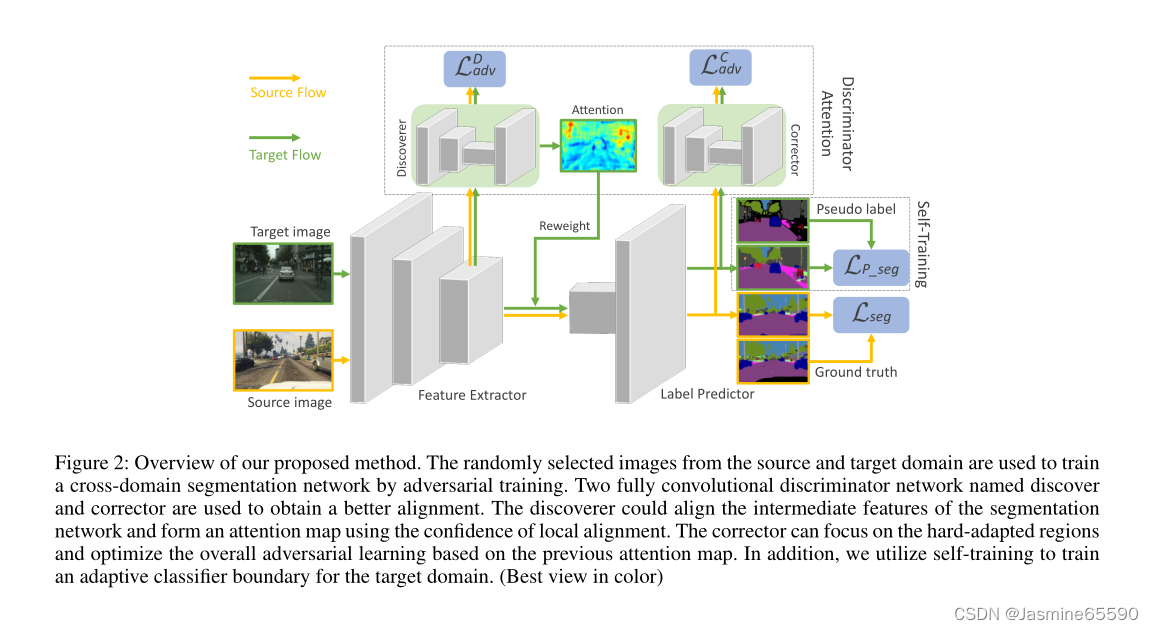
在这项工作中,我们专注于语义分割的无监督域适应问题,我们可以访问有标记的源数据集{xs, ys}和无标记的目标数据集{xt}。如图2所示,整个网络架构主要由一个分割网络(segmentor S)和两个鉴别器网络(discoverer D和corrector C)组成。segmentor S的网络骨干可以是任何用于语义分割的全卷积网络。为了更好的描述和讨论,S分为特征提取器E和标签预测器P,其中S = E◦P。discriminator (D和C)是基于cnn的分类器,具有完全卷积输出,可以为所有输出位置提供置信度得分,以评估不同域的局部对齐。
在源流中,E从源域图像xs中提取一个特征映射fs,其中fs = E(xs)。然后,预测器P将fs作为输入,形成像素级语义分割ps,其中ps = P (fs),它将在源标签ys的监督下用于计算分割损失Lseg。另一方面,fs和ps将分别输入到特征级和输出级对抗学习的发现器D和校正器C中。
在目标流中,对于给定的图像xt, E输出一个feature map ft,它首先输入到发现器D。通过优化对抗性损失LDadv, D对齐ft和fs的特征分布,并提供ft中每个位置对齐的置信度得分,形成注意图α,其中α = |(D(ft)|。α将ft重新加权到一个新的特征映射ˆft = α(ft),它被输入到P以产生像素级的预测pt,更关注对齐不好的区域,其中pt = P(ˆft)。然后引入校正器C在pt和ps之间进行对抗性学习。为了进一步增强差对齐区域的适应性,我们使用注意图α对对抗性损失LCadv进行重新加权。
此外,我们采用一种自训练策略来改进分割模型的决策边界。类似于(Li, Y yuan, and V asconcelos 2019),我们引入了像素部分的超级参数q。我们利用pt中像素的顶部q值生成概率值较高的伪标签ˆpt,并屏蔽掉其他不参与梯度反向传播的像素。
算法1总结了该方法的训练过程。在实践中,我们将初始q设为50%,自训练的最大迭代K设为3(性能收敛)。

损失函数:
整体损失函数主要由四个损失项组成:

第二项和第三项分别是发现者D和纠正者C的对抗性损失。在LSGAN之后(Mao et al. 2017),我们使用最小二乘损失来取代GAN中的sigmoid交叉熵,因为基于sigmoid的损失通常在鉴别器达到最优时停止更新(Hong et al. 2019)。LDadv(E, D)和LCadv(E, P, C)分别对应鉴别器注意模块中的两阶段对抗性学习。
在第一阶段,E提取的域不变特征会迷惑发现者D,目的是通过交替优化D和E来最小化损失LDadv(E, D)。
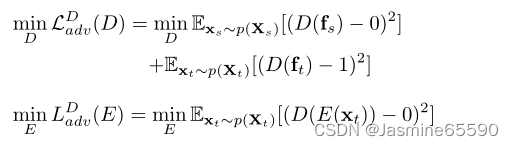
优化D后,对于给定的目标图像xt,生成区分易适应区域和难适应区域的注意图,α = |D(ft)|。在第二阶段,我们预计P◦E输出分割预测,能够混淆C。
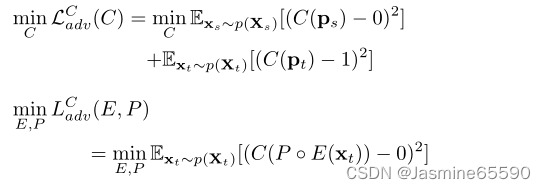
第四个损失项与自我训练策略有关,它自适应地改善分段器S (S = P◦E)的决策边界,以适应目标分布。
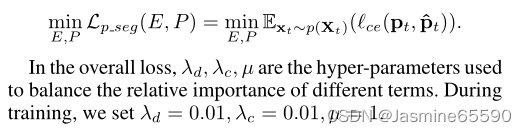
在整体损失中,λd、λc、μ是用来平衡各项相对重要性的超参数。在训练时,我们设置λd = 0.01, λc = 0.01,µ= 1。
注意机制设计:
对于目标图像特征ft,发现器α = |D(ft)|的置信度得分显示ft是否局部匹配fs的分布。低αij表示xt中对齐良好的区域,高αij表示对齐不良的区域。因此,我们使用α作为ft的注意图,以鼓励模型专注于那些对齐较差区域的特征匹配。此外,为了防止实验初期的梯度爆炸,我们在α中加入tanh活化作为归一化层。最后,我们展开tanh(α)来拟合ft的维数,用于后续的元素乘法:

由于tanh(α)的大小小于1,其梯度可能会在训练过程的后期消失。因此,我们采用剩余注意机制(Wang et al. 2017)来计算新的特征图。
5.训练结果
我们采用了DeepLab (Chen et al. 2017)框架,其中VGG16 (Simonyan和Zisserman 2014)和ResNet-101(He et al. 2016)骨干网作为我们的分割网络。在ImageNet上预训练初始权重(Deng et al. 2009)。在最后一层卷积之后,应用Atrous空间金字塔池(ASPP)模块,采样率为{6,12,18,24}。最后,我们利用上采样层来重新缩放最终分割输出,以匹配输入图像的尺寸。鉴别器(发现器D和校正器C)是保留空间信息的完全卷积网络。D由4个卷积层组成,通道号为{256,128,64,1},kernel size为3,padding size为1,stride为1。C对齐不同域的语义预测。随后(Tsai et al. 2018),它由5个卷积层组成,内核大小、填充大小和步长分别为4、1、2,通道号为{64、128、256、512、1}。与常规的ReLU不同,C使用Leaky ReLU作为激活,其负斜率固定为0.2。
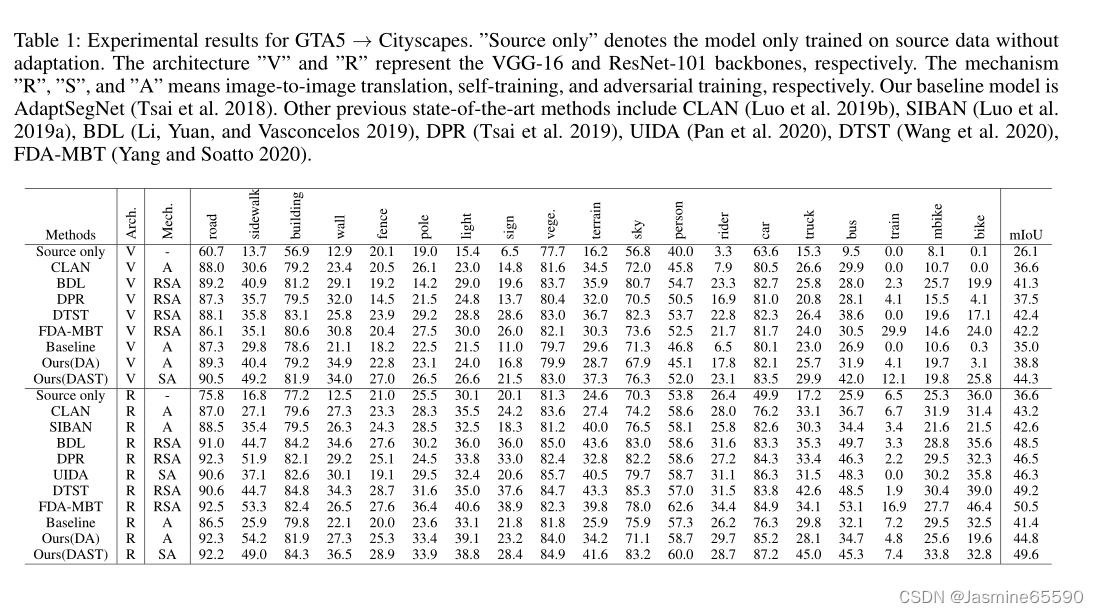
GTA5->CITYSCAPES
SYNTHIA->CITYSCAPES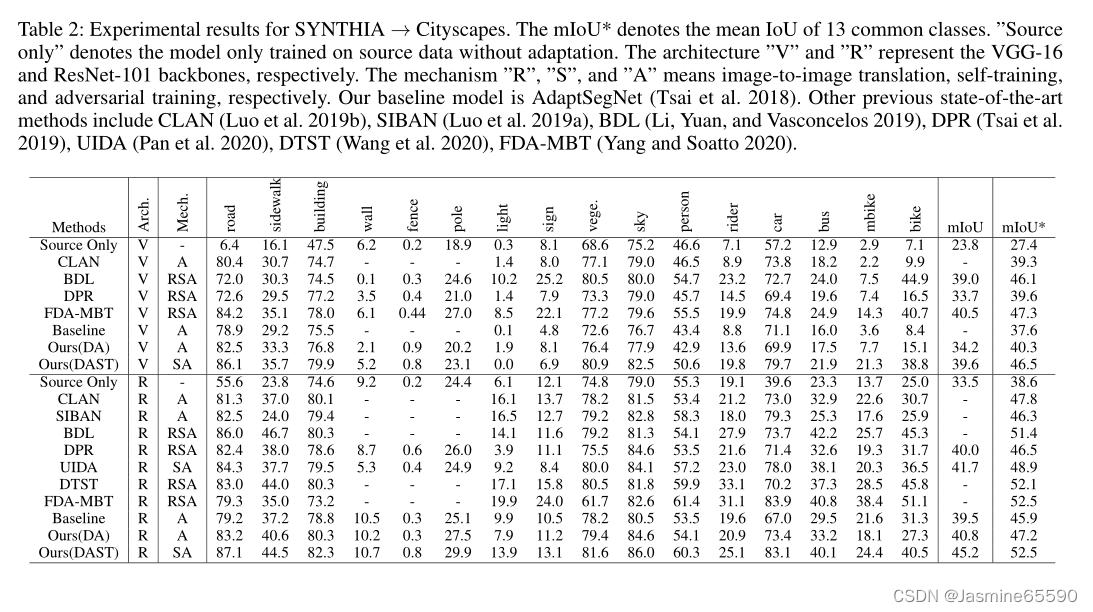
之前的大多数研究都存在模型偏差和估计过于乐观的问题,因为它们通常会从Cityscapes值集中所有中间快照的评估中选择最好的结果。为了解决过度乐观的问题,我们通过(Y ang和Soatto 2020)的方法,随机选取500张转换为cityscape风格的GTA5图像,建立一个合成值集。模型在合成val集合上的性能可以指导最佳快照的选择和何时开始自我训练。我们使用两种样式的平均值(β = 0.5和β = 0.9)作为合成val集的最终结果。如图4所示,合成的值集可以近似地适合Cityscapes VAL集。
6.结论
本文提出了一种将识别器注意力与自训练相结合的新方法,实现了无监督域自适应语义分割。鉴别器注意模块包括对抗性学习的两个阶段,利用注意图为硬适应区域赋予更高的权重,并在不同区域之间进行特征级和输出级比对。自训练模块动态生成伪标签,使分割网络的决策边界适应未标记目标图像的分布。实验结果和定性实例证明,我们的方法在基准数据集上的性能优于现有的先进方法。















 3076
3076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









