










BUCK电路原理简析
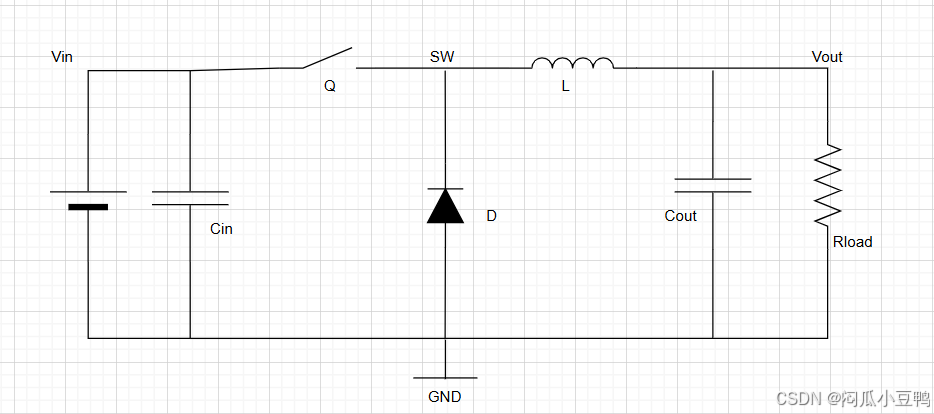
上图是一个异步BUCK电路拓扑图,我们先来简单回忆一下它是如何工作的:
1.Q闭合,Vin为Rload供电,Vin为L和Cout充电;
2.Q断开,L和Cout放电,为Rload供电,L通过D来进行续流;
写出Q闭合与断开时L两端的电压,再结合电感公式,可以画出稳态下电感中电流随时间变化的图像;进一步可以推导出秒平衡;这些内容在之前一篇文章中已经详细写过,不了解的读者可以先去看下那一篇文章:https://blog.csdn.net/weixin_44634860/article/details/141789867
重要的电感公式和电容公式
电感公式:

电容公式:

电感电流值计算
BUCK稳态时,L中电流随时间变化的图像:

BUCK稳态时,输出电压Vout几乎不变,输出电容Cout两端的电压也几乎不变,根据电容公式得,输出电容Cout输出的电流几乎为0,所以电感的输出平均电流≈负载的平均电流
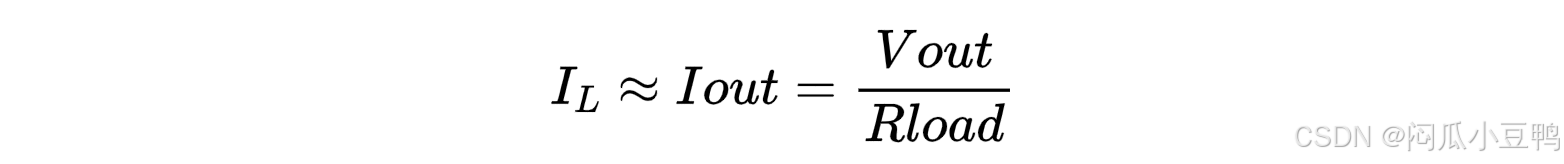
流过电感的平均电流已经知道,再计算出电感上的纹波电流Iripple,即可求出电感L上流过的最大电流;
一般DCDC输出电流纹波要求在输出电流的20%~40%;
所以稳态时流过电感的总电流为:
I
L
总
=
I
L
+
I
L
×
(
0.2
∼
0.4
)
≈
I
o
u
t
+
I
o
u
t
×
(
0.2
∼
0.4
)
=
I
o
u
t
×
(
1.2
∼
1.4
)
I_{L总} =I_{L}+ I_{L}\times \left ( 0.2\sim 0.4 \right ) \approx I_{out}+ I_{out}\times \left ( 0.2\sim 0.4 \right )= I_{out}\times \left ( 1.2\sim 1.4 \right )
IL总=IL+IL×(0.2∼0.4)≈Iout+Iout×(0.2∼0.4)=Iout×(1.2∼1.4)
疑问与解答
为什么我们要计算流过电感的电流值呢?求出后应该如何对电感的电流值进行选型呢?
因为电感一些关于电流的参数:饱和电流,温升电流,额定电流;
电感流过的电流值大于饱和电流时,电感进入磁饱和状态,电感量下降甚至失去电感特性,从而导致电路出现问题;大于温升电流时,电感器发热更严重,温升也会加快,甚至可能会烧毁电感;
一般情况下,会取饱和电流和温升电流中最小值的80%来作为额定电流;即:
I
L
额定
=
0.8
×
M
A
X
{
I
L
饱和
,
I
L
温升
}
I_{L额定}=0.8\times MAX\left \{ I_{L饱和}, I_{L温升} \right \}
IL额定=0.8×MAX{IL饱和,IL温升}
我们所选择电感的额定电流需要大于BUCK电路稳定时流过电感电流量的1.3倍;即:
I
L
额定
>
I
L
总
×
1.3
I_{L额定}> I_{L总} \times 1.3
IL额定>IL总×1.3
电感感值计算
同时,根据伏秒平衡,可知:
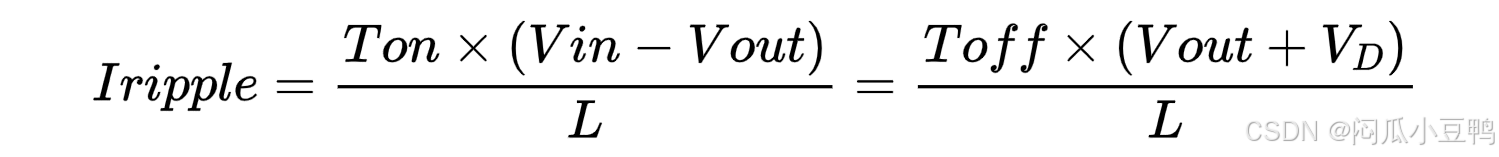
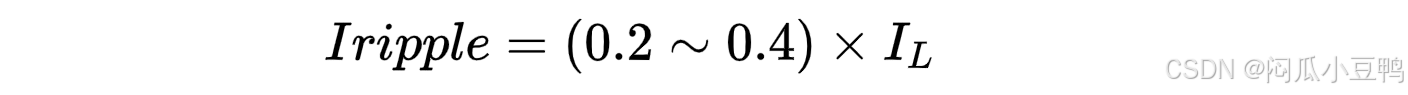
化简可得:
L
=
(
V
i
n
−
V
o
u
t
)
×
(
V
o
u
t
+
V
D
)
(
0.2
∼
0.4
)
×
I
L
×
f
×
(
V
i
n
+
V
D
)
≈
(
V
i
n
−
V
o
u
t
)
×
(
V
o
u
t
+
V
D
)
(
0.2
∼
0.4
)
×
I
o
u
t
×
f
×
(
V
i
n
+
V
D
)
L=\frac{\left ( Vin-Vout \right ) \times \left ( Vout+V_{D} \right ) }{\left ( 0.2\sim 0.4 \right )\times I_{L} \times f\times \left ( Vin+V_{D} \right ) } \approx\frac{\left ( Vin-Vout \right ) \times \left ( Vout+V_{D} \right ) }{\left ( 0.2\sim 0.4 \right )\times Iout \times f\times \left ( Vin+V_{D} \right ) }
L=(0.2∼0.4)×IL×f×(Vin+VD)(Vin−Vout)×(Vout+VD)≈(0.2∼0.4)×Iout×f×(Vin+VD)(Vin−Vout)×(Vout+VD)
当使用同步BUCK电路时,续流二极管的压降就可以忽略掉,即:
L
=
(
V
i
n
−
V
o
u
t
)
×
V
o
u
t
(
0.2
∼
0.4
)
×
I
L
×
f
×
V
i
n
≈
(
V
i
n
−
V
o
u
t
)
×
V
o
u
t
(
0.2
∼
0.4
)
×
I
o
u
t
×
f
×
V
i
n
L=\frac{\left ( Vin-Vout \right ) \times Vout}{\left ( 0.2\sim 0.4 \right )\times I_{L} \times f\times Vin} \approx\frac{\left ( Vin-Vout \right ) \times Vout}{\left ( 0.2\sim 0.4 \right )\times I_{out} \times f\times Vin}
L=(0.2∼0.4)×IL×f×Vin(Vin−Vout)×Vout≈(0.2∼0.4)×Iout×f×Vin(Vin−Vout)×Vout
其中Ton与Toff的值同样在之前的文章中有详细计算过程,不再赘述;
由上述式子可以计算出一个电感感值的范围,在这个感值范围的电感可以使得输出电流的纹波在20%~40%这个区间内;
疑问与解答
为什么计算出电感感量在一个范围内?选择电感值足够大的电感使得输出纹波小于20%会有什么问题么?
所选电感感值过大时,输出纹波较小,电路动态响应较差,环路稳定性较好;
所选电感感值过小时,输出纹波较大,电路动态响应较好,环路稳定性较差;
为了平衡BUCK电路这几个性能,我们一般会选择输出电流纹波在输出电流的20%~40%;
总结
我们在设计BUCK电路时,首先要根据需求计算出电流值与电感值,然后再跟待选电感的参数进行比对,二者都符合要求才能进行选择;挑选出多个符合要求的电感后再根据价格,封装等其他因素综合考虑进行选型;最终以实测结果为主。

















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









