






本篇是风暴统计平台教程系列的第11章。在实际应用中,说到控制混杂,大家第一个想到的可能就是"回归分析"。今天我们介绍另一种控制混杂的方法——倾向性得分匹配。
首先,一句话介绍倾向性得分匹配(PS法)的核心原理:通过将多个混杂因素的影响用一个综合的倾向得分来表示,以降低协变量的纬度(n→1),减少自变量的个数,从而解决分组不均衡困境,控制统计分析的混杂因素干扰。
这样做的好处是可以有效克服多因素回归分析中要求自变量个数不能太多的短板(例如10EPV原则等)。
在协变量不多的情况下,回归法与PS法差别不大,当样本量较少或自变量较多的情况下,可以考虑使用倾向性得分匹配法。
下面我们继续介绍风暴统计平台实现倾向性得分匹配法的步骤。

01
匹配前分组差异性分析
这里分组变量选入的研究因素或者是暴露变量,或病例与对照分组。(注意:不是结局变量!!)
下面根据可能的混杂因素类型不同,分别选入正态变量、偏态变量、分类变量。
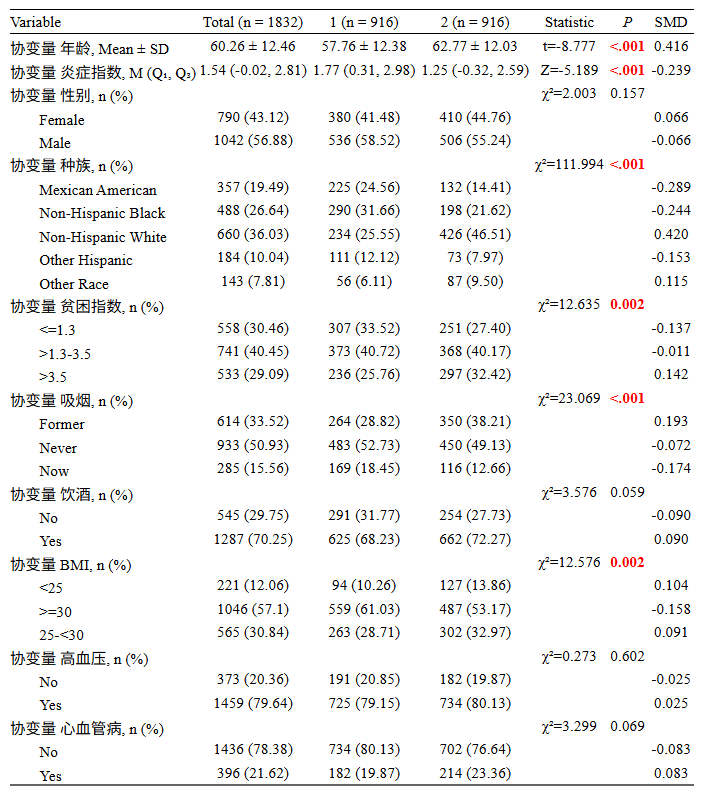
接着,点击分析,就会得到我们匹配前的基线差异性分析表。与常规分组差异性分析表差不多,多出一列SMD。
标准化均差(Standardized Mean Difference,SMD),SMD 越小则表示该协变量的两组均值差异越小。当SMD小于0.1时(不考虑正负),可认为组间协变量的均衡性较好。
在PSM过程中,SMD相较于P值,不仅能量化差异,并且结果与样本大小无关,更稳健。
02
倾向性得分匹配
然后来到最关键的一步,倾向性得分匹配即将暴露/处理组与对照组研究对象按照倾向得分(Propensity Score)进行匹配,以保证两组均衡可比,下面我们详细介绍各参数:
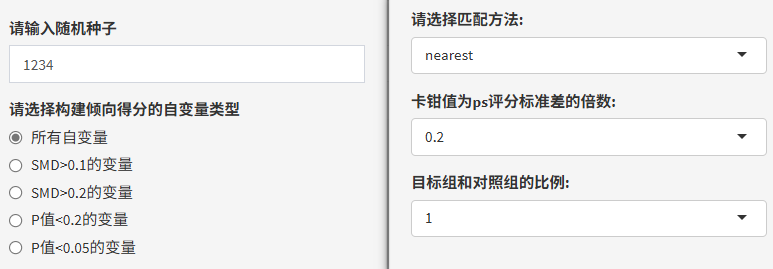
①随机种子
可以随便填入几个数字,目的是为了结果能够复现。例如病例组的个案A在对照组可能有多个相近倾向得分的B、C、D满足匹配条件,相同随机种子可以保证每次个案A都可以匹配到个案B。
②构建倾向得分的自变量类型
这里提供了5种方式,有点类似先单后多回归分析中,自变量进入多因素模型前的筛选。
可以都尝试看看,比较不同方法的匹配结果,样本量是否尽量保留,匹配后各变量是否大致均衡。
倾向得分(Propensity Score)的计算原理 这里用到了logistic回归,会以暴露(处理)因素为因变量(Y),潜在混杂因素作为自变量(X)构建logistic模型,并根据拟合的回归方程计算每个个体倾向得分(预测概率)。 然后以倾向得分为依据,通过匹配方法来凑出配对。 |
③匹配方法
nearest:最近邻匹配,优先选择距离最近的个体,适合大部分的场景。可选卡钳值、匹配比例。
full:全局最优匹配,最大限度利用样本,复杂度略高。可选卡钳值。
optimal:最优匹配,基于整体距离最小的方案匹配,匹配质量更高但比较耗时。可选匹配比例。
subclass:子分类匹配,按照倾向评分将样本分为若干层级,在层内比较治疗效果,常用于分层评估而非一对一匹配,适合观察性研究。可选匹配比例。
genetic:遗传匹配,通过遗传算法自动寻找最优匹配组合,适合复杂数据,计算比较复杂,出结果慢。可选匹配比例。
不同匹配方法,设置的参数也不同,主要是卡钳值、目标组和对照组匹配比例。
卡钳值为ps评分标准差的倍数
卡钳值限制了两组人群根据PS值进行匹配时所允许的误差范围,有0.05、0.1、0.2、0.25几种常见的选择。
卡钳值越小,匹配的越精准,但相对的样本量损失会更多;卡钳值越大,能够匹配成对的样本越多,但也容易出现匹配后不均衡的情况。因此需要多尝试从中找到平衡。
目标组和对照组的匹配比例
指定每个处理组个体匹配多少个对照组个体,通常是1:1,如果两组的入组人数差距悬殊(比如罕见病),也可以选择2倍、3倍、4倍的比例进行匹配,尽量保留样本。
在实战中,如果一种方法效果不好,可以再尝试其他方法。
设置完毕后,就得到匹配后数据的差异性分析结果,可以看到最终SMD基本都小于0.1。
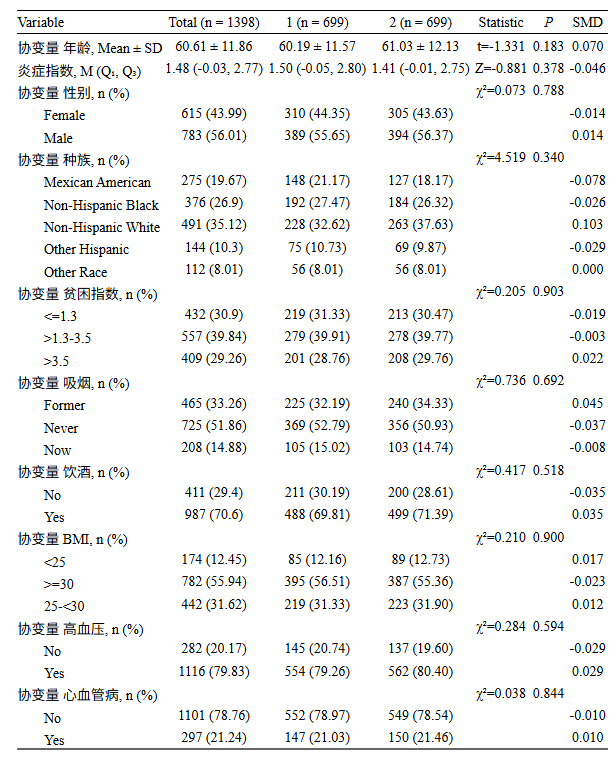
03
匹配前后结果展示
①可视化展示
平台提供了两种可视化展示:概率密度分析图(下)、SMD分析图(上)。前者重合程度越高,说明匹配后数据均衡性越好;后者可以观察蓝色散点分布,大致位于0~0.1区间,说明数据比较均衡。
还有其他图像细节调整设置,概率密度分析图(左)、SMD分析图(右)。大家使用过程中可以多尝试各个参数,就可以得到多样化的图像。
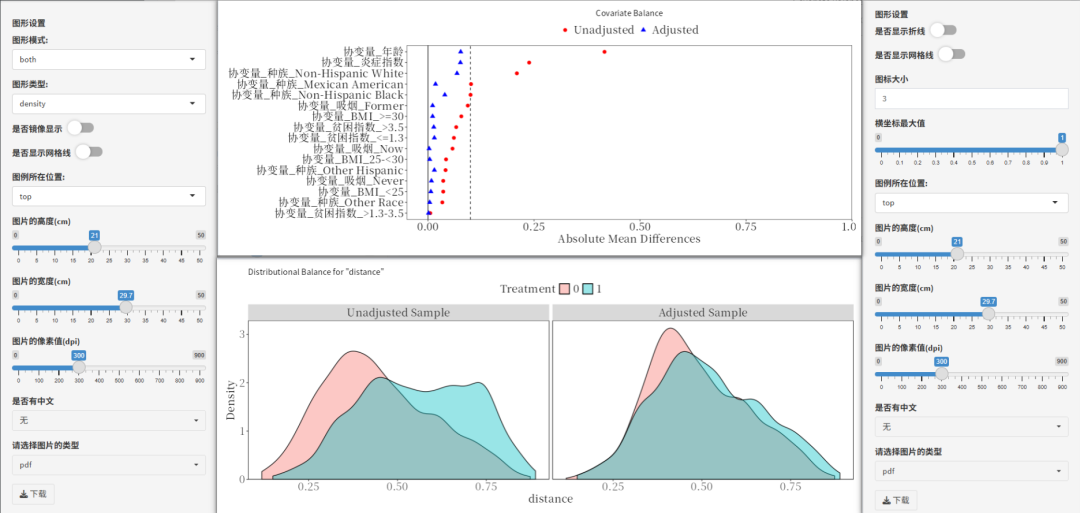
②匹配前后统计分析表
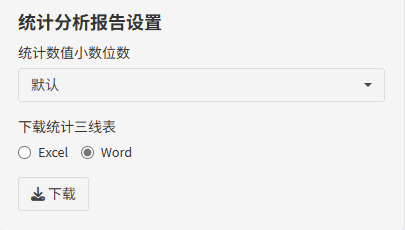
匹配前后的差异性分析还提供了合并三线表,结果对比更加直观。这部分结果也支持下载excel格式或者word格式。
③下载匹配后数据集
对于匹配后生成的新数据集,平台也支持下载。
04
匹配后分析
匹配后的数据大部分协变量已经分组均衡,也可能会有个别变量依旧不均衡。接着我们就通过回归分析,进一步研究暴露与结局的关系。
同时,因为匹配后的数据会面对2个问题:第一,样本量减少;第二,匹配带来了数据的聚集性,造成数据不独立。因此,用到的回归方法也会有所不同,下面我们根据不同结局用到的回归方法不同,分开进行说明。
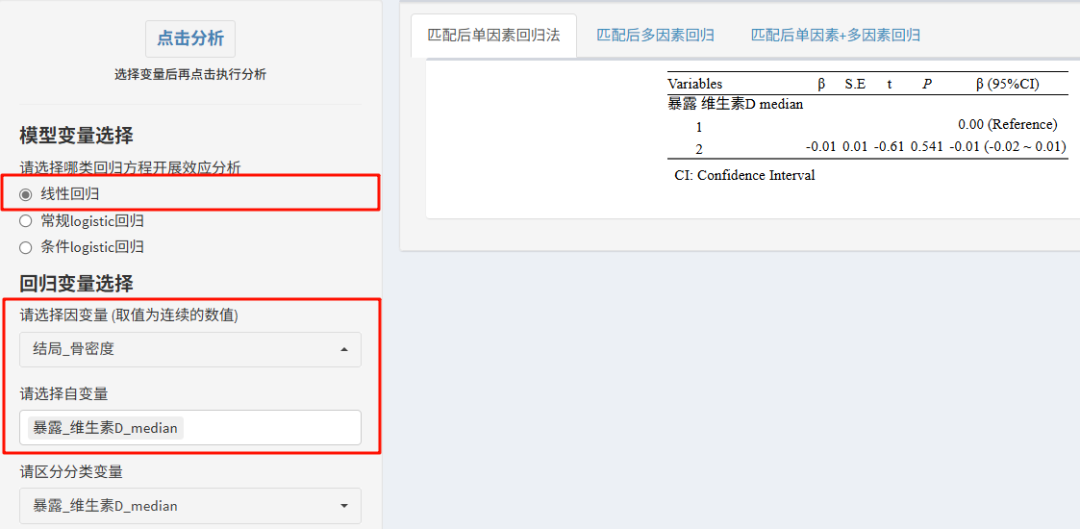
①线性回归
当结局是连续变量时,匹配后数据开展线性回归。如果其他协变量已均衡,可以只做单因素回归。如果有个别变量分组仍不均衡,则需要通过多因素回归进一步调整,选入自变量选框即可。
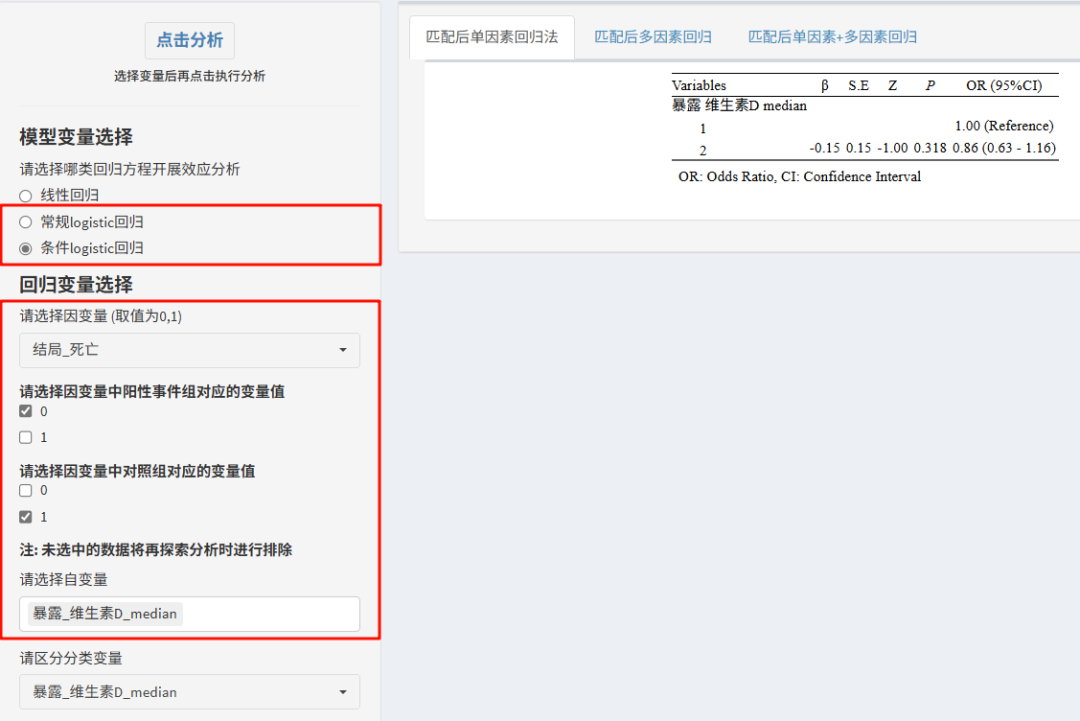
②logistic回归
当结局是二分类变量时,匹配后数据开展logistic回归。平台提供了常规logistic回归与条件logistic。
这里推荐大家使用条件logistic,因为在成对匹配设计中,条件Logistic回归更适用匹配结构。
同样的,如果其他协变量已均衡,可以只做单因素回归。如果有个别变量分组仍不均衡,则需要通过多因素回归进一步调整,选入自变量选框即可。
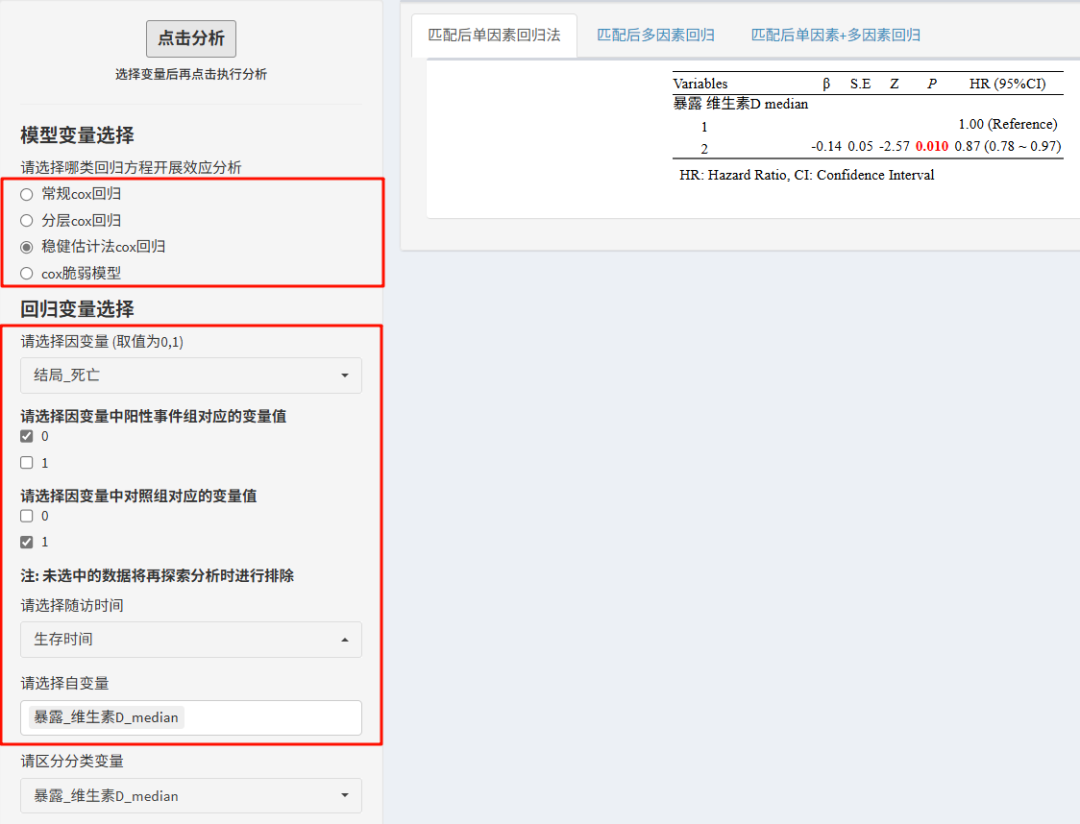
③Cox回归
针对生存数据,平台提供的回归方法更多,其中,最推荐的是"稳健估计法cox回归"。
几种回归方法,结果上会有一定的差异。在运算上,从R语言角度讲,只是在常规cox代码上增加了不同的参数,大家如果感兴趣,可以了解一下相关代码知识。
同样的,如果其他协变量已均衡,可以只做单因素回归。如果有个别变量分组仍不均衡,则需要通过多因素回归进一步调整,选入自变量选框即可。
匹配后的生存数据,还可以绘制KM曲线。只需要选入生存结局、生存时间、分组变量(通常是暴露)。
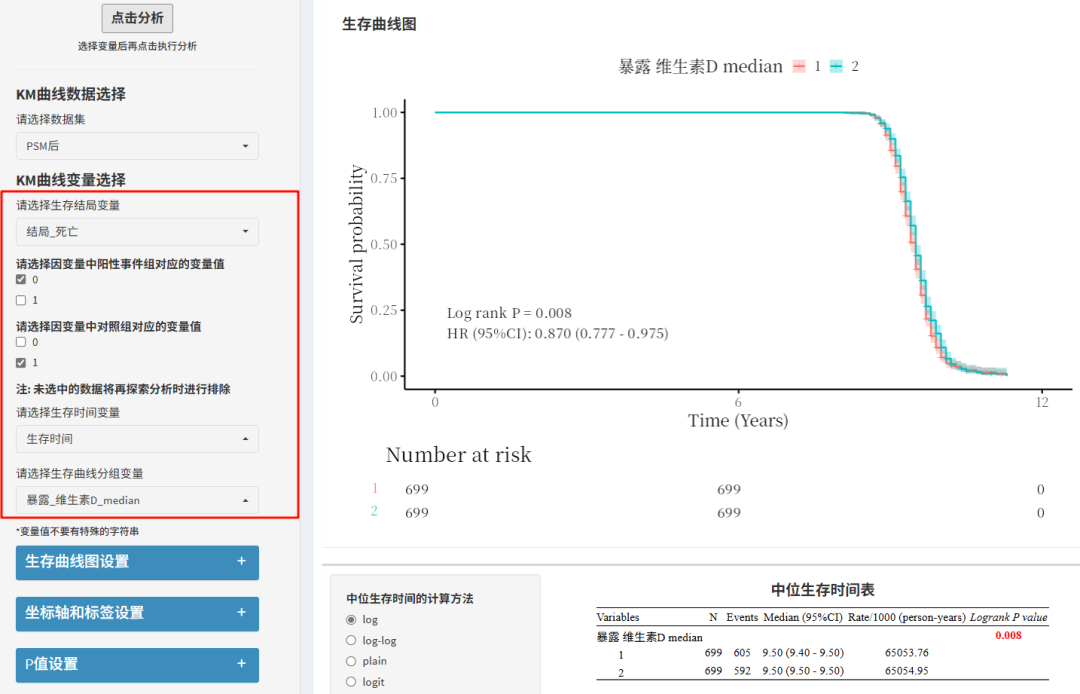
还有对应的各参数设置,从图例,坐标轴到曲线色彩等一应俱全!还可以绘制累计率曲线!
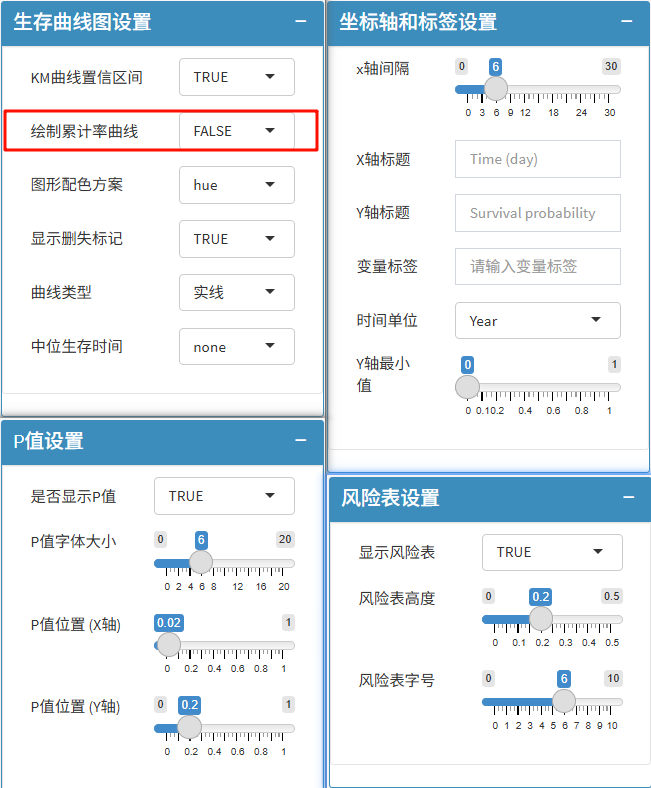
最后,完成全部分析后,回归的三线表与KM曲线图都可以直接下载!
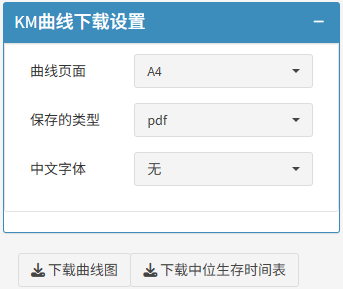
以上就是关于风暴统计平台倾向性得分匹配模块的详细教程。
下篇预告:Zstats风暴统计教程(12):亚组分析与森林图


郑重声明
Zstats-AI 平台
√浙中医大统计老师郑卫军主持
√ 基于R语言软件开发
√ 免费使用,无需注册直接使用
√ 一键生成发表级图表
www.medsta.cn/software
(电脑端浏览器打开)

















 4409
4409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









