







【欢迎阅读浙中大郑老师撰写的统计科普文】
回归分析是观察性研究中很重要的手段,通过模型调整,其目的是探讨多因素情况下,各个因素的独立效应。
那么,困惑诸多分析者的问题是,调整模型,也就是多因素回归分析,只能纳入单因素P<0.05的变量吗?
这个问题其实郑老师很早就回答过了,筛选自变量,最简单的方式、也最常见的方式是“先单因素后多因素法”,这种方法,郑老师上课也推荐给非统计学专业的医学生,不是说它是最好的方法,而是它最简单粗暴、最容易上手。
“先单后多”即先开展单因素回归,筛选出P值较小者一起纳入多因素回归模型。所以说,并不是完全按照单因素P<0.05作为严格标准纳入变量。
我们今天来看看这篇JAMA子刊的文章是如何做的?在方法学和结果中又是如何表述的呢?
原文阅读
发表在期刊《JAMA Network Open》(医学一区top,IF=10.5)的基于人群的队列研究,研究团队旨在确定首次(或基线)创伤入院后新发心理健康疾病的发生率,并评估其对长期健康结局的影响。

研究中Cox比例风险回归用于分析创伤后自杀、全因死亡率及创伤再入院的相关因素。Logistic回归用于分析创伤后新发心理健康疾病的相关因素。
在Cox回归及Logistic回归分析中,协变量的选择仅限与结局生物学上可能相关的因素,并剔除P>0.25的变量,以构建最终的简约模型(parsimony model)。

多因素Cox回归结果显示,创伤后新发心理健康疾病与以下结局显著相关:
创伤再入院(调整后风险比 [aHR]1.30;95%置信区间[CI]1.23-1.37;P<0.001)
自杀(上吊或药物过量)(aHR 3.14;95% CI:2.00-4.91;P<0.001)
全因死亡率(aHR 1.24;95% CI:1.12-1.38;P<0.001)
以上结果已调整年龄、性别及基线创伤入院前是否已有心理健康疾病。
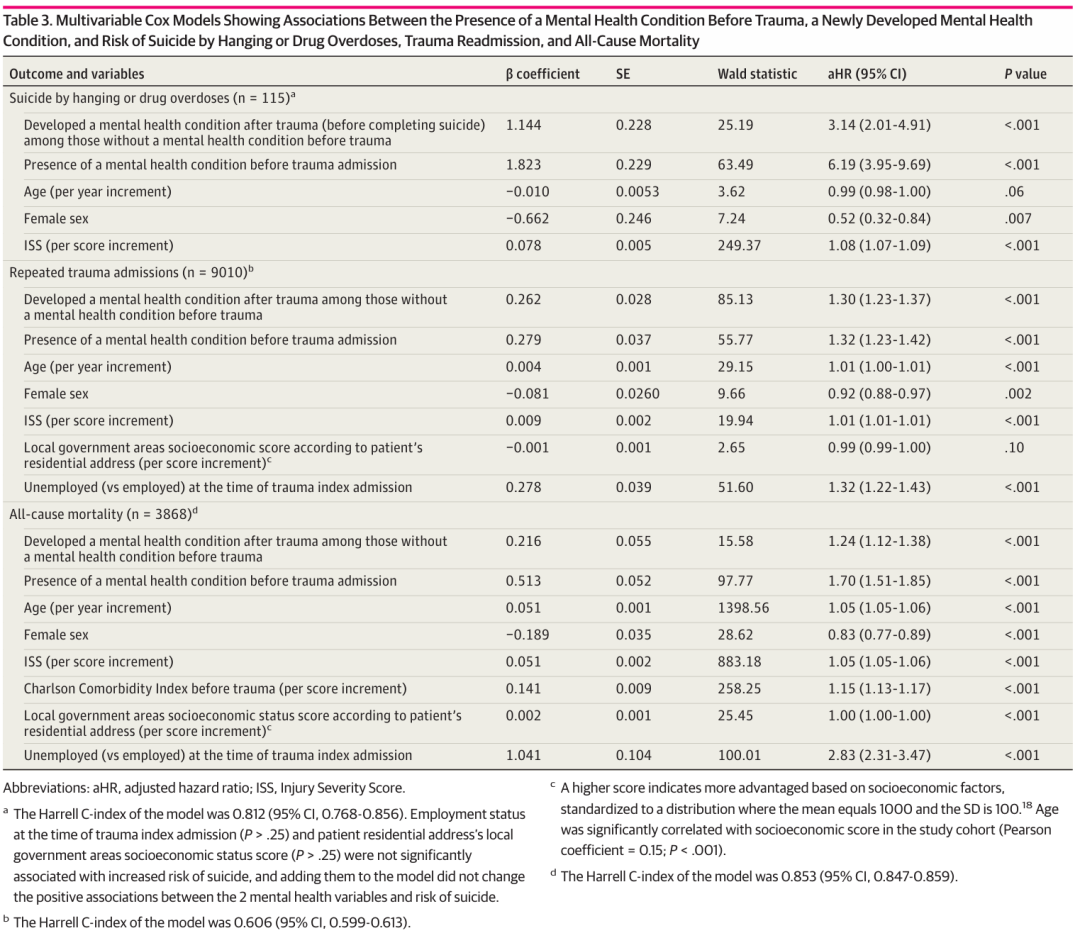
在26,958名基线无心理健康疾病的患者中,多因素Logistic回归分析显示,以下因素与创伤后新发心理健康疾病显著相关:
年轻
失业
单身、离婚或分居(vs 已婚)
土著族裔
较低的社会经济地位
创伤性脑损伤
多因素logistic回归结果放在了附录中。
所以,并不是一定要P值<0.05才纳入多因素回归模型!
老郑小评
在具体的处理上,可以采用"严进严纳" 的理念进行自变量筛选。老郑很早之前“30天学会医学统计学”公益课就已经讲过,现在带大家回顾一下!
严纳!挑选少量的自变量进入模型。严纳的方式很多,对于初学者,简单粗暴而且被认可的方法就是把单因素分析P值较小者纳入到回归模型中来。
(1)很多变量虽然单因素回归分析P>0.05,也有可能多因素回归P≤0.05。所以,不能就卡在0.05的界限。个中原因我就不多说了!
(2)如果你的自变量非常重要,特别是核心变量,哪怕单因素分析P较大,也值得多因素回归放进去分析
(3)很多时候自变量个数也就是3~5个,而样本量较大,这个时候根本不怕自变量太多,没有必要先单因素后多因素。
在不同的情况下,采用不同的纳入标准,仅供参考:
第一种:全部纳入
这种方法要求自变量较少,自变量之间关系简单,多重共线性不严重。一般情况下,自变量个数不太多(比如少于10个),且样本量是自变量个数20倍以上,可以采用本方法。
第二种方法:单因素筛选纳入(P值较小者,P≤0.2或者≤0.1)
这种方法要求自变量不是那么多,但样本量也不是那么大,因此可以考虑先单因素后多因素回归的方法。P值不要过于严格,一般P<0.2就可以了!
第三种方法:单因素筛选纳入(P值较小者,P≤0.05)
这种方法出现在自变量非常多几十个上百个,单因素分析P≤0.05者超过10个以上(P≤0.2的自变量更多了)。这种情况下,严格控制多因素回归自变量个数。P≤0.05者纳入多因素回归分析中。
所以,在你的文章中,真实的说明自变量筛选方法,是可行的,可以参照这篇推文所介绍的JAMA子刊文章中的方法和结果的表述!
观察性研先单后多的自变量筛选,目前非好的操作软件,是郑老师开发的免登录、免费Zstats风暴统计在线平台,它可以同时开展先单后多,设定不同的P值,并将单因素和多因素回归一起结合起来,快速形成三线表。欢迎使用。

【感谢阅读浙中大郑老师撰写的统计科普文】
关于郑老师团队及公众号
大型医学统计服务公众号平台,专注于医学生、医护工作者学术研究统计支持,我们是你们统计助理
我们开展对临床预测模型、机器学习、医学免费数据库NHANES、GBD数据库、孟德尔随机化方法、MIMIC一对一R语言指导开展统计分析(一年内不限时间,周末、晚上均统计师一对一指导)。
①指导学习R语言基本技巧
②全程指导课程学习
③课程R语言代码运行bug修复
④支持学员一篇SCI论文的数据分析
联系助教小董咨询(微信号aq566665)

















 3756
3756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









