







Attribute-based Representations for Accurate and Interpretable Video Anomaly Detection 论文阅读
文章信息:

原文链接:https://arxiv.org/abs/2212.00789
源码地址:https://github.com/talreiss/Accurate-Interpretable-VAD
Abstract
视频异常检测(VAD)是一项具有挑战性的计算机视觉任务,具有许多实际应用。由于异常本质上具有模糊性,因此用户必须了解系统决策的推理过程,以确定其合理性。在本文中,我们提出了一种简单但高效的方法,通过采用基于属性的表示来推动VAD准确性和可解释性的边界。我们的方法使用速度和姿态来表示每个对象。异常分数则是通过基于密度的方法计算得出的。令人惊讶的是,我们发现这种简单的表示方法足以在最大且最复杂的VAD数据集ShanghaiTech中实现最先进的性能。
将我们可解释的基于属性的表示与隐式的深度表示结合,我们在Ped2、Avenue和ShanghaiTech上分别获得了99.1%、93.3%和85.9%的AUROC,达到了最先进的性能水平。我们的方法既准确又可解释,且易于实现。
1. Introduction
视频异常检测(VAD)是监控的一个关键目标,但也非常具有挑战性。其中最常见的VAD设置之一是单类分类(OCC)。在这种设置中,在训练阶段只看到正常视频,没有任何异常。在部署阶段,训练好的模型需要以有意义的语境区分正常事件和异常事件。关键难点在于,有意义的语境与非有意义的语境之间的差异是主观的。事实上,两个操作员可能在某个事件是否异常上存在分歧。此外,由于在训练阶段未提供标记的异常,因此不可能直接学习具有区分性的模式。
视频异常检测(VAD)经过几十年的研究,但深度学习的出现带来了显著的突破。近期的异常检测方法主要沿着两个方向发展:
(i) 基于手工制定的自监督学习先验:许多方法设计辅助任务,如旋转预测、对手动选择的增强不变性、预测时间箭头和时态流速等。这些方法在视频异常检测中占据主导地位。
(ii) 利用预训练编码器进行表示提取:这是一个两阶段方法,首先使用预训练的编码器(如在ImageNet上预训练的ResNet)计算表示,然后采用标准的密度估计方法,如kNN或马氏距离。这种方法在图像异常检测和分割中取得了成功。但这两种方法的问题在于它们学到的表示是不透明且难以解释的。
由于异常具有模糊性,因此对于研究人员来说,理解决策的标准是否合理至关重要,而这一点在这两种方法中都存在难题。
大多数最先进的异常检测方法尽管在安全关键应用中被使用,但它们并不具有解释性。在本文中,我们追求一种新的方向,使用对人类有意义且更易于解释的语义属性来表示数据。我们的方法提取由速度和姿态属性组成的表示。我们选择这些属性,是因为先前的研究,例如[13, 41]强调了它们的重要性。我们使用这些表示通过密度估计来评分异常。我们的方法将帧分类为异常,如果它们的速度和/或姿态取异常值。这实现了自动解释;取异常值的属性被解释为决策背后的理由(见图1)。

我们得到了令人惊讶的结果,即我们简单的基于属性的速度和姿态表示在最大且最复杂的VAD数据集上实现了最先进的性能,在ShanghaiTech中达到了85.9%的AUROC。尽管我们的基于属性的表示非常强大,但有些概念并不能通过它充分表示。原因在于,有些属性无法简单地使用语义人类属性进行量化。因此,为了对剩余属性建模,我们将明示的基于属性的表示与隐含的深度表示相结合,获得了两者的最佳效果。我们的最终方法在三个最常报告的数据集上实现了最先进的性能,同时具有很高的可解释性。
我们的方法的优点有三方面:
- 在三个最常用的公共数据集中取得了最先进的结果:在Ped2、Avenue和ShanghaiTech上分别达到了99.1%、93.3%和85.9%的AUROC。
- 做出可解释的决策,使我们的方法适用于人类理解至关重要的关键环境。
- 3.易于实施。
2. Related Work
经典的视频异常检测方法通常由两个步骤组成:手工特征提取和异常评分。提取的一些手动特征是:光流直方图[4,6,49]和SIFT [34]。常用的评分方法包括:密度估计[9,16,26]、重建[23]和一类分类[54]。
近年来,深度学习作为这些早期作品的替代品越来越受欢迎。大多数视频异常检测方法至少使用三种范例中的一种:基于重建的方法、基于预测的方法或基于辅助分类的方法。
Reconstruction & prediction based methods.
在重建范例中,正常训练数据通常由自动编码器表征,然后用于重建输入视频剪辑。假设仅在正常训练片段上训练的模型将无法重建异常帧。这个假设并不总是正确的,因为神经网络通常可以在一定程度上泛化到分布之外。值得注意的作品是[3,18,37,45,48,64]。
基于预测的方法学习预测视频剪辑中的帧或光流图,包括修复中间帧和预测未来帧[5,11,12,28,30,36,48,59,64]。此外,一些作品采用了结合两种范式的混合方法[32,44,56,63,67]。由于这些方法被训练以优化两个目标,因此具有大的重建或预测误差的输入帧被认为是异常的。
Self-supervised auxiliary tasks.
关于从无标签数据中学习已经进行了大量的研究。一种常见的方法是在适当设计的辅助任务上训练神经网络,这些任务具有自动生成的标签。这些任务包括:视频帧预测[42]、图像着色[25, 66]、拼图问题解决[47]、旋转预测[15]、时间箭头[61]、播放速度预测[7]和验证帧顺序[43]。许多视频异常检测方法使用自监督学习。实际上,自监督学习是大多数基于重建和基于预测的方法中的一个关键组成部分。SSMTL [13] 在三个辅助任务上联合训练卷积神经网络:时间箭头、运动不规律性和中间框预测,此外还进行了知识蒸馏。Jigsaw-Puzzle [58] 训练神经网络解决时空拼图问题,然后将这些网络用于VAD。
Object-level video anomaly detection.
早期的方法,无论是经典方法还是深度学习方法,都是在整个视频帧上进行操作的。这在异常检测方面变得困难,因为帧包含许多变化,以及大量的物体。更近期的方法[13, 32, 58]在对象级别进行操作,首先使用现成的物体检测器提取对象的边界框。然后,它们检测每个对象是否异常。这是一个较为简单的任务,因为对象相较于整个帧包含的变化要少得多。基于对象的方法比基于帧的方法产生了显著更好的结果。
通常人们认为,由于现实场景的复杂性和行为的多样性,很难设计能够区分它们的特征。在深度学习之前,由于目标检测不准确,经典方法以前常常在帧级别而非对象级别应用,因此在标准基准测试上表现不佳。本文打破了这一误解,并证明了可以设计出既准确又可解释的语义特征。
3. Preliminaries
在视频异常检测(VAD)任务中,我们被提供了一个训练集 { c 1 , c 2 . . . c N c c_1, c_2...c_{N_c} c1,c2...cNc } ∈ X t r a i n X_{train} Xtrain,其中包含了 N c N_c Nc个视频片段,它们都是正常的(即不包含任何异常)。每个片段 c i c_i ci 由 N i N_i Ni 帧组成, c i = [ f 1 , j , f i , 2 , . . . f i , N i ] c_i = [f_{1,j} , f_{i,2}, ...f_{i,Ni} ] ci=[f1,j,fi,2,...fi,Ni]。给定一个推理片段 c c c,目标是对片段中的每一帧 f ∈ c 进行正常或异常的分类。每一帧 f 都使用一个函数 ϕ \phi ϕ: X → R d R^d Rd 来表示,其中 d ∈ N 是特征维度。接下来,一个异常评分函数 s ( ϕ ( f ) ) s(\phi(f)) s(ϕ(f)) 计算帧 f 的异常评分。如果 s ( ϕ ( f ) ) s(\phi(f)) s(ϕ(f)) 超过一个常数阈值,那么该帧将被分类为异常。
4. Methodology
4.1. Overview
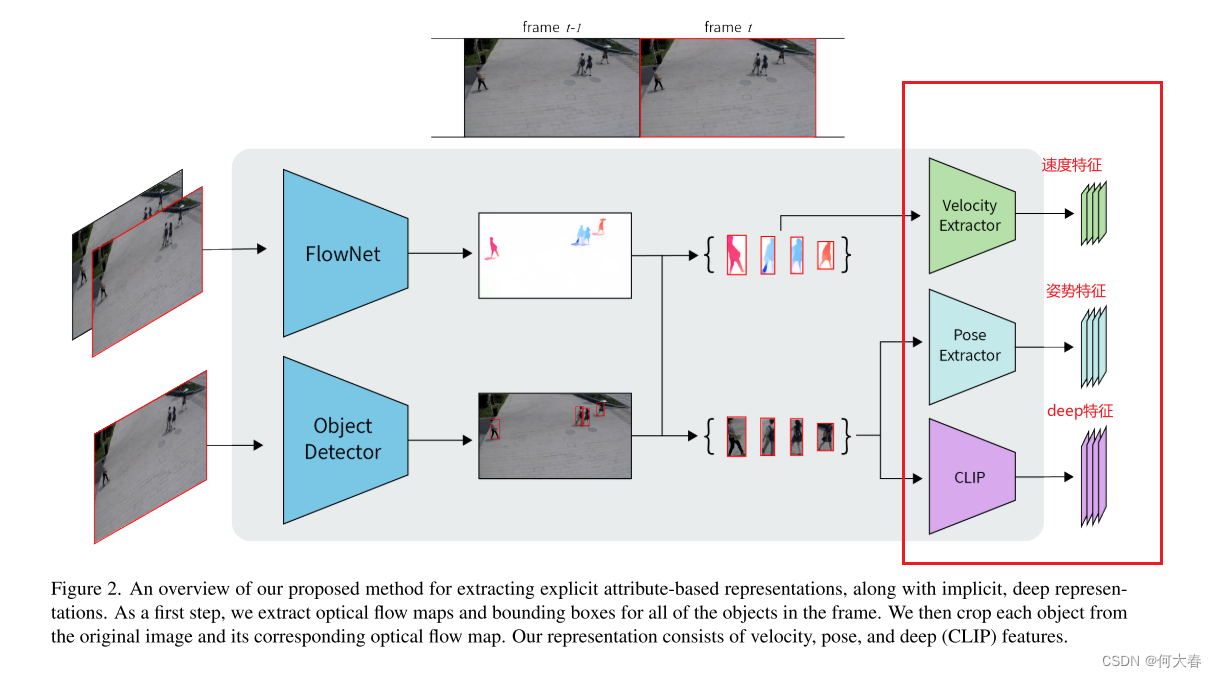
我们的方法包含三个阶段:预处理、特征提取和密度估计。在我们的预处理阶段,我们采用一个现成的运动估计器来预测每一帧的光流。还使用了一个现成的物体检测器来定位和分类帧内所有对象的边界框。然后,我们使用这两个模型的输出(参见第4.3节)来提取速度、姿态和深度表示,以创建对象级别的特征描述符。最后,使用密度估计计算每个测试帧的异常分数。前两个阶段的过程如图2所示。

图2. 我们提出的用于提取显式基于属性的表示以及隐式深度表示的方法概览。作为第一步,我们提取帧中所有对象的光流图和边界框。然后,我们从原始图像中裁剪每个对象及其对应的光流图。我们的表示包括速度、姿态和深度(CLIP)特征。
4.2. Pre-processing
视频剪辑中的异常对象通常表现出不寻常的运动或活动。因此,我们依赖于与对象和运动相关联的表示。
Optical flow.
我们的方法使用光流作为推断对象运动的初步阶段。它是在每两个相继的帧之间计算的。我们使用一个现成的光流模型在每个视频片段 c 中的每一帧 f ∈ c 中提取光流。光流图用 o 表示。
Object detection.
我们的方法通过分别表示每个对象来对帧进行建模。这与许多近期的论文相符,例如 [13, 32, 58],这些论文发现基于对象的表示比全局的帧级表示更为有效。与这些近期的论文类似,我们首先使用一个现成的物体检测器在每一帧中检测所有对象。在形式上,我们的目标检测为每一帧生成一组
m
m
m 个边界框
b
1
,
b
2
,
.
.
.
b
m
b_1, b_2, ... b_m
b1,b2,...bm,带有相应的类别标签
y
1
,
y
2
,
.
.
.
y
m
y_1, y_2, ... y_m
y1,y2,...ym。
4.3. Feature extraction
我们的方法通过两个属性表示每个对象:速度和姿态:
Velocity features.
我们的工作假设是,异常速度是识别视频中异常的一个相关属性。由于对象可以在 x 和 y 轴上移动,速度的幅度(速度)和方向都可能是异常的,因此我们通过速度特征来表示每一帧中的每个对象。我们首先通过物体检测器检测到的每个对象的边界框裁剪帧级光流图。在此步骤之后,我们获得一组裁剪后的对象流图,如图2所示。
然后,这些流图被重新缩放为固定大小的
H
f
l
o
w
H_{flow}
Hflow ×
W
f
l
o
w
W_{flow}
Wflow。接下来,我们建议将每个方向的平均运动作为特征(与HOOF [4]类似的思想)。每个流向量的方向计算为
θ
=
a
t
a
n
2
(
y
,
x
)
θ = atan2(y, x)
θ=atan2(y,x)。方向被量化为 B ∈ N 个等间距的区间,最终的表示包括分配给每个区间的流向量的平均流幅度。这个表示能够描述径向和切向方向的运动。形式上,设 o 是一个对象的流图,b ∈ [B]。然后o的所有光流矢量
[
x
,
y
]
T
[x,y]^T
[x,y]T与方向θ在范围:
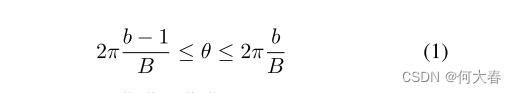
将对应于方向 θ 在范围内的 o 的所有流向量
[
x
,
y
]
T
[x,y]^T
[x,y]T贡献到 bin b 的总和中,其贡献量为 m = ||x|| + ||y||。作为最后一步,贡献到第 b 个 bin 的流向量幅度被求平均。我们将贡献到 b 号 bin 的流向量幅度表示为 m。我们将我们的速度特征提取器表示为:
ϕ
v
e
l
o
c
i
t
y
:
H
f
l
o
w
×
W
f
l
o
w
→
R
B
\phi_{velocity} : H_{flow} × W_{flow} → R^B
ϕvelocity:Hflow×Wflow→RB。
Pose features.
不规律的人类活动通常是异常的。虽然对活动的完全理解需要时间特征,但我们发现即使从单个帧中提取的人体姿势也可能提供足够具有区别性的不规律活动信号。我们通过人体关键点的位置表示人体姿势。我们的方法使用一个现成的深度关键点提取器为每个人体对象 o 获取姿势特征描述符,表示为
ϕ
^
p
o
s
e
(
o
)
∈
R
2
×
d
\widehat{\phi}pose(o) ∈ R^{2×d}
ϕ
pose(o)∈R2×d,其中 d ∈ N 是关键点的数量。在实践中,我们使用了AlphaPose [10],发现它效果很好。关键点提取器的输出是每个关键点位置的像素坐标。我们进行了一个简单的归一化阶段,以确保关键点对于人的位置和大小是不变的。我们首先从每个关键点中减去对象边界框左上角的坐标。然后,我们缩放 x 和 y 轴,使得对象边界框最终具有大小
H
p
o
s
e
×
W
p
o
s
e
H_{pose} ×W_{pose}
Hpose×Wpose(其中
H
p
o
s
e
H_{pose}
Hpose,
W
p
o
s
e
W_{pose}
Wpose 是常数)。形式上,设
l
∈
R
2
l ∈ R^2
l∈R2 是人边界框的左上角。姿势描述变为:
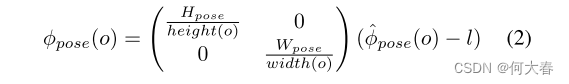
其中
h
e
i
g
h
t
(
o
)
height(o)
height(o),
w
i
d
t
h
(
o
)
width(o)
width(o)分别是对象或边界框的高度和宽度。最后,我们将
ϕ
p
o
s
e
\phi_{pose}
ϕpose平坦化以获得最终的姿势特征向量。
Deep features.
虽然我们的基于属性的表示已经非常强大,但有时它可能不足以表达所有的异常。强大的深度特征非常具有表达性,将许多不同的属性捆绑在一起。因此,我们使用隐式的深度表示来对无法通过速度和姿态描述的剩余属性进行建模。根据图像异常检测文献的结果,这些隐式表示在外部的通用数据集上进行预训练,然后迁移到异常检测任务中。先前的研究 [51,52] 表明,将这些强大的表示与简单的异常检测分类器(例如 kNN)结合使用可以取得出色的结果。具体来说,我们的隐式表示是使用预训练的 CLIP 编码器 [50](表示为
ϕ
d
e
e
p
(
.
)
\phi_{deep}(.)
ϕdeep(.))来表示每一帧中的每个对象边界框。
4.4. Density Estimation
我们使用密度估计对样本进行评分,判断其是否正常或异常,其中估计的密度较低表示异常。为了估计密度,我们为每个特征拟合一个独立的估计器。对于较低维度的速度特征,我们使用高斯混合模型(GMM)估计器。由于我们的姿势和深度特征是高维的,并且不假设它们服从特定的参数假设,我们使用 kNN 来估计它们的密度。也就是说,我们计算目标对象的特征 x 与相应的训练特征集中的 K 个样本之间的 L 2 L_2 L2距离。有关不同样本选择方法的比较,请参阅第5.4节。我们用 s v e l o c i t y ( . ) s_{velocity}(.) svelocity(.)、 s p o s e ( . ) s_{pose}(.) spose(.)、 s d e e p ( . ) s_{deep}(.) sdeep(.) 表示我们的密度估计器。
Score calibration.
合并三个密度估计器需要进行校准。为了做到这一点,我们估计了正常训练集上异常分数的分布。然后,我们使用最小-最大规范化对分数进行缩放。用于对姿势和深度特征进行评分的 kNN 提出了一个微妙的问题。在计算训练集上的 kNN 时,样本不能来自与目标对象相同的视频片段。原因是同一对象在附近的帧中几乎没有变化,会扭曲 kNN 的估计。相反,我们计算每个训练集对象与训练集中提供的其他视频片段中的所有对象之间的 kNN。
我们现在可以定义以下参数:
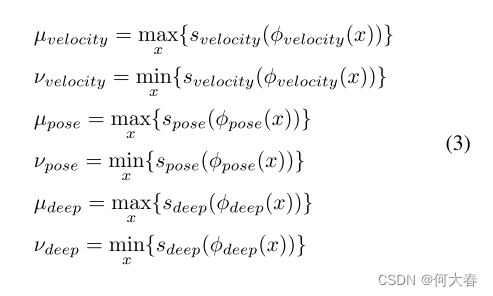
4.5. Inference
每个推断剪辑
c
c
c = {
f
1
,
.
.
.
,
f
n
f_1,...,f_n
f1,...,fn}被逐帧地馈送到光流估计器和对象检测器两者中。然后,我们从每个对象
o
i
o_i
oi中提取三个特征:
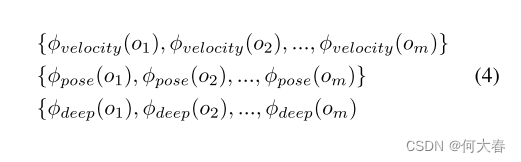
其中 m 是检测到的对象数量。我们为每个特征训练密度估计器。每帧的分数就是所有对象中最大的分数。最终的异常分数是通过我们在公式(3)中计算的校准参数对各个特征分数进行规范化后的总和。
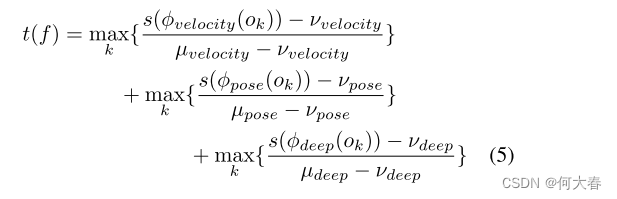
让我们将视频片段
c
c
c 中每一帧的异常分数表示为
t
(
c
)
t(c)
t(c) = {
t
(
f
1
)
,
.
.
.
,
t
(
f
n
)
t(f_1), ..., t(f_n)
t(f1),...,t(fn)}。由于我们期望异常事件是持续的,我们通过在
t
(
c
)
t(c)
t(c) 上应用一维时域高斯滤波器来平滑结果。
5. Experiments
5.1. Datasets
我们的实验使用了三个公开可用的视频异常检测数据集。为每个数据集定义了训练集和测试集,测试中仅包括异常事件。所有数据集都是在户外收集的。我们在表1中报告了数据集的统计信息。
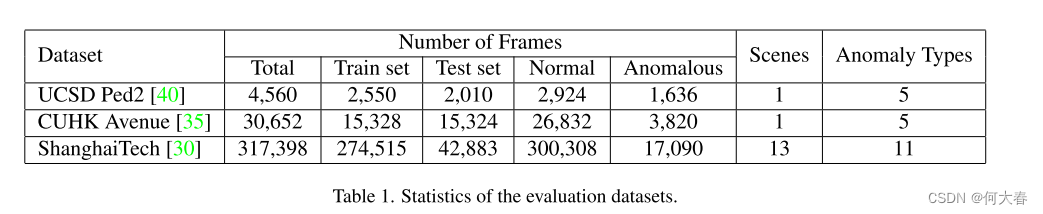
UCSD Ped2.
Ped2数据集[40]包含16个正常的训练视频和12个测试视频,分辨率为240 × 360像素。视频是从一个固定的场景中收集的,摄像头位于场景上方并向下指向。训练视频片段仅包含行人正常行为的情况,而异常事件的示例包括骑自行车、滑板以及汽车。
CUHK Avenue.
Avenue数据集[35]包含16个正常的训练视频和21个测试视频,分辨率为360×640像素。视频是通过使用地面摄像机从一个固定的场景中收集的。训练视频片段仅包含正常行为。异常事件的示例包括:奇怪的活动(例如投掷物体、徘徊和奔跑)、错误方向的移动和异常对象。
ShanghaiTech Campus.
ShanghaiTech数据集[30]是目前公开可用的最大的视频异常检测数据集。该数据集包含来自13个不同场景的330个训练视频和107个测试视频,分辨率为480×856像素。ShanghaiTech包含具有复杂光照条件和摄像机角度的视频片段,使得该数据集比其他两个更具挑战性。异常事件包括抢劫、跳跃、打斗、汽车入侵以及在行人区骑自行车等。
5.2. Implementation Details
我们使用在MSCOCO [29] 上预训练的ResNet50 Mask-RCNN [20]来提取对象的边界框。为了滤除置信度较低的对象,我们按照[13]中的相同配置进行操作。具体而言,对于Ped2、Avenue和ShanghaiTech,我们将置信度阈值分别设置为0.5、0.8和0.8。这些置信度阈值在训练集和测试集中相同。为了生成光流图,我们使用FlowNet2.0 [21]。对于我们的关键点检测,我们使用在MS-COCO上预训练的AlphaPose [10],其中 d = 17 表示关键点数量。我们使用预训练的ViT B-16 [8] CLIP [50]图像编码器作为我们的深度特征提取器。我们的方法围绕提取的对象和光流图构建。我们使用 H v e l o c i t y H_{velocity} Hvelocity × W v e l o c i t y W_{velocity} Wvelocity = 224 × 224 来重新缩放光流图。至于 H p o s e H_{pose} Hpose × W p o s e W_{pose} Wpose 的缩放,我们计算训练集边界框的平均高度和宽度,并使用这些值。Ped2的较低分辨率阻止了对象填充直方图,因此为了提取姿势表示,我们使用 B = 1 个方向,并且仅依赖于速度和深度表示。对于Avenue和ShanghaiTech,我们使用 B = 8 个方向。由于ShangahiTech的高分辨率,我们通过边界框高度来标准化幅度。在测试时,对于姿势和深度表示的异常评分,我们使用 k = 1 最近邻的kNN。对于速度,我们对Avenue和ShanghaiTech使用 n = 5 个高斯分布,对Ped2使用 n = 2 个高斯分布的GMM。最后,一帧的异常分数表示在该帧中的所有对象中的最大分数。
5.3. Evaluation Metrics
我们的研究遵循视频异常检测文献中流行的评估指标,通过改变异常分数的阈值来测量接收器操作特征下的帧级区域(AUROC)相对于地面实况注释。我们报告了两种类型的AUROC:(i)微平均AUROC,其通过连接来自所有视频的帧然后计算分数来计算。(ii)宏平均,通过对每个视频的帧级AUROC求平均值来计算。在大多数现有研究中,报告了微观平均AUROC,而只有少数报告了宏观平均AUROC。
5.4. Experimental Results
我们在表2中比较了我们的方法和近年来的最新技术。基线方法的性能数据直接取自它们的原始论文。我们报告了三个公开可用、最常用的数据集(UCSD Ped2、CUHK Avenue和ShanghaiTech)的微平均和宏平均AUROC(如果有的话)。
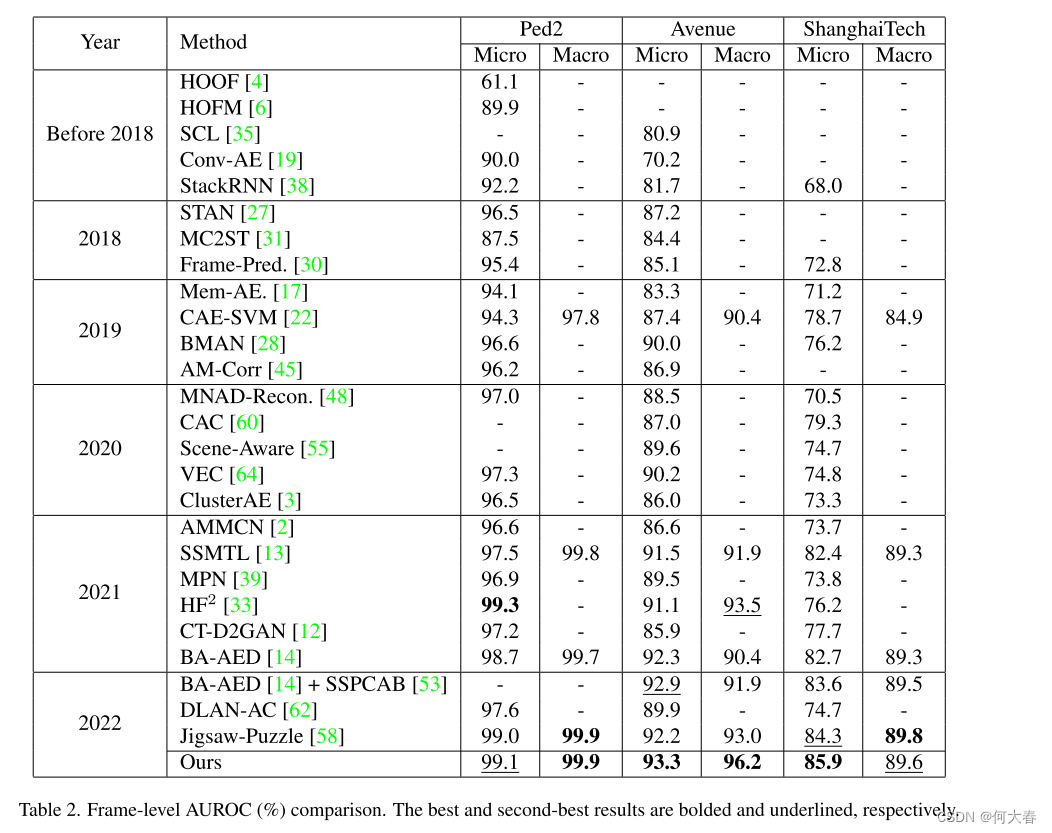
Ped2 Results.
PED2是一个长期存在的视频异常检测数据集,因此许多以前的论文都有报道。大多数方法在PED2上获得了94%以上的结果,这表明在三个公共数据集中,它是最简单的。虽然我们的方法在性能方面与当前最先进的方法( H F 2 HF^2 HF2[32])相当,但它也提供了一种可解释的表示。我们的方法在PED2上的近乎完美的结果表明该问题是实际求解的。
Avenue Results.
从以前的作品中可以明显看出,Avenue是一个与Ped2不同复杂程度的数据集。然而,我们的方法应用于这个数据集获得了一个新的最先进的AUROC的93.3%的微平均AUROC。此外,我们的方法性能超过了目前最先进的2.7%,达到了96.2%的宏观平均AUROC。
ShanghaiTech Results.
我们的方法在最难的数据集ShanghaiTech上的性能优于所有以前的方法。因此,我们的方法实现了85.9%的AUROC,而之前的方法实现的最高性能为84.3%(Jigsaw-Puzzle [58]),超过了当前最先进的1.6%。
总而言之,我们的方法在三个最常用的公共基准测试中达到了最先进的性能。它在没有任何训练或优化的情况下优于所有以前的方法,同时利用可以由人类解释的表示。
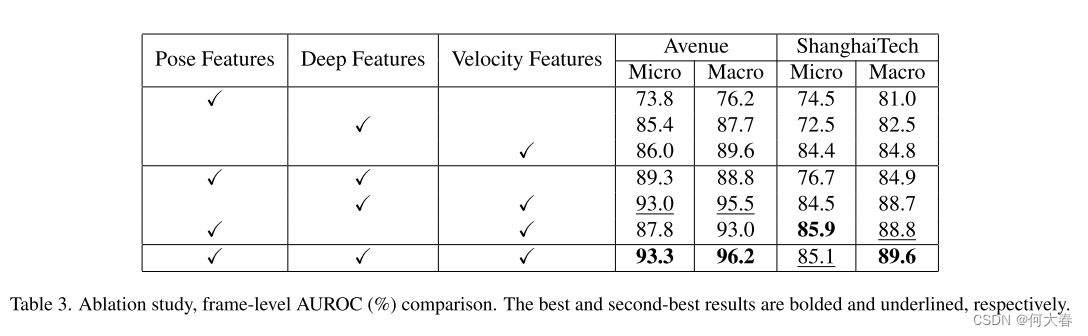
5.5. Ablation Study
我们在Avenue和ShanghaiTech数据集上进行了消融研究,以更好地了解影响我们方法性能的因素。我们在表3中报告了所有特征组合的异常检测性能。我们的研究发现,速度特征在Avenue和ShanghaiTech上提供了最高的帧级AUROC,分别为86.0%和84.4%的微平均AUROC。在ShanghaiTech上,我们的速度特征单独就已经是与所有先前的VAD方法相比的最先进水平。我们认为这可能是因为速度和运动与大量异常相关,例如奔跑的人和快速移动的对象,如汽车和自行车。速度和姿势的组合在ShanghaiTech上实现了85.9%的AUROC。姿势特征旨在检测异常行为,如人与人之间的打斗和不自然的姿势,如图4和图1所示。然而,当我们将基于属性的表示与深度残差表示组合时,我们观察到轻微的性能下降;这可能是因为深度表示捆绑了许多不同的属性,并且通常被不相关的干扰属性所主导,这些属性不能区分正常和异常对象。至于Avenue,我们的基于属性的表示与深度残差表示结合使用时表现良好,实现了93.3%的微平均AUROC和96.2%的宏平均AUROC的最先进结果。
总体而言,我们观察到使用所有三个特征对于实现最先进的结果至关重要。
5.6. Qualitative Results
我们在图3和图4中提供了Avenue和ShanghaiTech的异常检测过程的可视化,其中异常曲线显示了视频所有帧的异常分数。我们的异常分数与异常事件的地面实况发生高度相关。这证明了我们方法的有效性。
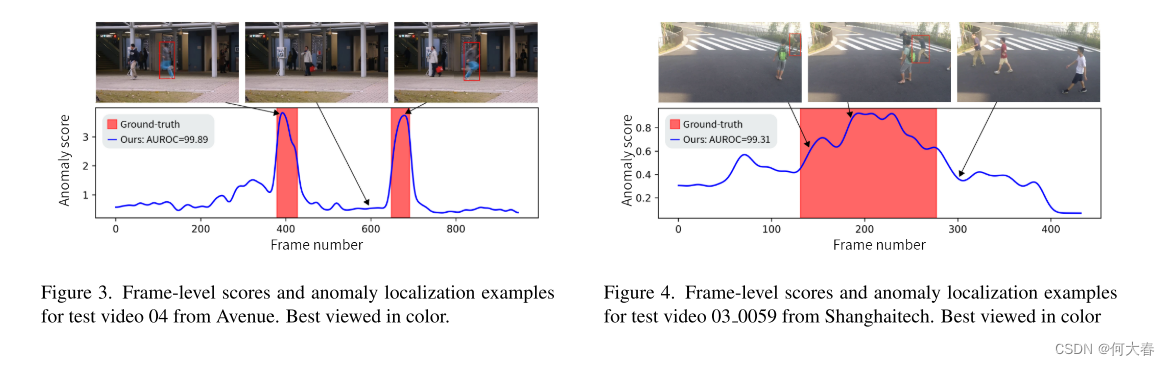
5.7. Further Analysis & Discussion
Interpretable decisions.
我们使用了基于语义属性的表示,使决策的理由可以解释。这是因为我们的方法将帧分类为异常,如果它们的速度和/或姿势取异常值。用户可以观察到哪个属性具有异常值,从而表明该帧在这个属性上是异常的。为了展示我们方法的可解释性,在图1中,我们展示了Avenue和ShangahiTech中每种表示中最正常和最异常的帧的可视化。速度表示中的高异常分数归因于快速移动的(通常是非人类的)对象。正如从姿势表示中也可以看出的,最异常的帧包含具有异常人体姿势的帧,表明了异常行为。最后,我们的隐式深度表示捕捉到无法通过我们的语义属性表示充分描述的概念(例如,异常的对象)。这与语义属性相辅相成,获得了两者的优势。
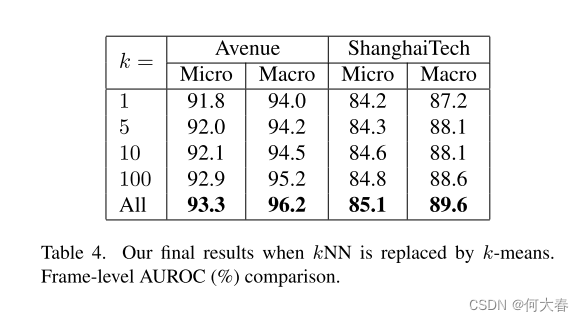
k-Means as a faster alternative to kNN.
我们可以通过使用 k-means 来减少样本数量来加速 kNN。在表4中,我们比较了我们提出的方法与基于速度、姿势和深度特征以及基于 k-means 的近似方法相结合时的性能。我们的方法仍然使用 kNN,但异常分数是使用到最近邻均值的距离之和计算的。这比原始的 kNN 要快得多,因为均值的数量远远少于训练集中对象的数量。很明显,精度的小损失可能会导致推理时间的显着提高。
What are the benefits of pretrained features?
先前的图像异常检测工作 [51, 52] 表明,使用在外部通用数据集上预训练的特征提取器(例如在ImageNet分类上的ResNet)可以实现高性能的异常检测。这在各种各样的数据集上得到了证明,包括大小、领域、分辨率和对称性的不同。这些表示在远距离领域,如航空、显微镜和工业图像上实现了最先进的性能。由于这些数据集中的异常通常与速度或人体姿势无关,因此很明显,预训练特征可以捕捉除速度和姿势之外的许多属性。因此,通过将我们的基于属性的表示与CLIP的图像编码器相结合,我们能够强调从真实世界先验中派生的显式属性(速度和姿势),以及不能由它们描述的属性,从而实现两者的最佳结合。
Why do we use an image encoder instead of a video encoder?
不断涌现的更先进的自监督学习方法,例如TimeSformer [1]、VideoMAE [57]、X-CLIP [46]和CoCa [65],不断提高了预训练视频编码器在下游监督任务(如Kinetics-400 [24])上的性能。因此,自然而然地期望利用时空信息的视频编码器将比不利用时空信息的图像编码器提供更高水平的性能。然而,不幸的是,在初步实验中,我们发现预训练视频编码器提取的特征在VAD中使用的基准视频类型上表现得不如预训练图像特征。这个结果强调了预训练图像编码器在图像异常检测背景下先前强调的强大的泛化性质。提高在单类别分类VAD设置中预训练视频特征的泛化性是未来工作的一个有希望的方向。
6. Conclusion
我们的论文提出了一种简单而高效的基于属性的方法,推动了视频异常检测准确性和可解释性的边界。在每一帧中,我们使用速度和姿势表示来表示每个对象,然后进行基于密度的异常评分。这些简单的速度和姿势表示使我们在ShanghaiTech,这个最复杂的视频异常数据集中取得了最先进的成果。当我们将可解释的基于属性的表示与隐式深度表示结合时,我们在Ped2、Avenue和ShanghaiTech上分别实现了99.1%、93.3%和85.9%的AUROC,达到了顶级的视频异常检测性能。我们还在全面的消融研究中展示了我们三种特征表示的优势。我们的方法非常准确、可解释且易于实现。
阅读总结
首先提取三个特征,分别是速度、姿势、deep特征
然后使用kNN进行异常评分。
可解释就是用了可以量化的速度和姿势。

















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









