






培训通知
Nhanes数据库数据挖掘,快速发表发文的利器,你来试试吧!欢迎报名郑老师团队统计课程,4.20直播。
潜在剖面模型
本文是潜变量文章第5篇。
大家是不是手头有的数据都是一堆定量数据(年龄、血压、血脂、血糖、BMI……),如果按照正常写文章的套路,只要这些不是自变量因变量,就只能出现在表1里统计描述里,没有了其他价值。
所以,能不能换一个思路,重新利用起来这些数据呢?
假如我根据这些数据将人群分类了呢?
那我就可以得到年轻亚健康组(年纪小但有三高);身体健康组(年纪大但没有三高);老年亚健康组(年纪大有三高)。根据这个分类,是不是又可以产出一篇文章啦!
按照常规套路,应该先介绍一下潜变量、显变量之类的,但是弯弯绕绕一大堆也不太理解,
本文就去掉定义,你就只需要知道:
潜在剖面模型:针对横断面数据,把多个定量数据变为几个分类,也就是把人群重新分组,然后接下去该用logsitic/线性等统计方法就该用哪种统计方法来分析。
至于具体是几分类,数据放进去,代码跑出来的结果自然会告诉你!
一、文献案例介绍
今天要介绍简单的中文文献。
本公众号回复“ 沙龙 ”即可获得R语言代码,PPT,数据等资料 |
1.1 文章介绍
我们略过其他的,直接看关于潜在剖面模型的重点。文章是根据短视频成瘾量表的四个维度得分,也就是4个定量数据在来把人群分类。
1.2 统计学方法
这里讲了每个指标的情况,也就是用这些指标来判断具体分几个剖面(分几类)
①赤池信息准则(AIC)、贝叶斯信息准则(BIC)和校正后aBIC的值越小,则模型的拟合越好;
②LMR和BLRT两个指标的P<0.05时,表明k个类别的模型显著优于k-1个类别的模型;
③Entropy的值达到0.80以上时表明分类的精准性较高,越接近于1表明分类的可信度越高。

1.3 文章结果展示
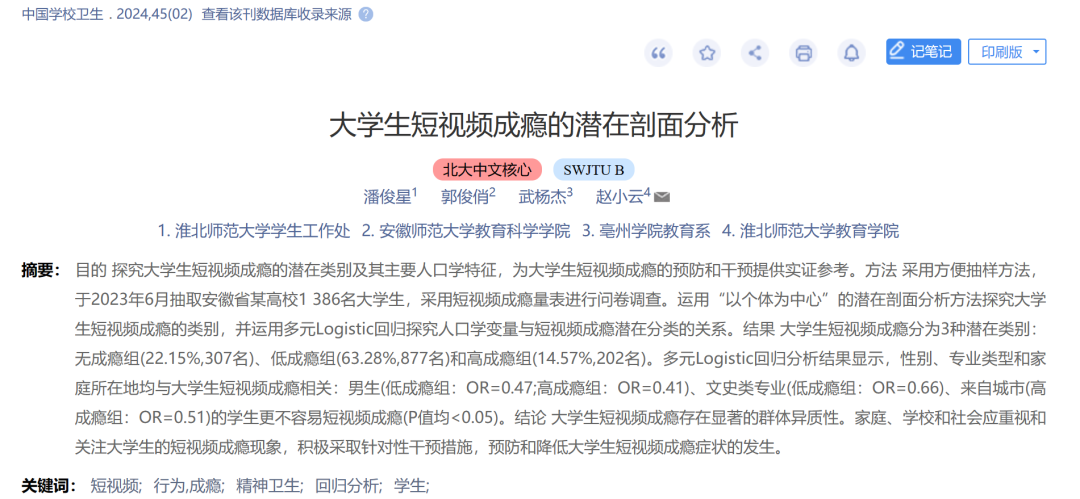
研究结果表明,以1分类模型为基础,逐渐增加剖面数量,探索1~6分类的潜在剖面,各模型的适配度拟合指标见表1。
AIC、BIC、aBIC值随分类数增加而逐渐减小
BLRT所有模型均提示有统计学意义(P值均<0.01)
LMR在2,3,5分类模型中有统计学意义(P值均<0.01),4和6分类模型LMR无统计学意义(P值均>0.05),故排除;
2和5分类模型的Entropy值<0.8,也予以排除。
综上,选择3分类模型(C1、C2、C3)为最佳剖面模型。
这部分介绍就写的很详细啦,大家按照这样的流程,再结合自己专业分组情况综合判断哦!
二、R语言演示
本次演示包括的统计学方法有:
查看数据有无缺失
查看数据应该分几个剖面(分几类)
拟合模型
画图
整合数据
因为潜在剖面模型的公共数据库的文章比较少,所以这次就没办法复现,只能用普通的数据来做啦,这次的数据跑出来的结果不是特别有代表性,但是说不定换上你们自己的数据各个结果都很好看哦!
(注:本公众号回复“沙龙”即可获取R语言代码)
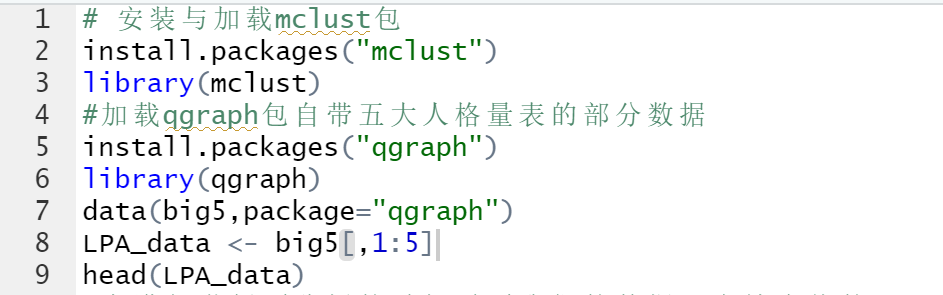
2.1 首先,加载R包和导入数据。
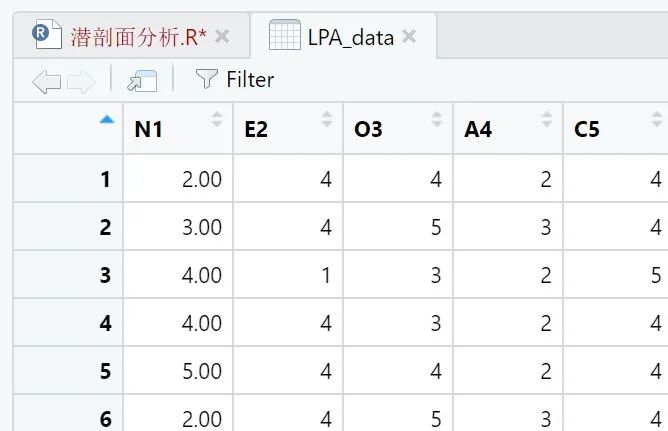
首先,安装需要的包,接下去导入从qgraph包自带五大人格量表的部分数据,数据一共500行。
2.2 查看数据有无缺失
潜在剖面模型要求数据无确失,所以先查看一下数据是不是有缺失的,可以看到整个数据都是没有缺失的。


2.3 探索一下对于我们的数据我们应该分为几个剖面(几类)
①根据BIC

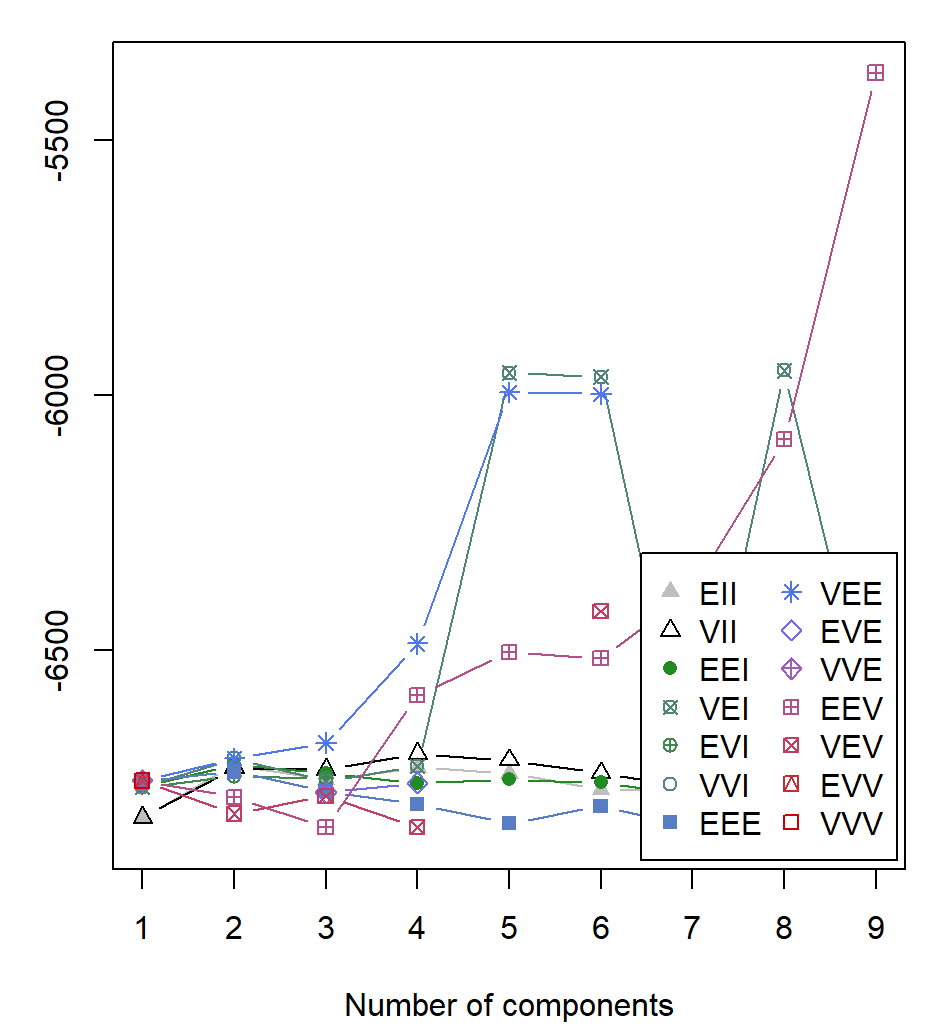
结果就是下图这样了,是不是有点开始看不懂了,其实初学者不用管什么EEV还是VEI等,你可以理解为这些都是不同模型罢了。
只需要关注逗号后面是9,说明它建议你分为9分类。

②根据ICL

运行结果如下:

结果ICL的结果跟前面BIC做出来的一致,都是建议我们把数据分为9类
③根据BLRT
前面都是EEV的方式做出来的9分类,所以这个红框框部分就写“EEV”

运行结果如下:

建立这里就需要解释了,1分类和2分类比有差异,2分类和3分类比没有差异,所以其实分为2分类是BLRT建议我们的最优选择。
但是前面也说了这个数据不典型,如果数据好的话,这里会跟前面BIC和ICL结果一致的。
具体分几类是综合考虑的结果,这些模型拟合告诉你的数据互相比较,结合自己的专业领域的分类,选出最佳的就可以。那我这里就先选9分类啦,我们接着往下。
(注:本公众号回复“沙龙”即可获取R语言代码)
2.4 拟合模型
这里的9和EEV是前面已经解释过的啦,LPA_md可以自己命名

运行结果如下:
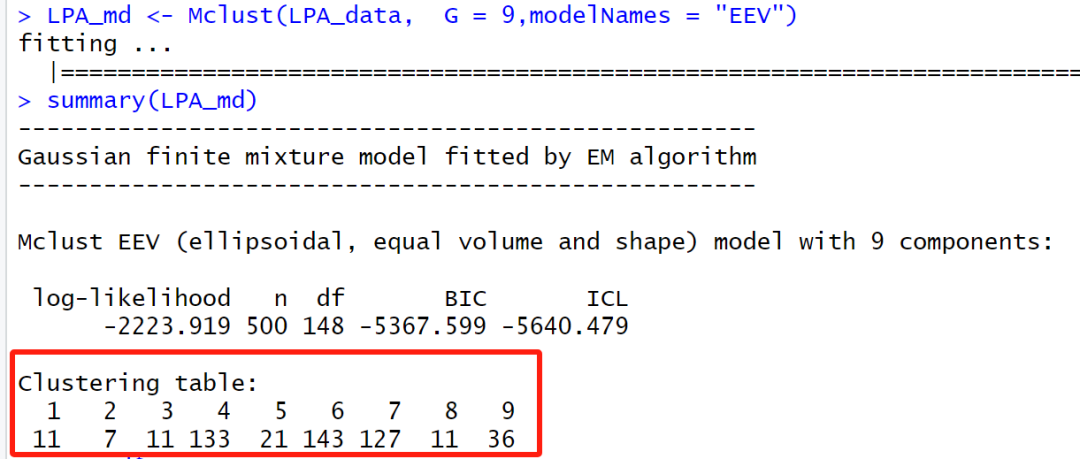
然后,这里就是可以看到9分类,每一类里面的具体样本量。
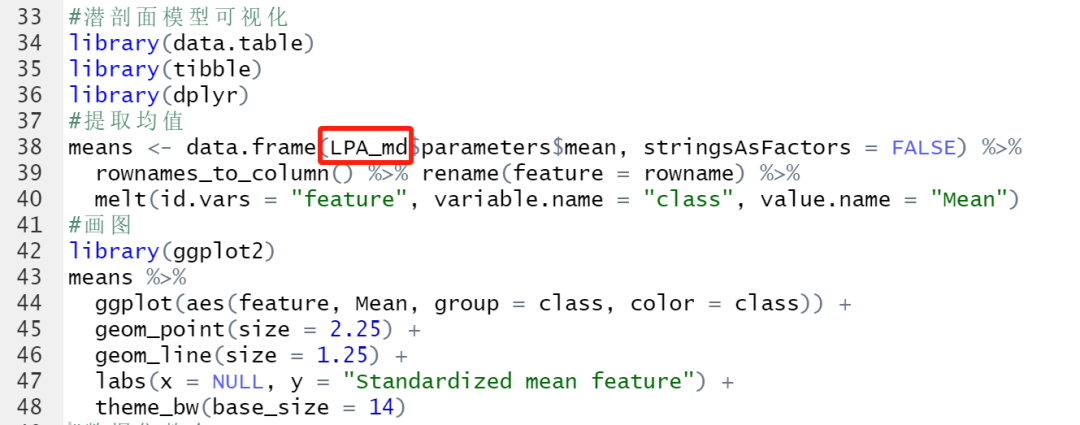
2.5 画图
提取均数是因为要根据均数来画图,其他所有都不用动,把你的数据集名称填在这就可以啦
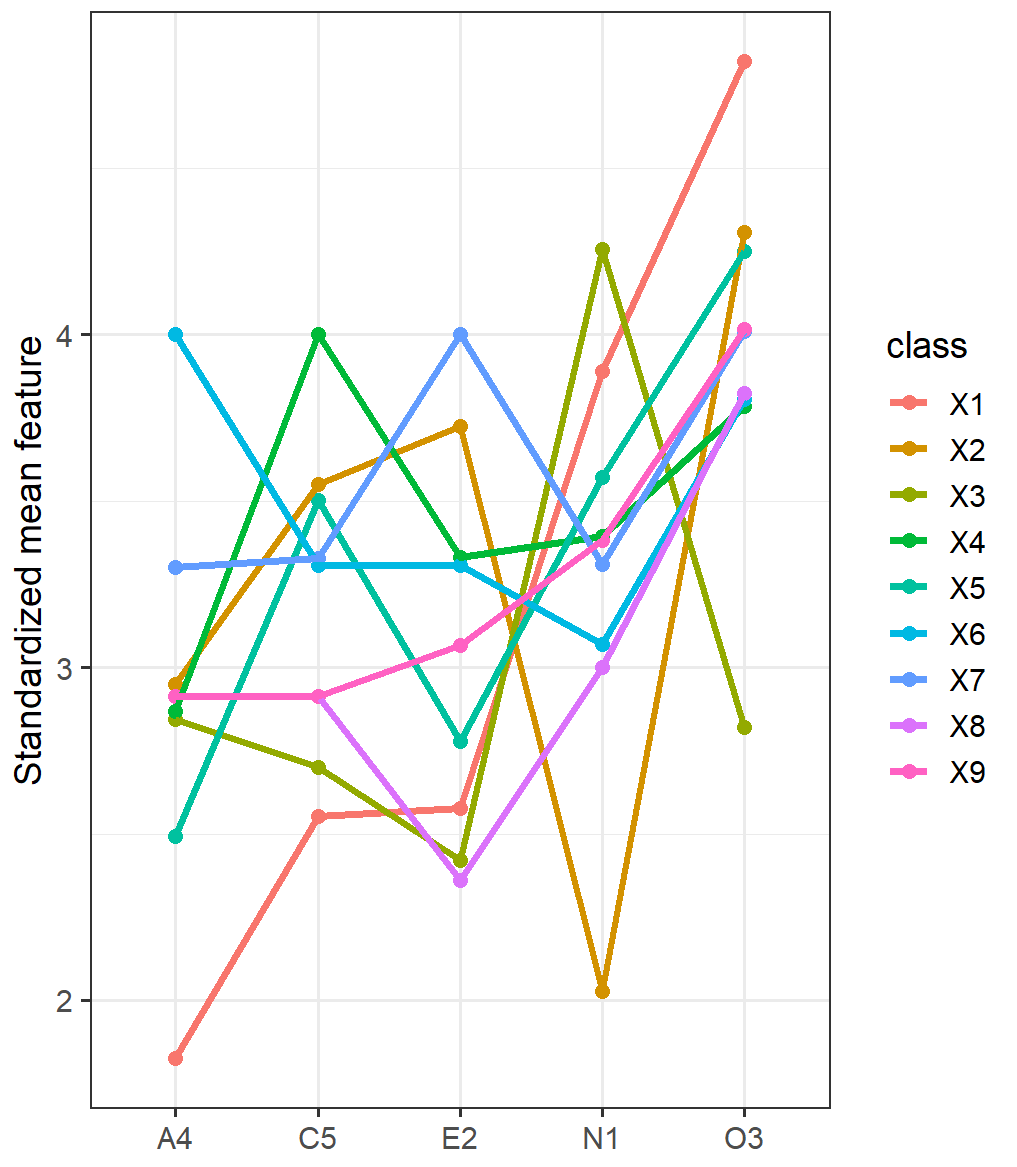
运行结果如下:
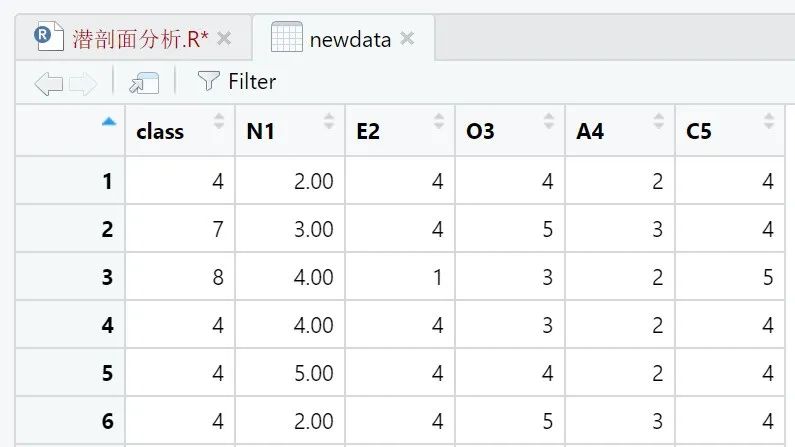
2.6 数据集整合
最后,把分类放进原来数据集里,你就能看到每行数据在哪一类了。

本公众号回复“ 沙龙 ”即可获得R语言代码,PPT,数据等资料 |
本公众提供各种科研服务了!
一、课程培训 2022年以来,我们召集了一批富有经验的高校专业队伍,着手举行短期统计课程培训班,包括R语言、meta分析、临床预测模型、真实世界临床研究、问卷与量表分析、医学统计与SPSS、临床试验数据分析、重复测量资料分析、nhanes、孟德尔随机化等10余门课。如果您有需求,不妨点击查看: 二、数据分析服务 浙江中医药大学郑老师团队接单各项医学研究数据分析的服务,提供高质量统计分析报告。有兴趣了解一下详情: |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









