







最小二乘回归
w = read.table
> w = read.table("COfreewy.txt",header = T)
> a = lm(CO~.,w)
> summary(a)
Call:
lm(formula = CO ~ ., data = w)
Residuals:
Min 1Q Median 3Q Max
-0.75030 -0.33275 -0.09021 0.22653 1.25112
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.318967 0.242522 5.439 2.53e-05 ***
Hour -0.005689 0.017066 -0.333 0.74233
Traffic 0.018402 0.001413 13.026 3.15e-11 ***
Wind 0.179189 0.059517 3.011 0.00691 **
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.5096 on 20 degrees of freedom
Multiple R-squared: 0.9498, Adjusted R-squared: 0.9423
F-statistic: 126.1 on 3 and 20 DF, p-value: 3.682e-13
容易得出R2和调整R2分别为0.9498,0.9432。其实这个回归效果已经很不错了。但是,此例题中涉及到的自变量较少,现实生活中我们经常遇到的是大数据,那就需要对自变量进行筛选,此处使用的是逐步回归的方法,
逐步回归
逐步回归在做多元线性回归分析时使用,当自变量较多时,我们需要选择对因变量有显著影响的变量,而舍去对因变量无显著影响的变量。
逐步回归有向前逐步回归(forward),后向逐步回归(backward),以及双向逐步回归(both)
向前逐步回归
思想是变量由少到多,属于贪心算法,每次增加一个,直至没有可引入的变量为止。
后向逐步回归
与向前逐步回归相反,将所有变量均放入模型,之后尝试将其中一个自变量从模型中剔除,看整个模型解释因变量是否有显著性变化,之后将对残差平方和贡献较小的变量剔除,此过程不断迭代,直至没有自变量符合剔除的条件。
双向逐步回归
将前两种方法结合起来。
以下是逐步回归的R代码:
b = step(a,direction = "backward") #后向逐步回归
Start: AIC=-28.73
CO ~ Hour + Traffic + Wind
Df Sum of Sq RSS AIC
- Hour 1 0.029 5.224 -30.597
<none> 5.195 -28.730
- Wind 1 2.354 7.549 -21.759
- Traffic 1 44.070 49.265 23.260
Step: AIC=-30.6
CO ~ Traffic + Wind
Df Sum of Sq RSS AIC
<none> 5.224 -30.597
- Wind 1 2.357 7.581 -23.659
- Traffic 1 46.117 51.341 22.250
> shapiro.test(b$res)#残差的正态性检验
Shapiro-Wilk normality test
data: b$res
W = 0.91918, p-value = 0.05601
c = step(a,direction = "forward") ##向前逐步回归
Start: AIC=-28.73
CO ~ Hour + Traffic + Wind
> d = step(a,direction = "both") ##双向逐步回归
Start: AIC=-28.73
CO ~ Hour + Traffic + Wind
Df Sum of Sq RSS AIC
- Hour 1 0.029 5.224 -30.597
<none> 5.195 -28.730
- Wind 1 2.354 7.549 -21.759
- Traffic 1 44.070 49.265 23.260
Step: AIC=-30.6
CO ~ Traffic + Wind
Df Sum of Sq RSS AIC
<none> 5.224 -30.597
+ Hour 1 0.029 5.195 -28.730
- Wind 1 2.357 7.581 -23.659
- Traffic 1 46.117 51.341 22.250
> shapiro.test(c$res)#残差的正态性检验
Shapiro-Wilk normality test
data: c$res
W = 0.93027, p-value = 0.09885
> shapiro.test(d$res)#残差的正态性检验
Shapiro-Wilk normality test
data: d$res
W = 0.91918, p-value = 0.05601
以上使用了三种逐步回归,其中backward和both出来的模型是一样的,都删去了Hour这个自变量,残差的正态性检验结果也一致。而forward就没有删去任何自变量,也可以看出它的残差正态性检验结果就不太理想。
在这里使用了AIC在逐步回归语句中选择变量,AIC越小的模型更优
Box-Cox变换
为了使得经典线性模型所需要的正态性假定成立,常常对因变量使用Box-Cox变换,以使其接近正态形状。
同样先引入一组数据,先用简单回归对其处理,代码如下:
u = read.csv("pharynx1.csv") ##读入数据
> x = 1:11;
> x = x[-c(5,11)] ##第5列和第11列为数值型数据,这样形成的x就是定性变量的下标
> for(i in x){
+ u[,i] = factor(u[,i])} ##把定性变量从数值型转换成因子型
> a = lm(TIME~.,data = u)
> summary(a)
Call:
lm(formula = TIME ~ ., data = u)
Residuals:
Min 1Q Median 3Q Max
-748.78 -157.55 -45.12 122.42 1098.52
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 538.377 201.900 2.667 0.008395 **
INST2 114.148 81.441 1.402 0.162837
INST3 275.375 82.169 3.351 0.000989 ***
INST4 138.432 86.658 1.597 0.111999
INST5 124.042 86.963 1.426 0.155573
INST6 213.470 85.577 2.494 0.013558 *
SEX2 96.595 51.741 1.867 0.063616 .
TX2 -60.311 43.458 -1.388 0.166994
GRADE2 73.131 56.425 1.296 0.196688
GRADE3 32.436 70.346 0.461 0.645310
GRADE9 -100.041 307.113 -0.326 0.745011
AGE 3.658 1.990 1.839 0.067680 .
COND2 -244.410 53.205 -4.594 8.39e-06 ***
COND9 -205.640 300.213 -0.685 0.494278
SITE2 29.993 57.101 0.525 0.600073
SITE4 19.483 55.965 0.348 0.728171
T.STAGE2 196.903 115.786 1.701 0.090829 .
T.STAGE3 117.585 106.816 1.101 0.272518
T.STAGE4 73.922 111.557 0.663 0.508450
N.STAGE1 -2.417 73.812 -0.033 0.973912
N.STAGE2 -58.033 76.753 -0.756 0.450626
N.STAGE3 -62.284 61.369 -1.015 0.311571
STATUS1 -570.484 50.458 -11.306 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 288.7 on 172 degrees of freedom
Multiple R-squared: 0.5786, Adjusted R-squared: 0.5246
F-statistic: 10.73 on 22 and 172 DF, p-value: < 2.2e-16
R2和修正R2分别为0.5786和0.5246,很明显该模型是不理想的。**因此我们尝试对因变量TIME做Box-Cox变换,**代码如下:
library(MASS)
> b = boxcox(TIME~.,data = u) #作图找出y最大时对应的lambda
> I = which(b$y == max(b$y))
> b$x[I]
[1] 0.3838384
我们找到了lambda = 0.38,为了方便,我们取lanbda = 0.4,再用TIME0.4去做拟合,代码如下:
a = lm(TIME^0.4 ~ INST + SEX + TX + AGE + COND + T.STAGE + N.STAGE + STATUS,data = u)
> b = step(a)
Start: AIC=382.46
TIME^0.4 ~ INST + SEX + TX + AGE + COND + T.STAGE + N.STAGE +
STATUS
Df Sum of Sq RSS AIC
- N.STAGE 3 14.25 1166.8 378.85
- T.STAGE 3 30.20 1182.7 381.50
<none> 1152.5 382.46
- TX 1 12.47 1165.0 382.56
- INST 5 68.12 1220.6 383.65
- SEX 1 21.07 1173.6 383.99
- AGE 1 35.04 1187.5 386.30
- COND 2 240.06 1392.6 415.35
- STATUS 1 722.34 1874.8 475.34
Step: AIC=378.85
TIME^0.4 ~ INST + SEX + TX + AGE + COND + T.STAGE + STATUS
Df Sum of Sq RSS AIC
- T.STAGE 3 31.28 1198.0 378.01
<none> 1166.8 378.85
- TX 1 13.00 1179.8 379.01
- INST 5 73.49 1240.2 380.76
- SEX 1 25.87 1192.6 381.13
- AGE 1 44.11 1210.9 384.09
- COND 2 270.97 1437.7 415.58
- STATUS 1 743.33 1910.1 472.97
Step: AIC=378.01
TIME^0.4 ~ INST + SEX + TX + AGE + COND + STATUS
Df Sum of Sq RSS AIC
<none> 1198.0 378.01
- TX 1 17.69 1215.7 378.87
- SEX 1 33.08 1231.1 381.32
- AGE 1 47.30 1245.3 383.56
- INST 5 103.27 1301.3 384.14
- COND 2 276.75 1474.8 414.54
- STATUS 1 775.26 1973.3 473.32
> shapiro.test(b$res)
Shapiro-Wilk normality test
data: b$res
W = 0.9887, p-value = 0.1253
> summary(b)
Call:
lm(formula = TIME^0.4 ~ INST + SEX + TX + AGE + COND + STATUS,
data = u)
Residuals:
Min 1Q Median 3Q Max
-7.0827 -1.6601 -0.2061 1.5701 7.7469
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.22806 1.17908 10.371 < 2e-16 ***
INST2 0.54717 0.68674 0.797 0.42663
INST3 2.11339 0.68457 3.087 0.00233 **
INST4 0.87697 0.74530 1.177 0.24086
INST5 0.44361 0.72487 0.612 0.54131
INST6 1.65217 0.72815 2.269 0.02444 *
SEX2 0.98922 0.44009 2.248 0.02579 *
TX2 -0.61504 0.37413 -1.644 0.10191
AGE 0.04519 0.01681 2.688 0.00785 **
COND2 -2.91885 0.45124 -6.468 8.77e-10 ***
COND9 -2.24497 2.60983 -0.860 0.39081
STATUS1 -4.72356 0.43407 -10.882 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.559 on 183 degrees of freedom
Multiple R-squared: 0.5625, Adjusted R-squared: 0.5362
F-statistic: 21.39 on 11 and 183 DF, p-value: < 2.2e-16
经过Box-Cox变换后,用逐步回归剔除了变量后得到了一个回归模型,此模型的R2和修正R2分别为0.5625和0.5326,虽然关于拟合的F检验很显著(p值小于2.2*10-16),但从R2来看,似乎结果仍然不太理想。
生存分析数据的Cox回归模型
上个例子中的因变量TIME为典型的生存分析数据,常用Cox比例危险回归模型来对其建模,在生存分析中,研究的主要对象是寿命超过某一时间的概率。当然,生存分析模型不仅和寿命有关,还可以描述其他一些事件发生的概率,例如:产品的失效、出狱犯人第一次犯罪、失业人员第一次找到工作、青少年第一次吸毒等。
首先我们用一下命令画出综合生存函数,代码如下:
library(survival)
library(ggplot2)
> library(survminer)
> fit = survfit(Surv(TIME,as.numeric(STATUS)) ~ TX,data = u) ##生存函数
> ggsurvplot(fit, data = u,
+ pval = T, # 在图上添加log rank检验的p值
+ conf.int = T,# 添加置信区间
+ risk.table = T, # 在图下方添加风险表
+ legend.labs=c("TX = 1","TX = 2"), #表头标签注释男女
+ legend.title="Survival Function",#表头标签
+ title="Overall survival",#改一下整体名称
+ ylab="Cumulative survival (percentage)",xlab = " Time (Days)",#修改X轴Y轴名称
+ risk.table.col = "strata", # 风险表加颜色
+ linetype = "strata", # 生存曲线的线型
+ surv.median.line = "hv", # 标注出中位生存时间
+ ggtheme = theme_bw(), #背景布局
+ palette = c("red", "blue")) # 图形颜色风格
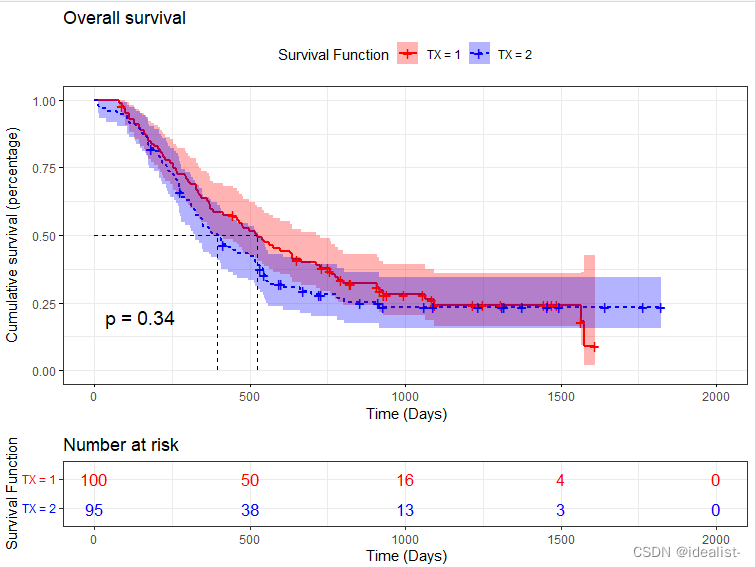
现在我们用Cox比例危险回归模型来拟合该数据,代码如下:
library(survival)
> fit = coxph(Surv(TIME,as.numeric(STATUS))~.,data = u) #Cox回归模型
> plot(survfit(fit)) #拟合的生存函数
> summary(fit) #回归结果
Cox比例危险模型的多重分数多项式模型(multiple fractional polynomial model)
这个模型就是在Cox比例危险模型的基础上自动进行逐步回归及变量选择。上面如果只是用Cox比例危险模型不足以建立一个很好的模型,因为从输出结果上看,许多变量并不显著,因此,可以减少一些变量来优化模型。故而引入这个模型。还是以上题的数据为例,建立Cox比例危险模型的多重分数多项式模型,代码如下:
library(mfp)
> f = mfp(Surv(TIME,as.numeric(STATUS))~fp(AGE,df = 4,select = 0.05)+INST+SEX+TX+GRADE+COND+SITE+T.STAGE+N.STAGE,family = cox,data = u)
> print(f)
rsq = 1-sum((f$residuals)^2)/sum((u$TIME-mean(u$TIME))^2) #计算R^2
> rsq
[1] 0.9999954
可看出似然比检验的p值都很小,且R2为0.999,该模型明显比前面拟合的要好。
数据出现多重共线性情况
在多元回归中,当两个或更多的自变量有些相关的时候,就有可能出现多重共线性的情况。当多重共线性严重时,模型或数据的微小变化有可能造成系数估计的较大变化,这使得结果模型不稳定,也不易解释。一般来说,只要不存在严重共线性,对预测不会有较大影响,但高度的多重共线性会造成计算困难,比如矩阵的逆可能会很不稳定。
关于多重共线性的度量:容忍度、方差膨胀因子(VIF)和条件数。容忍度太小或VIF太大(比如大于5或10),则有多重共线性问题。当条件数>15时,有共线性问题;而条件数>30时,说明共线性问题严重。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









