




|
日期 |
2022/11/16 |
|
论文名称 |
Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medical image segmentation 统一焦点损失:泛化骰子和基于交叉熵的损失处理类别不均衡医学图像分割 |
|
论文来源 |
Yeung M, Sala E, Schönlieb C B, et al. Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medical image segmentation[J]. Computerized Medical Imaging and Graphics, 2022, 95: 102026.【2区】 |
|
其他说明 |
针对医学数据集中存在的类别不均衡问题,提出统一焦点损失函数 |
2.1 Cross entropy loss
2.1.1 BCE原理及pytorch版代码
根据信息论的起源,交叉熵测量了一个给定的随机变量或一组事件的两个概率分布之间的差异。作为一个损失函数,它表面上等价于负对数似然损失,对于二分类,可以用如下二元交叉熵损失(binary cross entropy loss (BCE) 定义:
(1)
其中y',y属于,y'是输入的预测值,y是相应的真实值.
pytorch版代码
pytorch已经内置了BCE源码,可查询使用
import torch.nn as nn
loss_BCE = nn.BCELoss()
2.1.2 CCE原理及pytorch版代码
同理,可以延伸至多分类,其损失函数可定义为:
(2)
其中使用ground真值标签的one-hot编码方案,
是每个类的预测值矩阵,其中索引c和i分别迭代所有类和像素。交叉熵损失是基于最小化像素级误差,在类不平衡的情况下,导致损失中较大对象的过度表示,导致较小对象的分割质量较差。
pytorch版代码
多分类代码待补充
2.2 Focal loss
2.2.1 二元分割Focal loss原理及pytorch版代码
焦点损失是二元交叉熵损失的一种变体,它通过降低简单样本贡献的权重,解决了与标准的交叉熵损失之间的类不平衡的问题(Lin et al.,2017)。为了推导出焦点损失函数,首先简化公式1中的损失:
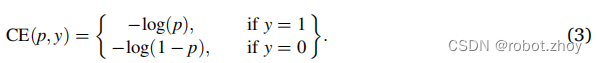
进而,将预测ground真实类pt的概率定义为:

则,二元交叉熵损失可以改写为:

需注意Focal Loss为二元交叉熵损失增加了一组调制系数:
![]()
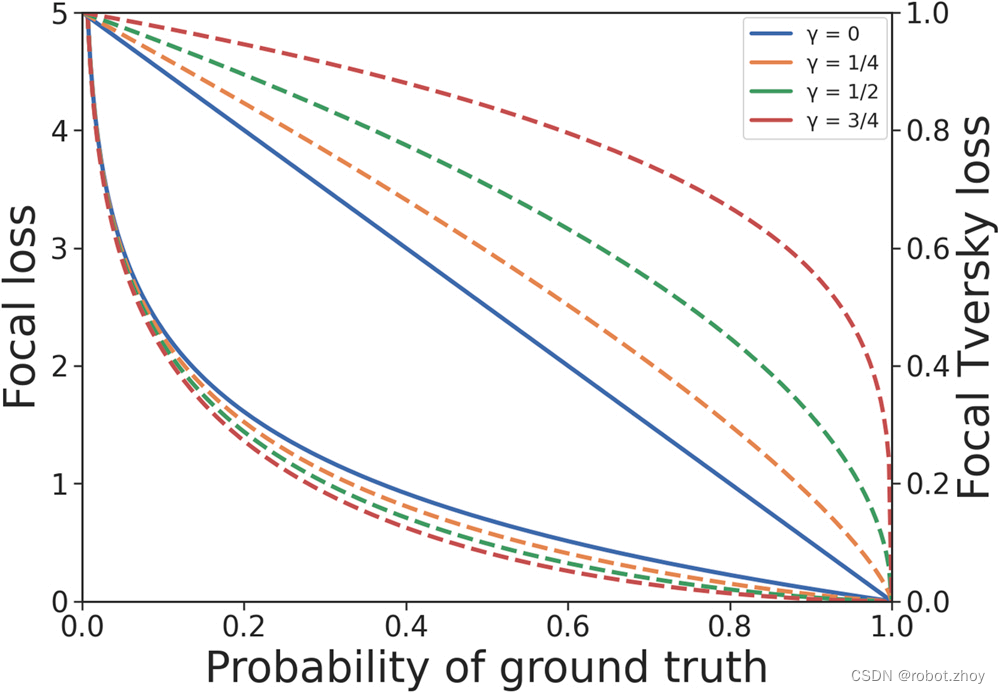
Focal Loss由α和γ参数化,它们分别控制易于分类的像素的类权重和权重下降程度(图2)。当γ=为0时,Focal Loss简化为二元交叉熵损失。
pytorch版代码(已验证):
class FocalLoss(nn.Module):
'''
Focal loss is used to address the issue of the class imbalance problem. A modulation term applied to the Cross-Entropy loss function.
Parameters
----------
alpha : float, optional
controls relative weight of false positives and false negatives. alpha > 0.5 penalises false negatives more than false positives, by default None
gamma_f : float, optional
focal parameter controls degree of down-weighting of easy examples, by default 2.
'''
# https://github.com/CoinCheung/pytorch-loss/blob/master/focal_loss.py
def __init__(self, alpha=0.25, gamma=2,reduction='mean',):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
self.crit = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, y_true, y_pred):
'''
Usage is same as nn.BCEWithLogits:
>>> criteria = FocalLossV1()
>>> y_true = torch.randn(8, 19, 384, 384)
>>> lbs = torch.randint(0, 2, (8, 19, 384, 384)).float()
>>> loss = criteria(logits, lbs)
'''
probs = y_pred
# coeff = |y_true - y_pred|^ gamma
coeff = torch.abs(y_true - probs).pow(self.gamma).neg()
# torch.where()函数的作用是按照一定的规则合并两个tensor类型。torch.where(condition,a,b)
# 其中输入参数condition:条件限制,如果满足条件,则选择a,否则选择b作为输出。
#使用softplus近似求log(y_pred)
log_probs = torch.where(y_pred >= 0, F.softplus(y_pred, -1, 50), y_pred - F.softplus(y_pred, 1, 50)) #softplus函数是relu函数的平滑版本
#使用softplus近似求log(1-y_pred)
log_1_probs = torch.where(y_pred >= 0, -y_pred + F.softplus(y_pred, -1, 50), -F.softplus(y_pred, 1, 50)) # https://pytorch.org/docs/stable/generated/torch.nn.Softplus.html
# 等价于求二元交叉熵损失(待参数alpha) L = y_true * alpha * log(y_pred) + (1-y_true) * (1-alpha) * log(1- y_pred)
loss = y_true * self.alpha * log_probs + (1. - y_true) * (1. - self.alpha) * log_1_probs
loss = loss * coeff
if self.reduction == 'mean':
loss = loss.mean()
if self.reduction == 'sum':
loss = loss.sum()
return loss
2.2.2 多元分割Focal loss原理及pytorch代码
同理,可延伸至多分类语义分割,其公式为:
![]()
其中使用ground真值标签的one-hot编码方案,
是每个类的预测值矩阵,其中索引c和i分别迭代所有类和像素。
其中α是类权值的向量,是每个类所预测的概率矩阵,注意one-hot编码格式.
pytorch版代码
多分类代码待补充
2.3 Dice loss
2.3.1 二元分割Dice loss原理及pytorch代码
Sørensen-Dice指数,当应用于布尔数据时,被称为Dice相似度系数(DSC),是评估分割精度最常用的度量指标。我们可以根据每个像素的真阳性(TP)、假阳性(FP)和假阴性(FN)的分类来定义DSC:
![]()
因此Dice loss可以定义如下:
![]()
即使在最简单的公式中,骰子损失在某种程度上适合处理类不平衡。然而,骰子损失梯度本质上是不稳定的,最明显的是高度类不平衡的数据,其中梯度计算涉及较小的分母(Wong等人,2018;Bertels等人,2019年)。
pytorch版代码(已验证):
class BinaryDiceLoss(nn.Module):
def __init__(self):
super(BinaryDiceLoss, self).__init__()
def forward(self, input, targets):
# 获取每个批次的大小 N
N = targets.size()[0]
# 平滑变量
smooth = 1
# 将宽高 reshape 到同一纬度
input_flat = input.view(N, -1)
targets_flat = targets.view(N, -1)
# 计算交集
intersection = input_flat * targets_flat
N_dice_eff = (2 * intersection.sum(1) + smooth) / (input_flat.sum(1) + targets_flat.sum(1) + smooth)
# 计算一个批次中平均每张图的损失
loss = 1 - N_dice_eff.sum() / N
return loss
2.3.2 多元分割Dice loss 的pytorch代码
pytorch版代码(待验证):
class MultiClassDiceLoss(nn.Module):
def __init__(self, weight=None, ignore_index=None, **kwargs):
super(MultiClassDiceLoss, self).__init__()
self.weight = weight
self.ignore_index = ignore_index
self.kwargs = kwargs
def forward(self, input, target):
"""
input tesor of shape = (N, C, H, W)
target tensor of shape = (N, H, W)
"""
# 先将 target 进行 one-hot 处理,转换为 (N, C, H, W)
nclass = input.shape[1]
target = one_hot(target.long(), nclass)
assert input.shape == target.shape, "predict & target shape do not match"
binaryDiceLoss = BinaryDiceLoss()
total_loss = 0
# 归一化输出
logits = F.softmax(input, dim=1)
C = target.shape[1]
# 遍历 channel,得到每个类别的二分类 DiceLoss
for i in range(C):
dice_loss = binaryDiceLoss(logits[:, i], target[:, i])
total_loss += dice_loss
# 每个类别的平均 dice_loss
return total_loss / C
2.4 Tversky loss原理及pytorch代码
Tversky指数(Salehi et al.,2017)与DSC密切相关,但通过将假阳性和假阴性分别分配权重α和β,可以优化输出不平衡:
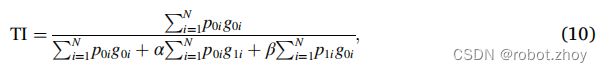
其中,为像素i属于前景类的概率,
为像素属于背景类的概率。
取1为前景,取0为背景,相反地,
取1为背景,取0为前景。
使用Tversky索引,可将C类的Tversky loss定义为:

当Dice loss函数应用于类不平衡问题时,结果分割往往显示出高精度但低召回率分数(Salehi et al.,2017)。给假阴性赋予更大的权重可以提高查全率,从而提高精度和查全率的平衡。因此,β通常设置得高于α,最常见的是β = 0.7和α = 0.3。
非对称相似性损失来自于Tversky loss,但使用评分和α代替
,β代替
,增加了α和β必须和为1的约束(Hashemi等人,2018)。在实践中,选择Tversky loss的α和β值,使它们之和为1,使这两个损失函数在功能上等价。
pytorch版代码(已验证):
#!###############################
#! Tversky Loss #
#!###############################
class TverskyLoss(nn.Module):
'''
Tversky loss function for image segmentation using 3D fully convolutional deep networks
Link: https://arxiv.org/abs/1706.05721
Parameters
----------
delta : float, optional
controls weight given to false positive and false negatives, by default 0.7
smooth : float, optional
smoothing constant to prevent division by zero errors, by default 0.000001
'''
def __init__(self, weight=None, size_average=True):
super(TverskyLoss, self).__init__()
def forward(self, inputs, targets, smooth=1, alpha=0.5, beta=0.5):
#comment out if your model contains a sigmoid or equivalent activation layer
#inputs = F.sigmoid(inputs)
#flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
#True Positives, False Positives & False Negatives
TP = (inputs * targets).sum()
FP = ((1-targets) * inputs).sum()
FN = (targets * (1-inputs)).sum()
Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth)
return 1 - Tversky
2.5 Focal Tversky loss原理及pytorch代码
受交叉熵损失的Focal loss自适应的启发,Focal Tversky loss(Abraham and Khan, 2019) 通过应用一个焦点参数来适应Tversky loss 。
可沿用公式10中的TI定义Focal Tversky loss:

其中,γ < 1增加了对更hard examples的关注程度。当γ = 1时,Focal Tversky loss简化为Tversky loss。然而,与Focal loss相反的是,经验的最佳值是γ=4∕3,它增强而不是抑制了easy examples的损失。事实上,在训练接近结束时,大多数例子被更高置信度分类,Tversky指数接近1,增强该区域的损失保持更高的损失,这可能会防止过早收敛到次优解。
pytorch版代码(已验证):
#!###############################
#! Focal Tversky Loss #
#!###############################
class FocalTverskyLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(FocalTverskyLoss, self).__init__()
def forward(self, inputs, targets, smooth=1, alpha=0.3, beta=0.7, gamma=0.75):
#comment out if your model contains a sigmoid or equivalent activation layer
#inputs = F.sigmoid(inputs)
#flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
#True Positives, False Positives & False Negatives
TP = (inputs * targets).sum()
FP = ((1-targets) * inputs).sum()
FN = (targets * (1-inputs)).sum()
Tversky = (TP + smooth) / (TP + alpha*FP + beta*FN + smooth)
FocalTversky = (1 - Tversky)**gamma
return FocalTversky
2.6. Combo loss原理及pytorch代码
组合损失(Taghanaki et al.,2019)属于复合损失类,其中多个损失函数一致地最小化。组合损失被定义为等式中DSC的加权(公式8)和交叉熵损失的一种改进形式:
![]()
其中
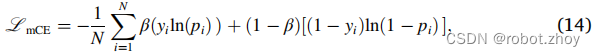
和α∈[0,1]控制骰子项和交叉熵项对损失的相对贡献,而β控制分配给假阳性和阴性的相对权重。β>0.5对假阴性预测的惩罚大于假阳性。
令人困惑的是,术语“骰子和交叉熵损失”被用来指交叉熵损失和DSC的和(Taghanaki等人,2019;Isensee等人,2018),以及交叉熵损失和骰子损失的总和,如双焦点损失和骰子和加权交叉熵损失(Zhu等人,2019b;Chen等人,2019)。在本文,决定使用前一个定义,这与最先进的KiTS19数据集中使用的组合损失和损失函数相一致(Isensee等人,2018)。
class ComboLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(ComboLoss, self).__init__()
def forward(self, inputs, targets, smooth=1, alpha=0.5, beta=0.5, eps=1e-9):
ALPHA = alpha
CE_RATIO = beta
#flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
#True Positives, False Positives & False Negatives
intersection = (inputs * targets).sum()
dice = (2. * intersection + smooth) / (inputs.sum() + targets.sum() + smooth)
inputs = torch.clamp(inputs, eps, 1.0 - eps)
out = - (ALPHA * ((targets * torch.log(inputs)) + ((1 - ALPHA) * (1.0 - targets) * torch.log(1.0 - inputs))))
weighted_ce = out.mean(-1)
combo = (CE_RATIO * weighted_ce) - ((1 - CE_RATIO) * dice)
return combo
2.7. Hybrid Focal loss
Combo loss(Taghanaki et al., 2019) 和Dice Focal loss(Zhu et al., 2019b) 是两个复合损失函数,它们继承了来自Dice loss和基于交叉熵的损失函数的优点。然而,两者都没有在类别不均衡的背景下充分利用全部优点。Combo loss和Dice Focal loss的可调系数β和α对输出不平衡具有部分鲁棒性。然而,两者都缺乏同等的骰子组件的损失,其中正样本和负样本仍然保持相等的权重。同样地,两种损失的Dice分量都不适合于处理输入不平衡,尽管Dice Focal loss更适合于Focal loss分量中的焦点参数。
为了克服这一问题,之前提出了Hybrid Focal loss函数,它包含了可调参数来处理输出不平衡,以及处理输入不平衡的焦点参数,包括基于Dice 和交叉熵的分量损失(Yeung et al., 2021)。通过用Focal Tversky loss代替Dice loss,用Focal loss代替交叉熵损失,故可将Hybrid Focal loss定义为:
![]()
其中,λ∈[0,1],并确定两个分量损失函数的相对权重。
2.8. Unified Focal loss
2.8.1 对称性Unified Focal loss 原理及pytorch版代码
Hybrid Focal loss适应了基于Dice和交叉熵的损失来处理类别不均衡。然而,在实践中使用Hybrid Focal loss有两个主要问题。
(1) 有6个超参数需要调整:Focal loss的α和γ,Focal Tversky loss的α/ β和γ,以及λ来控制两个分量损失的相对权重。虽然这允许更大程度的灵活性,但这是以一个明显更大的超参数搜索空间为代价的。
(2) 第二个问题对所有Focal loss函数都是常见的,其中焦点参数引入的增强或抑制效应适用于所有类,这可能会影响训练结束时的收敛。
Unified Focal loss解决了这两个问题,通过将功能等价的超参数分组在一起,并利用不对称性,分别聚焦于修正的Focal los和Focal Tversky loss分量中的焦点参数的抑制和增强效应。
首先,用一个共同的δ参数代替Focal loss中的α和Tversky指数中的α和β来应对输出不平衡问题,并重新制定γ,使同时抑制Focal loss和增强Focal Tversky loss,修正后的Symmetric Focal loss和Symmetric Focal Tversky loss公式分别如下:
![]()
Symmetric Focal loss pytorch版代码(依据:公式16,二元分割情况)
#!###############################
#! Symmetric Focal loss ##ok
#!###############################
class SymmetricFocalLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
delta : float, optional
controls weight given to false positive and false negatives, by default 0.7
gamma : float, optional
Focal Tversky loss' focal parameter controls degree of down-weighting of easy examples, by default 2.0
'''
def __init__(self,weight=None,size_average=True):
super(SymmetricFocalLoss,self).__init__()
def forward(self, y_pred, y_true, delta=0.7, gamma=2, epsilon= 1e-7):
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_true.shape != y_pred.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# from [batch,1,H,W] to [batch,2,H,W] using one_hot format
y_true = one_hot(y_true, num_classes=2)
# clip the prediction to avoid NaN
y_pred = torch.clamp(y_pred, epsilon, 1.0 - epsilon)
# cross entropy, i.e y_i:r * log(p_t,c)
cross_entropy = -y_true * torch.log(y_pred)
# calculate losses separately for each class, only suppressing background class by xxx[:,0,:,], i.e (1-delta)[(1-p_t,0)** gamma * log(p_t,0)]
back_ce = torch.pow(1 - y_pred[:,0,:,], gamma) * cross_entropy[:,0,:,]
back_ce = (1 - delta) * back_ce
# foreground class by xxx[:,1,:,], i.e - delta * y_i:r * log(p_t,r)
fore_ce = torch.pow(1 - y_pred[:,1,:,], gamma) * cross_entropy[:,1,:,]
fore_ce = delta * fore_ce
loss = torch.mean(torch.sum(torch.stack([back_ce, fore_ce],dim=-1),dim=-1))
return loss

其中,

Symmetric Focal Tversky loss pytorch版代码(依据:公式17,二元分割情况)
#!####################################
#! Symmetric Focal Tversky Loss ##ok
#!####################################
class SymmetricFocalTverskyLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
delta : float, optional
controls weight given to false positive and false negatives, by default 0.7
gamma : float, optional
focal parameter controls degree of down-weighting of easy examples, by default 0.75
'''
def __init__(self,weight=None,size_average=True):
super(SymmetricFocalTverskyLoss,self).__init__()
def forward(self, y_pred, y_true, delta=0.7, gamma=0.75, epsilon= 1e-7):
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_true.shape != y_pred.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# from [batch,1,H,W] to [batch,2,H,W] using one_hot format
y_true = one_hot(y_true, num_classes=2)
# clip the prediction to avoid NaN
y_pred = torch.clamp(y_pred, epsilon, 1.0 - epsilon)
axis = list(range(2, len(y_pred.shape))) # (2,3)
# Calculate true positives (tp), false negatives (fn) and false positives (fp)
# from [batch,1,H,W] to [batch,1] by torch.sum(xx, dim=(2,3))
tp = torch.sum(y_true * y_pred, dim=axis)
fn = torch.sum(y_true * (1 - y_pred), dim=axis)
fp = torch.sum((1 - y_true) * y_pred, dim=axis)
dice_class = (tp + epsilon) / (tp + delta * fn + (1 - delta) * fp + epsilon)
# Calculate background losses by xx[:, 0], i.e (1-mTI_0)**(1-gamma)
back_dice = (1 - dice_class[:, 0]) * torch.pow(1 - dice_class[:, 0], -gamma)
# Calculate foreground losses by xx[:, 1] and enhance foreground class, i.e (1-mTI_1)**(1-gamma)
fore_dice = (1 - dice_class[:, 1]) * torch.pow(1 - dice_class[:, 1], -gamma)
# Average class scores
loss = torch.mean(torch.stack([back_dice, fore_dice], dim=-1))
return loss
因此,Unified Focal loss 的对称性变体被定义为:
![]()
其中,λ∈[0,1],并确定了两个损失的相对权重。通过分组功能等效超参数,将Hybrid Focal loss的6个超参数减少到3个,由δ控制了正、负样本的相对权重,γ同时控制了背景类的抑制和稀有类的增强,最后用λ确定两分量损失的权重。
Symmetric Unified Focal loss pytorch版代码(依据:公式19,二元分割情况)
#!###################################
#! Symmetric Unified FocalLoss ##ok
#!###################################
class SymmetricUnifiedFocalLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
weight : float, optional
represents lambda parameter and controls weight given to asymmetric Focal Tversky loss and asymmetric Focal loss, by default 0.5
delta : float, optional
controls weight given to each class, by default 0.6
gamma : float, optional
focal parameter controls the degree of background suppression and foreground enhancement, by default 0.5
'''
def __init__(self, weight: float = 0.5, gamma: float = 0.5, delta: float = 0.6, reduction='mean', ):
super(SymmetricUnifiedFocalLoss,self).__init__()
self.gamma = gamma
self.delta = delta
self.weight: float = weight
self.reduction = reduction
self.sym_focal_loss = SymmetricFocalLoss()
self.sym_focal_tversky_loss = SymmetricFocalTverskyLoss()
def forward(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> torch.Tensor:
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_pred.shape != y_true.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# notice: y_true donot using one_hot format in SymmetricUnifiedFocalLoss, using one_hot format in SymmetricFocalLoss() and SymmetricFocalTverskyLoss()
sym_focal_loss = self.sym_focal_loss(y_pred, y_true,delta=self.delta, gamma=self.gamma)
sym_focal_tversky_loss = self.sym_focal_tversky_loss(y_pred, y_true,delta=self.delta, gamma=self.gamma)
loss: torch.Tensor = self.weight * sym_focal_loss + (1 - self.weight) * sym_focal_tversky_loss
if self.reduction == 'mean':
loss = loss.mean()
if self.reduction == 'sum':
loss = loss.sum()
return loss
2.8.2 非对称性Unified Focal loss 原理及pytorch版代码
虽然Focal loss实现了对背景类的抑制,但焦点参数应用于所有类,因此由稀有类造成的损失也被抑制。非对称性通过给每个类分配不同的损失,可以利用焦点参数进行选择性增强或抑制,这就克服了对稀有类的有害抑制和对背景类的有益增强。改进的Asymmetric Focal loss消除了与稀有类r相关的损失分量的焦点参数,同时保留了对背景类的抑制(Li et al., 2019). 故将修正的Asymmetric Focal loss定义为:
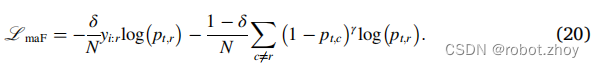
pytorch版代码(依据:公式20,二元分割情况)
#!###############################
#! Asymmetric Focal loss ##ok
#!###############################
class AsymmetricFocalLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
delta : float, optional
controls weight given to false positive and false negatives, by default 0.7
gamma : float, optional
Focal Tversky loss' focal parameter controls degree of down-weighting of easy examples, by default 2.0
'''
def __init__(self,weight=None,size_average=True):
super(AsymmetricFocalLoss,self).__init__()
def forward(self, y_pred, y_true, delta=0.7, gamma=2, epsilon= 1e-7):
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_true.shape != y_pred.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# from [batch,1,H,W] to [batch,2,H,W] using one_hot format
y_true = one_hot(y_true, num_classes=2)
# clip the prediction to avoid NaN
y_pred = torch.clamp(y_pred, epsilon, 1.0 - epsilon)
# cross entropy, i.e y_i:r * log(p_t,c)
cross_entropy = -y_true * torch.log(y_pred)
# calculate losses separately for each class, only suppressing background class by xxx[:,0,:,], i.e (1-delta)[(1-p_t,0)** gamma * log(p_t,0)]
back_ce = torch.pow(1 - y_pred[:,0,:,], gamma) * cross_entropy[:,0,:,]
back_ce = (1 - delta) * back_ce
# foreground class by xxx[:,1,:,], i.e - delta * y_i:r * log(p_t,r)
fore_ce = cross_entropy[:,1,:,]
fore_ce = delta * fore_ce
loss = torch.mean(torch.sum(torch.stack([back_ce, fore_ce],dim=-1),dim=-1))
return loss
相反,对于修正的Focal Tversky loss,去掉了与背景类相关的损失分量的焦点参数,保留了稀有类r的增强,并将修正的Asymmetric Focal Tversky loss定义为:
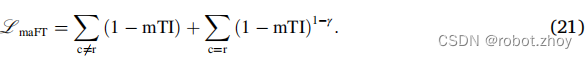
pytorch版代码(依据:公式21,二元分割情况)
#!####################################
#! Asymmetric Focal Tversky Loss ##ok
#!####################################
class AsymmetricFocalTverskyLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
delta : float, optional
controls weight given to false positive and false negatives, by default 0.7
gamma : float, optional
focal parameter controls degree of down-weighting of easy examples, by default 0.75
'''
def __init__(self,weight=None,size_average=True):
super(AsymmetricFocalTverskyLoss,self).__init__()
def forward(self, y_pred, y_true, delta=0.7, gamma=0.75, epsilon= 1e-7):
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the original logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_true.shape != y_pred.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# from [batch,1,H,W] to [batch,2,H,W] using one_hot format
y_true = one_hot(y_true, num_classes=2)
# clip the prediction to avoid NaN
y_pred = torch.clamp(y_pred, epsilon, 1.0 - epsilon)
axis = list(range(2, len(y_pred.shape))) # (2,3)
# Calculate true positives (tp), false negatives (fn) and false positives (fp)
# from [batch,1,H,W] to [batch,1] by torch.sum(xx, dim=(2,3))
tp = torch.sum(y_true * y_pred, dim=axis)
fn = torch.sum(y_true * (1 - y_pred), dim=axis)
fp = torch.sum((1 - y_true) * y_pred, dim=axis)
dice_class = (tp + epsilon) / (tp + delta * fn + (1 - delta) * fp + epsilon)
# Calculate background losses by xx[:, 0], i.e (1-mTI_0)
back_dice = 1 - dice_class[:, 0]
# Calculate foreground losses by xx[:, 1] and enhance foreground class, i.e (1-mTI_1)**(1-gamma)
fore_dice = (1 - dice_class[:, 1]) * torch.pow(1 - dice_class[:, 1], -gamma)
# Average class scores
loss = torch.mean(torch.stack([back_dice, fore_dice], dim=-1))
return loss
因此,非对称性Unified Focal loss 可被定义为:

pytorch版代码(依据:公式22,二元分割情况)
#!###################################
#! Asymmetric Unified FocalLoss ##ok
#!###################################
class AsymmetricUnifiedFocalLoss(nn.Module):
'''
This is the implementation for binary segmentation.
Parameters
----------
weight : float, optional
represents lambda parameter and controls weight given to asymmetric Focal Tversky loss and asymmetric Focal loss, by default 0.5
delta : float, optional
controls weight given to each class, by default 0.6
gamma : float, optional
focal parameter controls the degree of background suppression and foreground enhancement, by default 0.5
'''
def __init__(self, weight: float = 0.5, gamma: float = 0.5, delta: float = 0.6, reduction='mean', ):
super(AsymmetricUnifiedFocalLoss,self).__init__()
self.gamma = gamma
self.delta = delta
self.weight: float = weight
self.reduction = reduction
self.asy_focal_loss = AsymmetricFocalLoss()
self.asy_focal_tversky_loss = AsymmetricFocalTverskyLoss()
def forward(self, y_pred: torch.Tensor, y_true: torch.Tensor) -> torch.Tensor:
'''
y_pred : the shape should be [batch,1,H,W], and the input should be the logits by a sigmoid in the forward function.
y_true : the shape should be [batch,1,H,W].
'''
if y_pred.shape != y_true.shape:
raise ValueError(f"ground truth has different shape ({y_true.shape}) from input ({y_pred.shape})")
# notice: y_true donot using one_hot format in AsymmetricUnifiedFocalLoss, using one_hot format in AsymmetricFocalLoss() and AsymmetricFocalTverskyLoss()
asy_focal_loss = self.asy_focal_loss(y_pred, y_true,delta=self.delta, gamma=self.gamma)
asy_focal_tversky_loss = self.asy_focal_tversky_loss(y_pred, y_true,delta=self.delta, gamma=self.gamma)
loss: torch.Tensor = self.weight * asy_focal_loss + (1 - self.weight) * asy_focal_tversky_loss
if self.reduction == 'mean':
loss = loss.mean()
if self.reduction == 'sum':
loss = loss.sum()
return loss
通过与Focal Tversky loss 的互补配对,可以缓解Focal loss 抑制的问题,非对称性使背景损失抑制和前景损失同时增强,类似于增加信噪比(图2)。
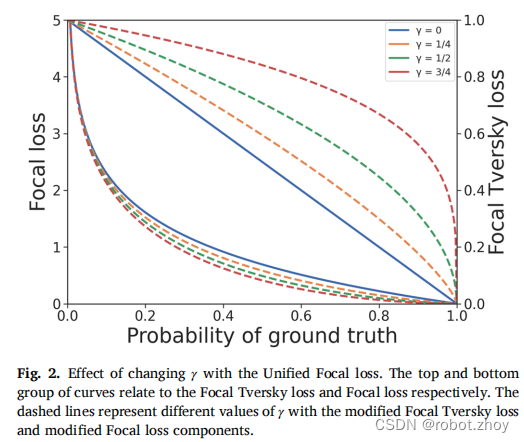
通过整合来自以前的损失函数的思想,Unified Focal loss 将基于Dice 和基于交叉熵的损失函数推广到一个单一的框架中。事实上,可以证明,到目前为止所描述的所有基于Dice 和交叉熵的损失函数都是Unified Focal loss 的特殊情况(图1)。例如,通过设置γ = 0和δ = 0.5,当λ分别设置为0和1时,可以恢复Dice loss 和交叉熵损失。通过明确损失函数之间的关系,Unified Focal loss比单独试验不同的损失函数更容易优化,而且它也更强大,因为它对输入和输出的不平衡都具有鲁棒性。重要的是,考虑到Dice loss 和交叉熵损失都是有效的操作,并且应用焦点参数增加了可以忽略不计的时间复杂度,Unified Focal loss 预计不会在其分量损失函数上显著增加训练时间。
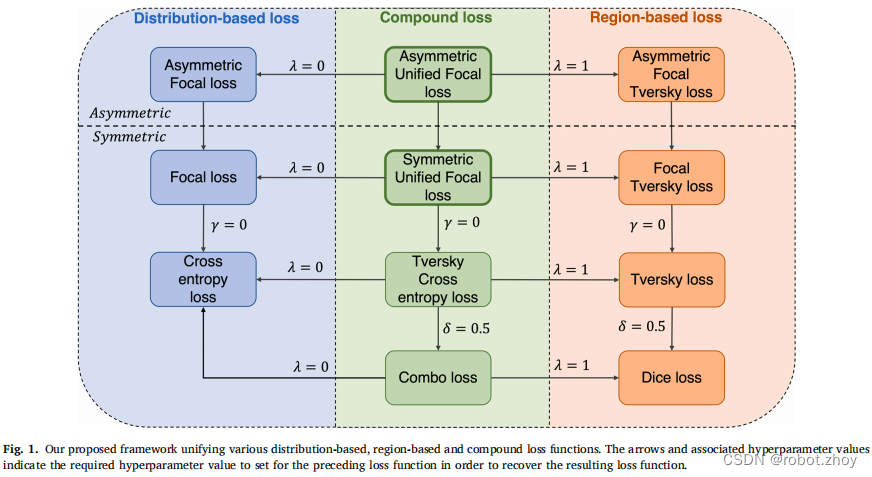
在实践中,对Unified Focal loss 的优化可以进一步简化为单个超参数。考虑到焦点参数对每个组件损失的不同影响,λ的作用是部分冗余的,因此建议设置λ = 0.5,它为每个组件损失分配相同的权重,并得到经验证据的支持(Taghanaki et al., 2019). 此外,建议设置δ = 0.6,以纠正Dice 丢失倾向,从而产生高精度、低召回率的分段。这小于Tversky loss中的δ = 0.7,以解释基于交叉熵分量的影响。这种启发式约简超参数搜索空间到单一γ参数使得Unified Focal loss 既强大又易于优化。

















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









