







A Coarse-to-Fine Pseudo-Labeling Framework for Unsupervised Video Anomaly ...论文阅读

发表与:WACV 2024
原文链接:https://arxiv.org/pdf/2310.17650.pdf
源码:https://github.com/AnasEmad11/C2FPL
Abstract
视频中的异常事件检测是监控等应用中的重要问题。视频异常检测(VAD)在单类分类(OCC)和弱监督(WS)设置下得到了广泛研究。然而,完全无监督(US)的视频异常检测方法,即在不使用任何标注或人工监督的情况下学习一个完整的系统,尚未得到深入研究。这是因为缺乏任何真实标注极大地增加了视频异常检测的挑战性。为了应对这一挑战,我们提出了一个简单而有效的两阶段伪标签生成框架,该框架能够生成片段级(正常/异常)伪标签,这些伪标签可以进一步用于以监督方式训练一个片段级异常检测器。所提出的粗到细伪标签(C2FPL)生成器采用精心设计的层次分裂聚类和统计假设检验,从一组完全未标注的视频中识别出异常视频片段。训练好的异常检测器可以直接应用于未见测试视频的片段,以获得片段级,进而获得帧级的异常预测。在两个大规模公共领域数据集UCF-Crime和XD-Violence上的广泛研究表明,与所有现有的OCC和US方法相比,所提出的无监督方法取得了优越的性能,同时与最先进的WS方法性能相当。代码可在以下网址获取:https://github.com/AnasEmad11/C2FPL。
1. Introduction
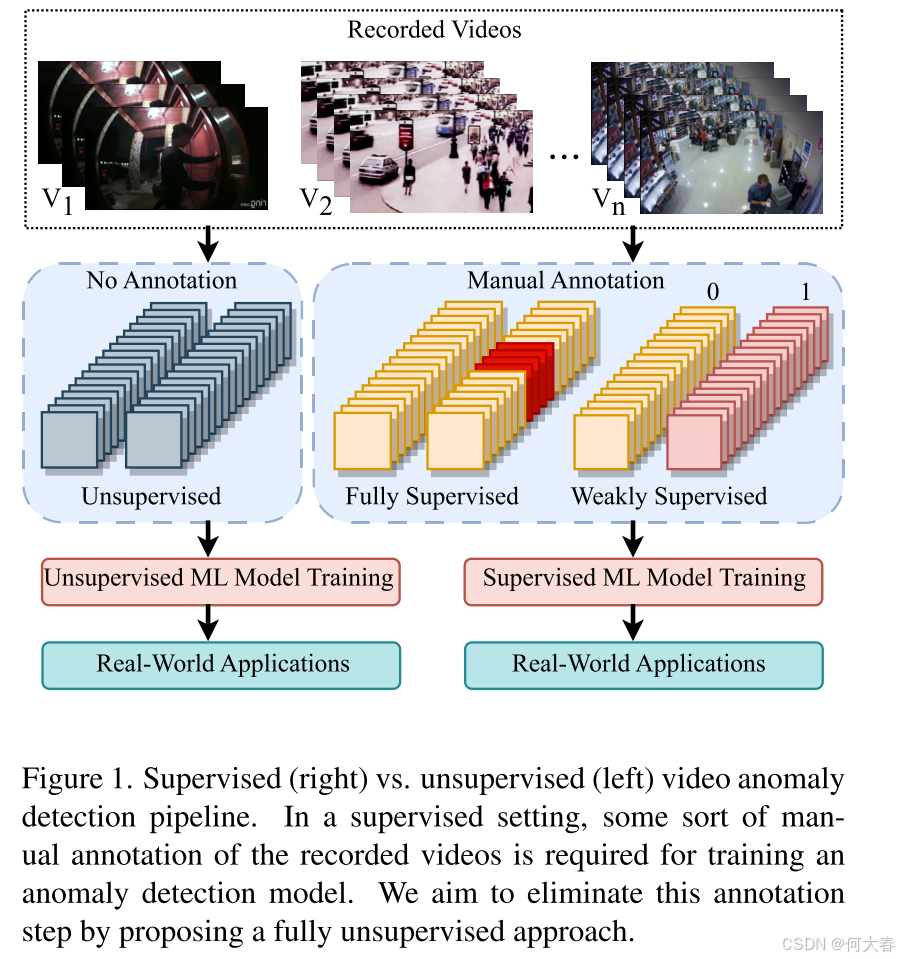
视频监控等应用持续产生大量视频数据。虽然其中绝大多数视频仅包含正常行为,但检测那些偏离正常行为且可能偶尔出现在这些视频中的异常事件(如射击、交通事故、打斗等)至关重要。因此,视频异常检测(VAD)是一个关键问题,尤其是在监控应用中[9, 13, 14, 19]。
传统的视频异常检测方法严重依赖于手动标注的异常示例(图1(右))[2]。然而,考虑到异常事件在真实场景中很少发生且持续时间短暂,获取准确的细粒度标注是一项艰巨的任务。最近,为了降低标注成本,已经提出了几种视频异常检测方法,这些方法利用视频级标签进行弱监督(WS)训练[5, 15, 19, 25, 35, 39]。但是,由于监控数据集通常是大规模的视频集合,因此获取任何形式的标签仍然很繁琐。例如,即使是为了获得视频级的二元标签,标注人员可能仍然需要观看整个视频,这将耗费大量时间。例如,一个著名的弱监督视频异常检测数据集XDViolence[31]包含的视频总时长达到了217小时。视频异常检测的另一种范式是单类分类(OCC),它假设只有正常视频可用于训练[16, 19, 25, 30, 35]。然而,单类分类设置并没有完全解决标注问题,因为标注人员仍然需要观看所有训练视频以确保其中没有异常。
一种无需标签的完全无监督方法是一种更为实用和有用的设置,尤其是在真实场景中,录制视频数据比标注视频数据更容易[36]。无监督视频异常检测(US-VAD)方法可以通过完全消除对手动标注的需求来解决上述监督方法的缺点(图1)。然而,无监督视频异常检测方法在计算机视觉领域尚未获得广泛关注。最近,Zaheer等人[36]引入了一种无监督视频异常检测方法,该方法在未标注的正常和异常视频上训练模型。他们的想法是利用训练数据的多个属性,通过生成器和分类器之间的合作来获得伪标签。虽然这种方法很巧妙,但其性能显著低于最先进的弱监督(WS)和单类分类(OCC)方法[23, 36]。
在本工作中,我们试图通过以未标注的训练视频集作为输入,并在不依赖任何人工监督的情况下生成片段级伪标签,来弥合无监督方法和监督方法之间的鸿沟。为此,我们做出了以下关键贡献:
我们提出了一种两阶段由粗到细(Coarse-to-Fine)伪标签(C2FPL)生成器,该生成器利用层次分裂(自上而下)聚类和统计假设检验来获得片段级(细粒度)伪标签。
基于C2FPL框架,我们提出了一个无需任何标注即可训练的无监督视频异常检测系统。据我们所知,这是首批详细探索无监督视频异常检测设置的工作之一。
我们在两个大规模视频异常检测数据集UCF-Crime[19]和XD-Violence[31]上对提出的方法进行了评估,并在无监督类别中取得了最先进的性能,同时优于所有现有的单类分类(OCC)方法和几种弱监督视频异常检测(WS-VAD)方法。
2. Related Work
早期的视频异常检测方法大多依赖于监督学习,即在训练数据中明确标注视频中的异常帧[6, 27]。由于监督方法需要大量标注数据,而标注异常是一项艰巨的任务,因此弱监督(WS)、单类分类(OCC)和无监督(US)视频异常检测方法正受到越来越多的关注。
2.1. One-Class Classification for VAD
为了避免捕获异常示例,研究人员广泛探索了单类分类(OCC)方法[7, 12, 29, 32]。在OCC视频异常检测(OCC-VAD)中,仅使用正常视频来训练一个异常检测器。在推理时,不符合学习到的正常表示的数据实例被预测为异常。由于已知如果正常数据包含一些异常示例,OCC方法会失败[36],因此它们需要对数据集中的所有视频进行仔细验证,这并没有减轻标注负担。此外,视频数据往往过于多样,难以成功建模,与学习到的表示不同的新正常场景可能会被分类为异常。因此,OCC方法在视频异常检测领域的应用有限。
2.2. Weakly Supervised VAD
利用弱标签(即视频级标签)的异常样本相较于OCC训练取得了显著改进[19,25]。多示例学习(MIL)是弱监督视频异常检测(WS-VAD)中最常用的方法之一[16, 19, 25, 30],其中,视频的片段被组合成一个包,并为包分配包级标签。Sultani等人[19]首次引入了带有排序损失函数的MIL框架,该损失函数在正常包和异常包中得分最高的片段之间计算得出。
弱监督视频异常检测(WS-VAD)中的一个关键挑战是,正包(异常包)是嘈杂的。由于异常在时间上具有局部性,因此异常包中的大多数片段也是正常的。因此,Zhong等人[39]在有噪声标签的情况下将问题重新表述为二分类问题,并使用图卷积网络(GCN)来去除标签噪声。由于存在动作分类器,GCN的训练在计算上很昂贵。此外,基于MIL的方法需要在每次训练迭代中提供完整的视频输入。因此,输入数据的相关性会显著影响异常检测网络的训练。为了最小化这种相关性,CLAWS Net[35]提出了一种随机批选择方法,在该方法中,可以任意选择时间一致的批次来训练二分类器。
2.3. Unsupervised VAD
无监督视频异常检测(US-VAD)方法使用未标注的训练数据进行学习。由于缺乏真实标签的监督以及异常的罕见性,这个问题极具挑战性。然而,它的回报也很高,因为它可以完全消除获取手动标注的成本,并允许这样的系统在没有人工干预的情况下部署。由于这个问题的难度,文献中对其的关注很少。生成式协作学习[36]是最近的一项工作,它提出了一个无监督视频异常检测系统,该系统首先训练一个生成模型来重建正常视频帧,然后利用重建帧与实际帧之间的差异作为异常的度量。它涉及同时训练两个模型:一个用于重建正常帧,另一个用于生成分类分数。
3. Proposed Methodology
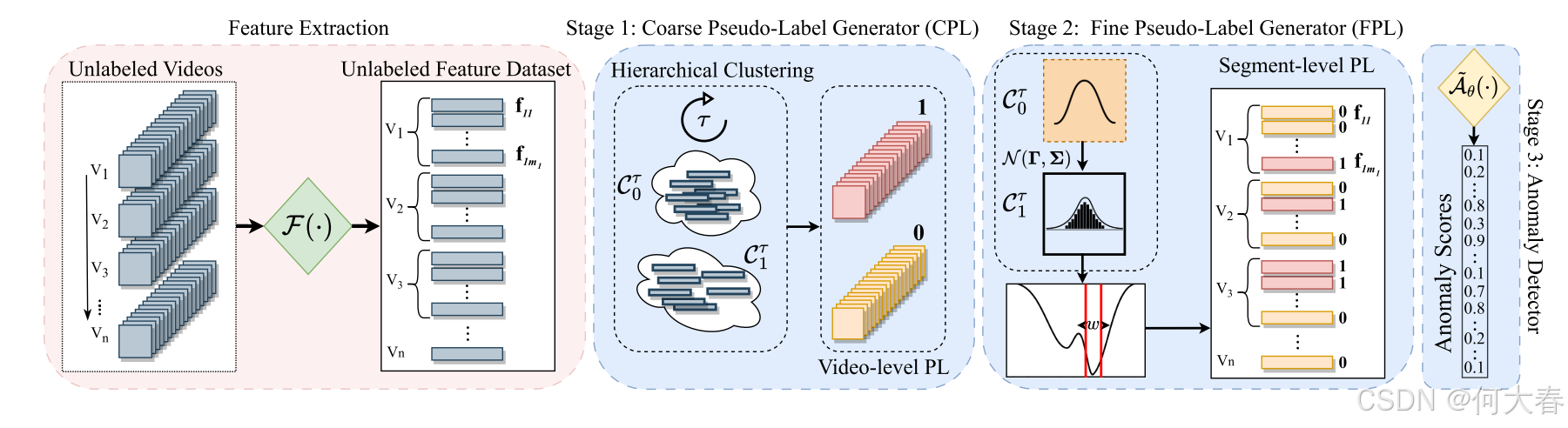
图2. 所提出的C2FPL框架用于无监督视频异常检测(US-VAD)的整体训练流程。首先,将所有训练视频划分为片段,每个片段由使用预训练特征提取器获得的特征向量表示。然后,我们的两阶段粗到细伪标签(C2FPL)生成器产生片段级别的伪标签,这些伪标签用于训练片段级别的异常检测器。伪标签的生成包括两个阶段:生成粗粒度(视频级别)伪标签(CPL)的层次分裂聚类,以及生成细粒度(片段级别)伪标签(FPL)的统计假设检验。
Problem Definition:设D = { V 1 , V 2 , ⋯ , V n V_1, V_2, ⋯, V_n V1,V2,⋯,Vn}是一个包含n个未标注视频的训练数据集。无监督视频异常检测(US-VAD)的目标是使用D来学习一个异常检测器 A ( ⋅ ) A(⋅) A(⋅),该检测器能够将给定测试视频 V ∗ V_* V∗中的每一帧分类为正常(0)或异常(1)。
Notations:我们将每个视频 V i V_i Vi分割成一系列 m i m_i mi个不重叠的片段 S i j S_{ij} Sij,其中每个片段又由r帧组成。请注意,i ∈ [1, n]表示视频索引,而j ∈ [1, m i m_i mi]表示视频内片段的索引。虽然许多弱监督视频异常检测方法[16, 19, 25, 30]会沿着时间轴将每个视频压缩成固定数量的片段(即 m i = m , ∀ i ∈ [ 1 , n ] m_i = m, ∀i ∈ [1, n] mi=m,∀i∈[1,n]),但我们避免了任何压缩,并使用了所有可用的不重叠片段。对于每个片段 S i j S_{ij} Sij,我们使用一个预训练的特征提取器 F ( ⋅ ) F(⋅) F(⋅)来获得一个特征向量 f i j ∈ R d f_{ij} ∈ \mathbb{R}^{d} fij∈Rd。
High-level Overview of the Proposed Solution:我们的粗到细伪标注(C2FPL)框架用于无监督视频异常检测(USVAD),在训练过程中包括三个主要阶段(见图2)。在第一个粗粒度伪标注(CPL)阶段,我们使用层次性分裂聚类方法为训练集中每个视频生成视频级伪标签 y ^ i ∈ { 0 , 1 } \hat{y}_i \in \{0, 1\} y^i∈{0,1}, i ∈ [ 1 , n ] i \in [1, n] i∈[1,n]。在第二个细粒度伪标注(FPL)阶段,我们通过统计假设检验为训练集中的所有片段生成片段级伪标签 y ~ i j ∈ { 0 , 1 } \tilde{y}_{ij} \in \{0, 1\} y~ij∈{0,1}, i ∈ [ 1 , n ] i \in [1, n] i∈[1,n], j ∈ [ 1 , m i ] j \in [1, m_i] j∈[1,mi]。在第三个异常检测(AD)阶段,我们训练一个片段级异常检测器 A ~ θ ( ⋅ ) : R d → [ 0 , 1 ] \tilde{A}_{\theta}(\cdot) : \mathbb{R}^d \rightarrow [0, 1] A~θ(⋅):Rd→[0,1],它基于视频片段的特征表示 f i j f_{ij} fij 为给定片段分配一个在0到1之间的异常评分(值越高表明异常的置信度越高)。
3.1. Coarse (Video-Level) Pseudo-Label Generator

由于训练数据集中不包含任何标签,我们首先通过递归聚类将训练集中的视频分为正常组和异常组来生成伪标签(见算法1)。利用迭代聚类生成伪标签的想法在其他应用领域中已被考虑过 [1, 4, 38]。然而,直接将这些方法应用于无监督视频异常检测(US-VAD)问题未能提供令人满意的解决方案,原因有两个。首先,直接对多变量特征 f i j f_{ij} fij 进行聚类会导致维度灾难(特征维数高但样本量少)。其次,在我们的场景中,聚类结果不具备排列不变性(正常和异常的聚类标签不能互换)。为了解决这些问题,我们提出了一种基于低维特征摘要和分裂层次聚类的方法。
先前的弱监督视频异常检测(WS-VAD)研究表明,与异常片段相比,正常视频片段的时间特征幅度较低 [26]。此外,我们还观察到,不同片段之间的特征幅度变化在正常视频中较小。基于这一直觉,我们用其特征的统计摘要
x
i
=
[
μ
i
,
σ
i
]
x_i = [\mu_i, \sigma_i]
xi=[μi,σi] 来表示每个视频
V
i
V_i
Vi,具体如下:
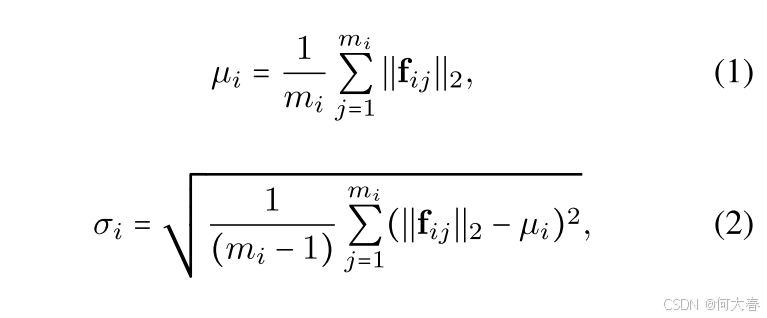
其中,
∥
⋅
∥
2
\|\cdot\|_2
∥⋅∥2 表示向量的
ℓ
2
\ell_2
ℓ2 范数。因此,每个视频
V
i
V_i
Vi 都使用一个二维向量
x
i
\mathbf{x}_i
xi 来表示,该向量对应于其各个片段特征幅值的均值和标准差。这样做可以确保所有视频尽管具有不同的时间长度,但都能获得统一的表示。
在训练集中,视频基于上述表示 x i \mathbf{x}_i xi 被迭代地分为两个聚类( C 0 t \mathcal{C}_0^t C0t 和 C 1 t \mathcal{C}_1^t C1t)。这里, t t t 表示步骤索引, C 0 \mathcal{C}_0 C0 和 C 1 \mathcal{C}_1 C1 分别代表正常和异常聚类。由于没有可用的数据标签,因此给聚类分配正常和异常标签并非易事。直观上,容易识别的异常(被视为容易识别的离群点)可能会被分到一个小聚类中。另一方面,较大的聚类可能包含更多的正常视频以及一些需要进一步细化的难以识别的异常。因此,最初,训练集中的所有视频都被分配到正常聚类中,而异常聚类被初始化为空集,即 C 0 0 = { x i } i ∈ [ 1 , n ] \mathcal{C}_0^0= \left \{ \mathbf{x}_i \right \}_{i\in [1, n]} C00={xi}i∈[1,n] 和 C 1 0 = ∅ \mathcal{C}_1^0=\varnothing C10=∅。在每一步 t ( t ≥ 1 ) t(t\geq1) t(t≥1),聚类 C 0 t − 1 \mathcal{C}_0^{t-1} C0t−1 被重新聚类以获得两个新的子聚类,称为 C l \mathcal{C}_l Cl 和 C s \mathcal{C}_s Cs,分别包含 ∣ C l ∣ |\mathcal{C}_l| ∣Cl∣ 和 ∣ C s ∣ |\mathcal{C}_s| ∣Cs∣ 个样本。不失一般性,假设 ∣ C s ∣ < ∣ C l ∣ |\mathcal{C}_s|<|\mathcal{C}_l| ∣Cs∣<∣Cl∣。较小的聚类 C s \mathcal{C}_s Cs 与前一个异常聚类合并,即 C 1 t = ( C 1 t − 1 ∪ C s ) \mathcal{C}_1^t=(\mathcal{C}_1^{t-1}\cup\mathcal{C}_s) C1t=(C1t−1∪Cs),而较大的聚类被标记为正常,即 C 0 t = C l \mathcal{C}_0^t=\mathcal{C}_l C0t=Cl。这个过程一直重复,直到异常聚类中的视频数量( ∣ C 1 t ∣ |\mathcal{C}_1^t| ∣C1t∣)与正常聚类中的视频数量( ∣ C 0 t ∣ |\mathcal{C}_0^t| ∣C0t∣)之比大于一个阈值,即 ∣ C 1 t ∣ ∣ C 0 t ∣ > η \frac{|\mathcal{C}_1^t|}{|\mathcal{C}_0^t|}>\eta ∣C0t∣∣C1t∣>η。在CPL阶段结束时,根据它们对应的聚类索引,训练集中的所有视频都被分配了一个伪标签,即如果 x i ∈ C k τ \mathbf{x}_i\in\mathcal{C}_k^\tau xi∈Ckτ,则 y ^ i = k \hat{y}_i=k y^i=k,其中 k ∈ { 0 , 1 } k\in\{0,1\} k∈{0,1}, τ \tau τ 表示最终聚类迭代的次数。
3.2. Fine (Segment-Level) Pseudo-Label Generator
在之前的阶段中被“伪标签”标记为正常( y ^ i = 0 \hat{y}_i=0 y^i=0)的所有视频片段均可视为正常。然而,由于异常的时间局部化特性,异常视频中的大部分片段实际上也是正常的。因此,为了生成异常视频的片段级标签,需要对粗粒度(视频级别)的标签进行进一步的细化。为了实现这一目标,我们将异常片段的检测视为一个统计假设检验问题。具体而言,原假设(null hypothesis)是一个给定的视频片段是正常的。我们通过将原假设下的特征分布建模为高斯分布,来识别异常片段,即估计其p值,如果p值小于显著性水平 α \alpha α,则拒绝原假设。
为了建模原假设下的特征分布,我们仅考虑由CPL阶段伪标签标记为正常的视频片段。设 z i j ∈ R d ~ \mathbf{z}_{ij}\in\mathbb{R}^{\tilde{d}} zij∈Rd~为片段 S i j S_{ij} Sij的低维表示。我们假设在原假设下, z i j \mathbf{z}_{ij} zij遵循高斯分布 N ( Γ , Σ ) \mathcal{N}(\boldsymbol{\Gamma},\boldsymbol{\Sigma}) N(Γ,Σ),并按下述方式估计参数 Γ \Gamma Γ和 Σ \Sigma Σ:
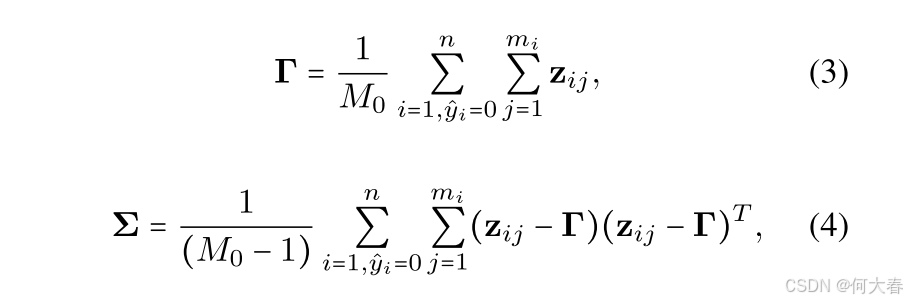
其中, M 0 = ∑ i = 1 , y ^ i = 0 n m i M_0=\sum_{i=1,\hat{y}_i=0}^nm_i M0=∑i=1,y^i=0nmi,表示所有被伪标签标记为正常的视频中片段的总数量。随后,对于所有被伪标签标记为异常的视频中的片段,其 p p p值计算方式如下:

对于所有 j ∈ [ 1 , m i ] j\in[1,m_{i}] j∈[1,mi]且 i ∈ [ 1 , n ] i\in[1,n] i∈[1,n]的情况,当 y ^ i = 1 \hat{y}_i=1 y^i=1时(即当视频 i i i被伪标签标记为异常时),如果 p i j < α p_{ij}<\alpha pij<α,则该片段可能被赋予伪标签1(即被视为异常片段)。图 3 \color{red}3 3展示了这一方法的示意图,它清晰地表明了估计的 p p p值与验证集的真实异常标签之间存在高度的一致性。
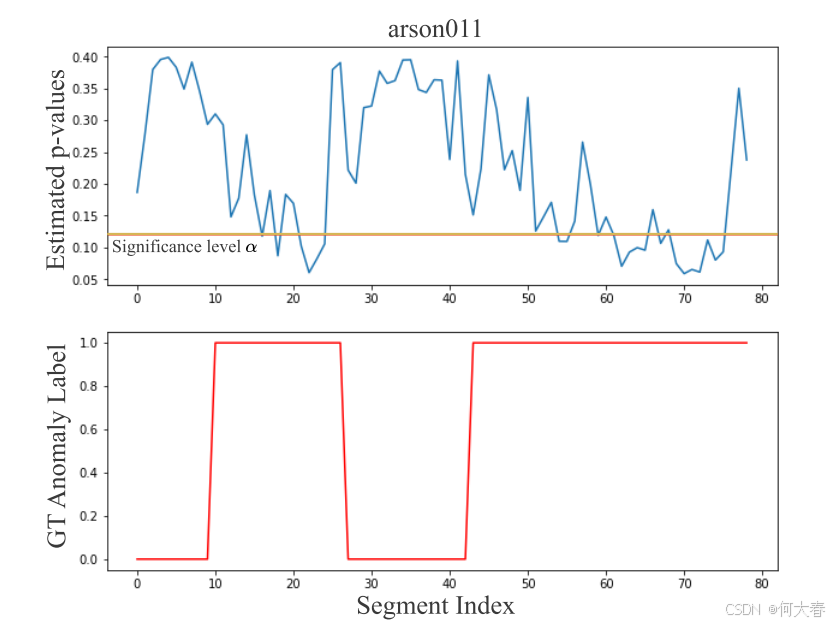
图3. 对验证集中异常视频arson011应用统计假设检验方法进行伪标签标注。第一行显示了视频中所有片段的片段级别p值,其中较低的p值意味着正常的可能性较小。一种可能的伪标签标注策略是将所有p值低于显著性水平(由水平橙色线表示)的片段标记为异常。可以观察到,在给定的视频(显示在最后一行)中,估计的p值与真实(GT)异常标签之间存在高度一致性。
在上述公式中,一个尚未解决的问题是如何为片段 S i j S_{ij} Sij获得其低维表示 z i j \mathbf{z}_{ij} zij。在本研究中,我们简单地设定 z i j = ∥ f i j ∥ 2 \mathbf{z}_{ij}=\|\mathbf{f}_{ij}\|_2 zij=∥fij∥2,因此 d ~ = 1 \widetilde{d}=1 d =1(即低维表示为一维)。需要注意的是,除了(或代替)二维特征的大小外,还可以采用其他统计量。
直接根据片段的 p p p值为其分配伪标签忽略了这样一个事实:视频中的异常片段往往是时间连续的。为了克服这一局限性,一种方法是在每个被伪标签标记为异常的视频中,标记一个连续的 w i = ⌈ β m i ⌉ w_{i} = \lceil \beta m_{i} \rceil wi=⌈βmi⌉片段序列(其中0 < β \beta β < 1, ⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉表示向上取整函数)作为异常区域。这个异常区域是通过一个大小为 w i w_i wi的窗口在视频上滑动,并选择具有最低平均 p p p值(即 min l { 1 w i ∑ j = ( l + 1 ) ( l + w i ) p i j , ∀ l ∈ [ 0 , m i − w i ] } \min_{l}\left\{\frac{1}{w_{i}}\sum_{j=(l+1)}^{(l+w_{i})}p_{ij}, \forall l \in [0, m_{i}-w_{i}]\right\} minl{wi1∑j=(l+1)(l+wi)pij,∀l∈[0,mi−wi]})的窗口来确定的。在这个异常区域内的每个片段都被分配伪标签1,而所有剩余的片段都被伪标签为正常(值为0)。在这个FPL(可能是“伪标签细化”或类似阶段的缩写)阶段结束时,训练集中的所有片段都被分配了一个伪标签 y ~ i j ∈ { 0 , 1 } \tilde{y}_{ij} \in \{0,1\} y~ij∈{0,1}。
3.3. Anomaly Detector
粗粒度和细粒度伪标签生成器共同为训练数据集中的每个视频片段提供了一个伪标签。这产生了一个包含
M
M
M个样本的伪标签训练集
D
~
=
{
(
f
i
j
,
y
~
i
j
)
}
\tilde{\mathcal{D}}=\left\{(\mathbf{f}_{ij},\tilde{y}_{ij})\right\}
D~={(fij,y~ij)},其中
i
∈
[
1
,
n
]
i\in[1,n]
i∈[1,n],
j
∈
[
1
,
m
i
]
j\in[1,m_i]
j∈[1,mi],且
M
=
∑
i
=
1
n
m
i
M=\sum_{i=1}^n m_i
M=∑i=1nmi。这个已标记的训练集
D
~
\tilde{\mathcal{D}}
D~可以通过最小化以下目标函数,以监督学习的方式用于训练异常检测器
A
~
θ
(
⋅
)
\widetilde{\mathcal{A}}_\theta(\cdot)
A
θ(⋅):
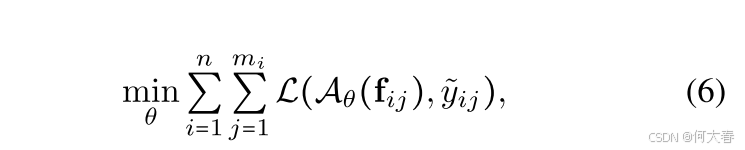
其中, L \mathcal{L} L是一个适当的损失函数, θ \theta θ表示异常检测器 A ~ ( ⋅ ) \tilde{\mathcal{A}}(\cdot) A~(⋅)的参数。
遵循最近的最先进方法[19,25,35,36],我们为我们的异常检测器考虑了两种基本的神经网络架构。特别是,我们采用了一个浅层神经网络(图2),该网络具有两个全连接(FC)隐藏层和一个映射到二进制类的输出层。在每个FC层之后,应用了一个dropout层和一个ReLU激活函数。此外,遵循Zaheer等人的方法[35],我们添加了两个自注意力层(详细架构见补充材料)。每个自注意力层之后都跟着一个softmax激活函数,每个自注意力层的维度都与主干网络中相应的FC层相同。最终的异常分数预测由输出层的sigmoid函数产生。
与许多现有方法(例如[19])需要将整个视频放入一个训练批次中不同,我们的方法允许随机选择片段进行训练。最近,Zaheer等人[35]证明了特征向量随机化对训练的好处。然而,根据其设计,他们的方法仅限于在保持批次内片段时间顺序的同时对连续批次进行随机化。在我们的情况下,由于我们已经为每个片段获得了伪标签,因此我们可以应用完全随机化的训练方式来获得最大收益。因此,我们从数据集中获取特征向量以形成训练批次。形式上,每个训练批次 B \mathcal{B} B包含从集合 D ~ \tilde{\mathcal{D}} D~中随机选择的 B B B个样本,样本之间没有任何顺序约束。
3.4. Inference
在推理阶段,给定的测试视频 V ∗ V_* V∗被划分为 m ⋆ m_{\star} m⋆个不重叠的片段 S ∗ j , j ∈ [ 1 , m ⋆ ] S_{*j}, j\in[1,m_{\star}] S∗j,j∈[1,m⋆]。使用 F ( ⋅ ) \mathcal{F}(\cdot) F(⋅)从每个片段中提取特征向量 f ∗ j \mathbf{f}_{*j} f∗j,这些特征向量直接传递给训练好的检测器 A ~ θ ( ⋅ ) \tilde{\mathcal{A}}_\theta(\cdot) A~θ(⋅)以获得片段级别的异常分数预测。由于最终目标是帧级别的异常预测,因此如果测试视频中某个片段的预测异常分数超过阈值,则该片段内的所有帧都被标记为异常。
4. Experimental Results
4.1. Experimental Setup
Datasets: Two large-scale VAD datasets are used to evaluate our approach: UCF-Crime [19] and XD-Violence [31].
Evaluation Metric:在我们的所有实验中,我们采用常用的帧级别接收者操作特征曲线(ROC曲线)下的面积(AUC)作为评估指标[19, 23, 25, 33–35]。请注意,ROC曲线是通过在推理过程中改变异常分数的阈值而获得的,AUC值越高表示结果越好。
Implementation Details:每个视频被划分为多个片段,每个片段包含 r = 16 r=16 r=16帧。我们使用著名的I3D[3]方法作为预训练的特征提取器 F ( ⋅ ) \mathcal{F}(\cdot) F(⋅),以提取维度为 d = 2048 d=2048 d=2048的RGB特征。遵循[22]的方法,我们还对I3D特征应用了10裁剪增强。粗粒度伪标签(CPL)生成器使用基于高斯混合模型(GMM)的聚类[17],并将阈值 η \eta η设置为1.0。细粒度伪标签(FPL)生成器中使用的参数 β \beta β被设置为0.2。异常检测器 A ~ θ ( ⋅ ) \tilde{\mathcal{A}}_\theta(\cdot) A~θ(⋅)使用二元交叉熵损失函数以及 ℓ 2 \ell_2 ℓ2正则化进行训练。检测器使用学习率为0.01的随机梯度下降优化器训练100个周期。批量大小 B B B设置为128。
4.2. Comparison with state-of-the-art
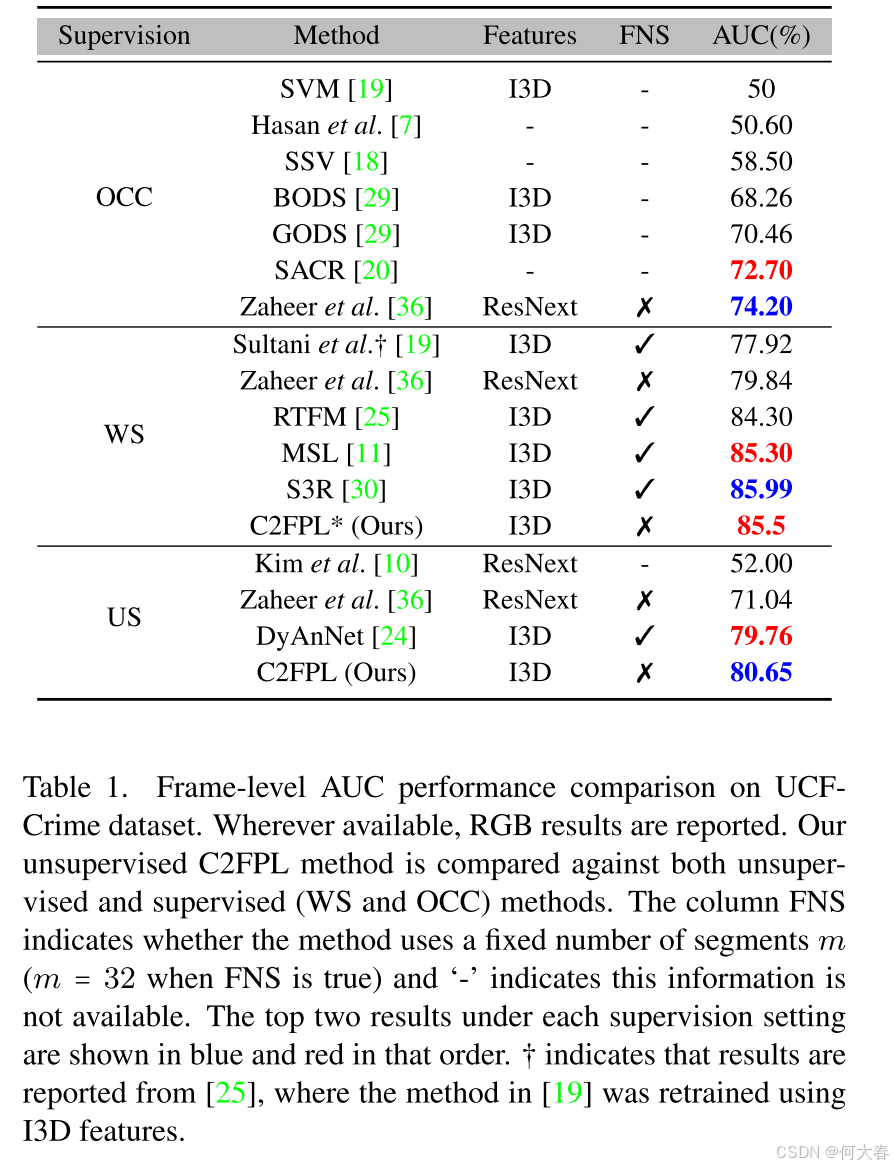
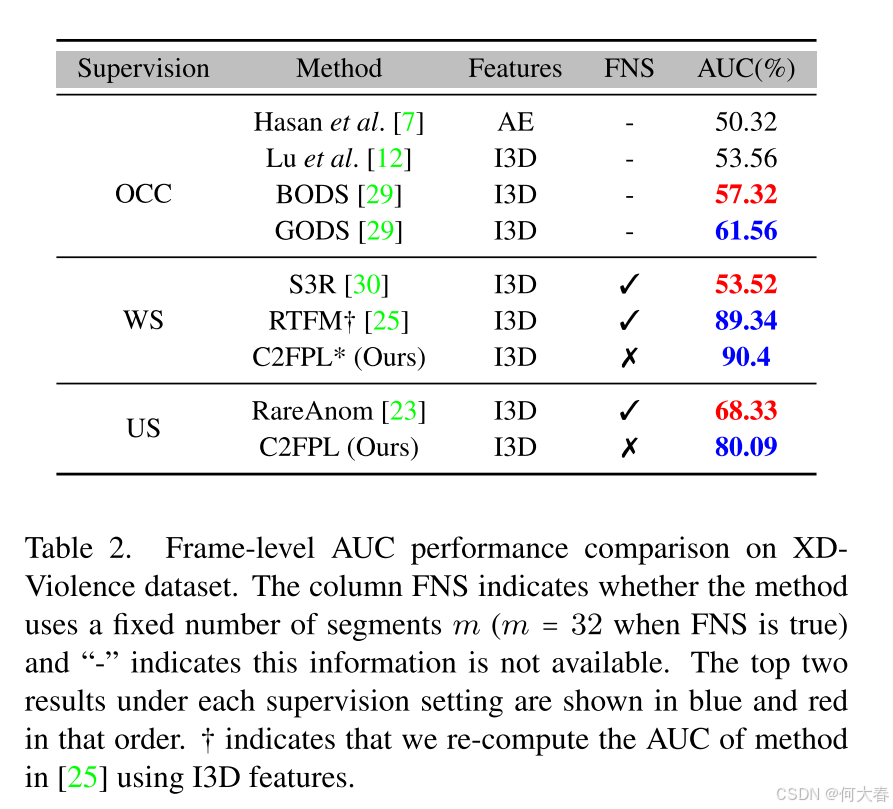
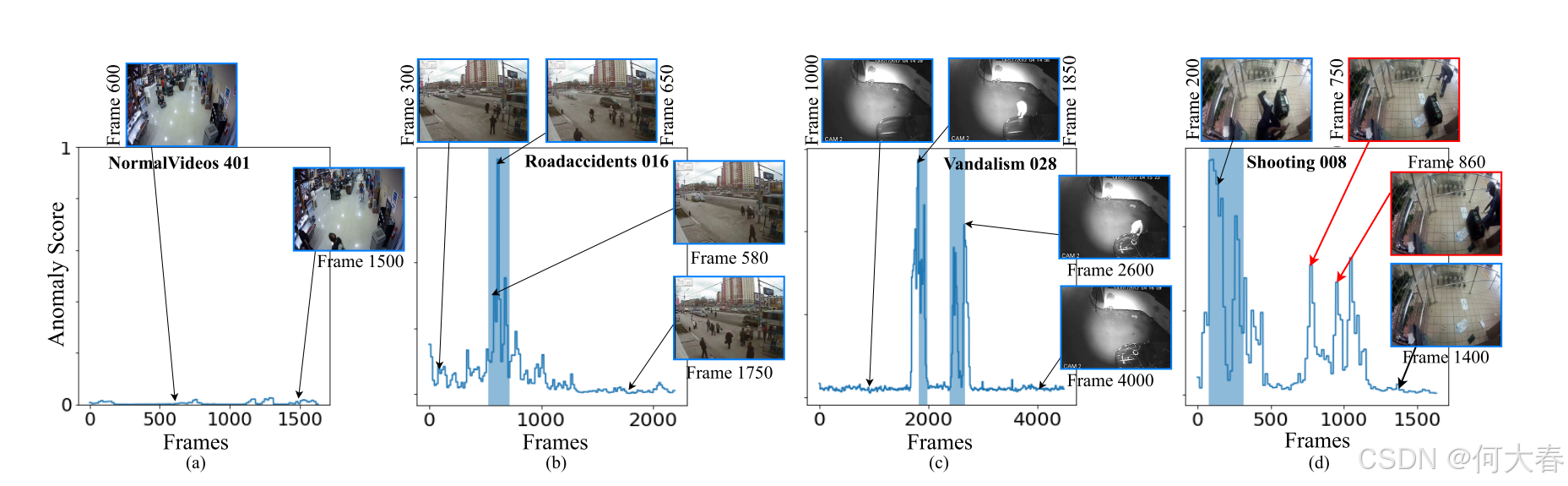
图4.我们的方法在UCF-Crime数据集的不同测试视频上的定性结果。蓝色阴影表示地面真实异常帧。
5. Conclusion
无监督视频异常检测(US-VAD)方法在现实应用中非常有用,因为可以无需任何标注或人工干预地训练一个完整的系统。在本文中,我们提出了一种基于两阶段伪标签生成器的无监督视频异常检测方法,该方法有助于训练一个片段级别的异常检测器。我们在两个大规模数据集XD-Violence和UCF-Crime上进行了大量实验,结果表明,所提出的方法可以成功地缩小无监督方法和有监督方法之间的差距。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









