










量化投资分析平台 迅投 QMT
迅投 QMT
我目前在使用
两个月前(2024年4月)迅投和CQF有一个互动的活动,进行了平台的一个网上路演,刚好我也去听了,感觉还是挺不错的。后来与“客服麻瓜”进行了对QMT的深入了解和使用,最后决定买了他们的服务。注册就可以进行试用,但是是有期限的。如果只是单方面的研究的话,还是建议用稍微便宜些的平台,我主要是需要期权的实时数据进行分析和交易。
隐含波动率(Implied Volatility)
这隐波就像大家买卖股票的一个信号一样,期权的买卖基本上都是靠观察隐含波动率来选择如何操作的。隐波太高了,肯定会回落,隐波太低了,肯定会突破。但是大家不要混淆一点是,隐波只是测算波动率,并不能代表方向,和MACD,STOCH指标啥的还是有区别的。
话不多说上代码
具体的前戏都该干嘛请自己去翻阅1~4篇,我就不再过多赘述了。第四篇我们获取到期权的代码后,需要整理出倆个函数,这个函数将帮助我们筛选出我们想要的相关期权合约代码
- 获取标的资产的价格Dataframe,然后通过统计计算出区间的均值与标准差,这个函数在第三篇有讲过,关于如何获取QMT的Dataframe;
def get_undl_asset_price(ticker_, start_time_, end_time_):
hist_data_1d_ = xtdata.get_market_data_ex(
field_list=[],
stock_list=[ticker_],
period='1d',
start_time=start_time_,
end_time=end_time_,
count=-1,
dividend_type='front',
fill_data=False,
)
hist_data_1d_ = [value for key, value in hist_data_1d_.items()][-1]
data_ = pd.DataFrame(hist_data_1d_.copy())
data_.index = pd.to_datetime(data_.index.astype(str), format='%Y%m%d', errors='coerce')
return data_
输出效果:

2. 第二个函数我们通过获取到的未过滤的合约Dataframe来进行过滤,筛选出我们想要的合约;
def obtain_all_atm_opt(ticker_: str, CP_: str, STDDEV_MULT: int=0):
df_opt_details = option_details(ticker_)
# 获取到可交易时限存在最久的那些合约
oldest_opt = df_opt_details[df_opt_details['lifespan'] == df_opt_details['lifespan'].max()]
# created date of the oldest option,把最久的期权时间戳获取存一下后面有用
oocd = pd.Timestamp(oldest_opt['CreateDate'].values[0]).strftime('%Y%m%d')
# get underlying asset's price data for spot / strike analysis based on oldest option's lifespan
oo_undl_asset_d = get_undl_asset_price(ticker_, oocd, last_trading_day)
average = oo_undl_asset_d['close'].mean().round(1) # 计算期权存续期内标的资产的价格均值
stddev = oo_undl_asset_d['close'].std().round(1) # 计算期权存续期内标的资产的价格标准差(历史波动率)
# 这块我加了个标准差倍数参数,后面计算的IV的时候可以调整用到
atm_options = df_opt_details[
(df_opt_details['OptExercisePrice'].round(1).isin([average + STDDEV_MULT*stddev,])) &
(df_opt_details['optType'] == CP_)
].reset_index(drop=True)
return atm_options, oo_undl_asset_d, oocd
输出效果(输出例子是看沽期权的,这样我们获取到了所有存续期内的看沽平值期权的交易代码):

3. 接下来我们将获取到的信息,通过InstrumentID来进行获取期权的日线数据,并与标的资产进行拼接,为计算IV做好准备。
@cache
def retrieve_opt_data_d(ticker_: str, CP_: str, STDDEV_MULT: int=0):
ddff, undl_d, cd = obtain_all_atm_opt(ticker_, CP_,)
dfs_ = []
for rec in range(len(ddff)):
oo_options = pd.DataFrame(ddff.loc[rec]).T
tickers = oo_options['InstrumentID'].tolist()
for tick_ in tickers:
xtdata.subscribe_quote(tick_, period='1d', start_time=cd, count=-1)
time.sleep(1)
xtdata.download_history_data(tick_, period='1d')
time.sleep(1)
df_tester = xtdata.get_market_data_ex(
field_list=[],
stock_list=tickers,
period='1d',
start_time=cd,
end_time=last_trading_day,
count=-1,
dividend_type='front',
fill_data=False,
)
########## 以上都是数据订阅和下载,属于QMT内部指令 ##########
df_options_oo = pd.DataFrame()
# 循环遍历所有的InstrumentID
for i_ in range(len(tickers)):
df_ = [value for key, value in df_tester.items()][i_] # extract the data for each option dict
df_ticker_ = [key for key, value in df_tester.items()][i_] # extract the ticker for each option dict
df_['InstrumentID'] = df_ticker_
df_['InstrumentName'] = oo_options[oo_options['InstrumentID'] == df_ticker_]['InstrumentName'].values[0]
df_['optType'] = oo_options[oo_options['InstrumentID'] == df_ticker_]['optType'].values[0]
df_['OptExercisePrice'] = oo_options[oo_options['InstrumentID'] == df_ticker_]['OptExercisePrice'].values[0]
df_['ExpireDate'] = oo_options[oo_options['InstrumentID'] == df_ticker_]['ExpireDate'].values[0]
df_['OptUndlRiskFreeRate'] = oo_options[oo_options['InstrumentID'] == df_ticker_]['OptUndlRiskFreeRate'].values[0]
# 信息整理录好了以后进行横向拼接,每多一列就在右侧拼一列
df_options_oo = pd.concat([df_options_oo, df_], axis=0)
# 拼好了以后进行索引的设置,为拼接标的资产信息做准备
df_options_oo.index = pd.to_datetime(df_options_oo.index.astype(str), format='%Y%m%d', errors='coerce')
# only obtain the close price for the underlying asset, and rename it
undl_asset_d_ = undl_d[['close']].copy()
undl_asset_d_ = undl_asset_d_.rename(columns={'close': 'close_undl_asset'})
# put underlying asset's close price into the options dataframe horizontally
df_options_oo = pd.concat([df_options_oo, undl_asset_d_], axis=1)
# 每打包好一个Dataframe就将其放入dfs_的列表里,最后获取一个Dataframe的list包
dfs_.append(df_options_oo.dropna())
return dfs_
输出效果:

4. 开始计算IV,我们需要先安装一个库,请在终端内自行安装到你的环境中进行使用。pip install py_vollib
from py_vollib.black_scholes_merton.implied_volatility import implied_volatility as bsm_iv
@cache
def get_iv_values_for_00(ticker_: str, CP_: str, STDDEV_MULT: int=0):
dfs_merged = retrieve_opt_data_d(ticker_, CP_, STDDEV_MULT)
df_ivs = pd.DataFrame()
for df_merged in dfs_merged:
df_merged = df_merged.dropna()
# 先提前布局好两列需要用到的数据空值,剩余存续天数,和IV
df_merged['days_to_expiry'] = df_merged['iv'] = np.nan
# 一定要用try循环,沪深300计算没问题,但是上证50就会偶尔报错,报错的我们直接过滤掉
try:
for n_ in range(len(df_merged)):
df_merged['days_to_expiry'].iloc[n_] = (df_merged['ExpireDate'].iloc[n_] - df_merged.index[n_]).days
df_merged['iv'].iloc[n_] = bsm_iv(
price = df_merged['close'].iloc[n_],
S = df_merged['close_undl_asset'].iloc[n_],
K = df_merged['OptExercisePrice'].iloc[n_],
t = df_merged['days_to_expiry'].iloc[n_]/365,
r = df_merged['OptUndlRiskFreeRate'].iloc[n_],
flag = CP_[0].lower(),
q=0
)
except Exception as e:
print("Exception:", e)
pass
# 我们每遍历一次,只存IV的数值,并按列拼接,最后取行均值
df_ivs = pd.concat([df_ivs, df_merged['iv']], axis=1)
return df_ivs.mean(axis=1)
# get_iv_values_for_00('510050.SH', 'CALL')
效果图:
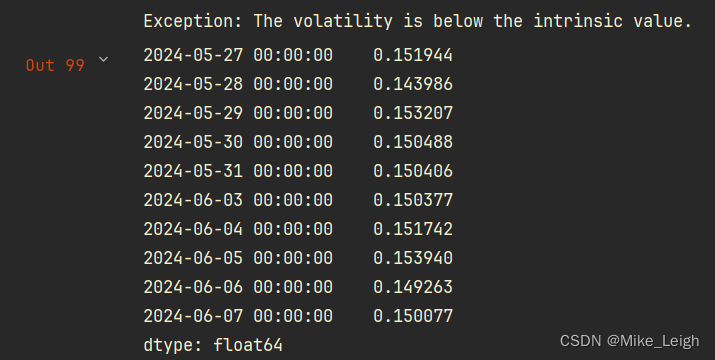
5. 看着还不错,我们最后将ATM的范围扩大一下,还记得之前说的方差倍系数么?,这里我们将它作为一个参数来进行遍历,最终给我们一个包涵ATM,OTM,ITM的整体的一个IV均值。
@cache
def iv_avgs(ticker_: str, CP_: str):
df_ivs = pd.DataFrame()
if ticker_ == '510300':
stddev_spread = range(-2,3) if CP_ == 'CALL' else range(-3,2)
else:
stddev_spread = range(-1,3)
for i in stddev_spread:
df_ = get_iv_values_for_00(ticker_, CP_, i)
df_ivs = pd.concat([df_ivs, df_], axis=1)
return df_ivs.mean(axis=1)
- 最后的最后,我们把IV给画出来,数据有了,可视化是最终目的,从中找出一些规律来进行合理投资。
# from PIL import Image
import cufflinks as cf
import plotly.graph_objs as go
from plotly.subplots import make_subplots
@cache
@ml.timer_pbar
def plot_ivs(ticker_: str):
ivsc = iv_avgs(ticker_, 'CALL')
ivsp = iv_avgs(ticker_, 'PUT')
try:
ivsc.index = ivsc.index.strftime('%H:%M:%S')
ivsp.index = ivsp.index.strftime('%H:%M:%S')
except Exception as e:
print("Exception:", e)
pass
fig = go.Figure()
fig.add_trace(go.Scatter(
x=ivsc.index,
y=ivsc,
mode='lines+markers',
name='IV_call',
line=dict(color='cornflowerblue')
))
fig.add_trace(go.Scatter(
x=ivsp.index,
y=ivsp,
mode='lines+markers',
name='IV_put',
line=dict(color='tomato')
))
height = 1000
fig.update_layout(
height=height, width=height*1.8,
xaxis=dict(
type='category',
rangeslider=dict(visible=False),
),
xaxis2=dict(
type='category',
rangeslider=dict(visible=False),
),
title=f'{ticker_} Implied-Volatility Daily Chart',
titlefont_size=24,
titlefont_color='goldenrod',
template='presentation',
legend_title_text='Indicators',
margin=dict(l=100, r=100, b=160, t=100, pad=10),
)
fig.show()
输出效果图(上证50、沪深300):
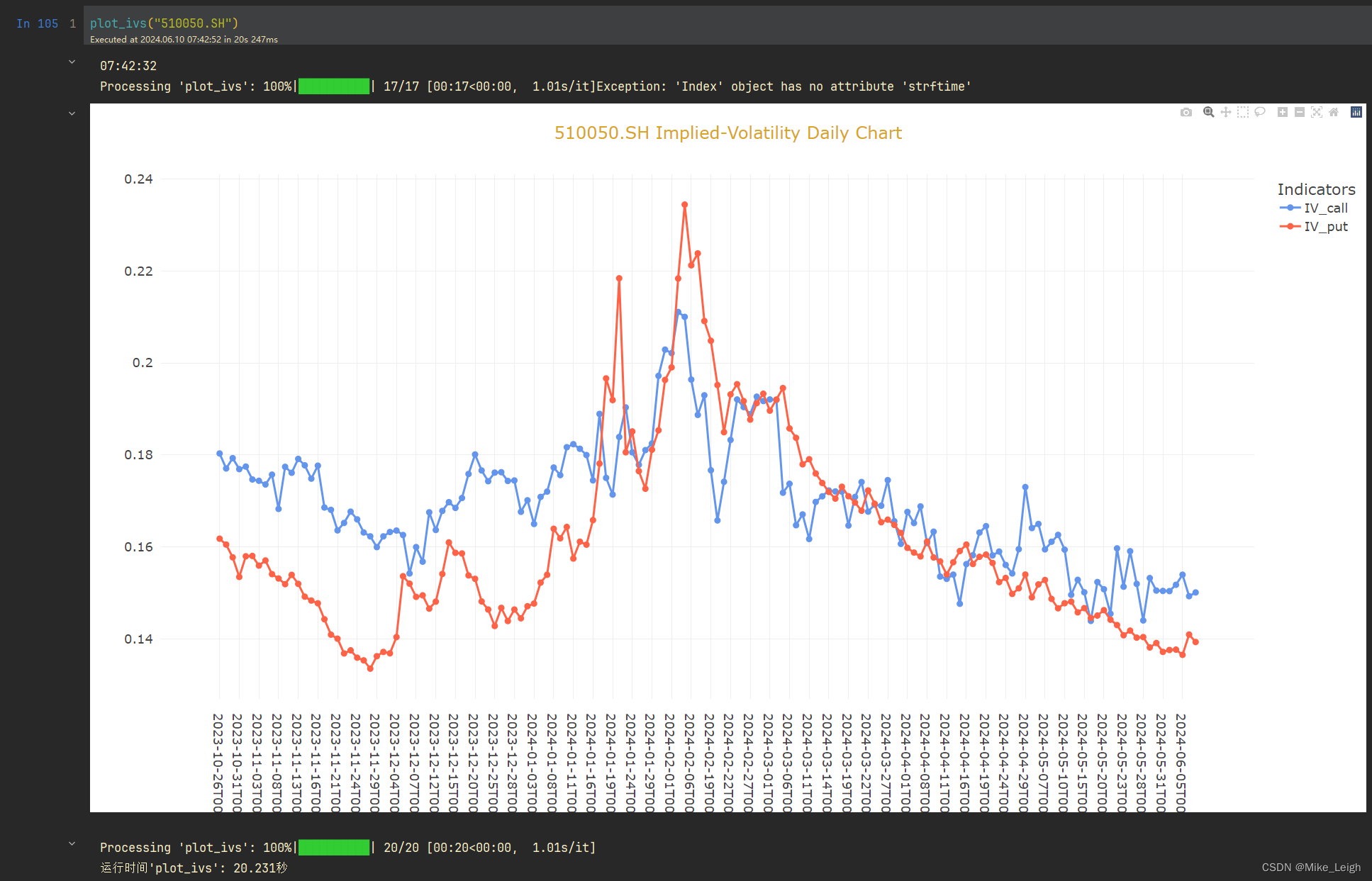
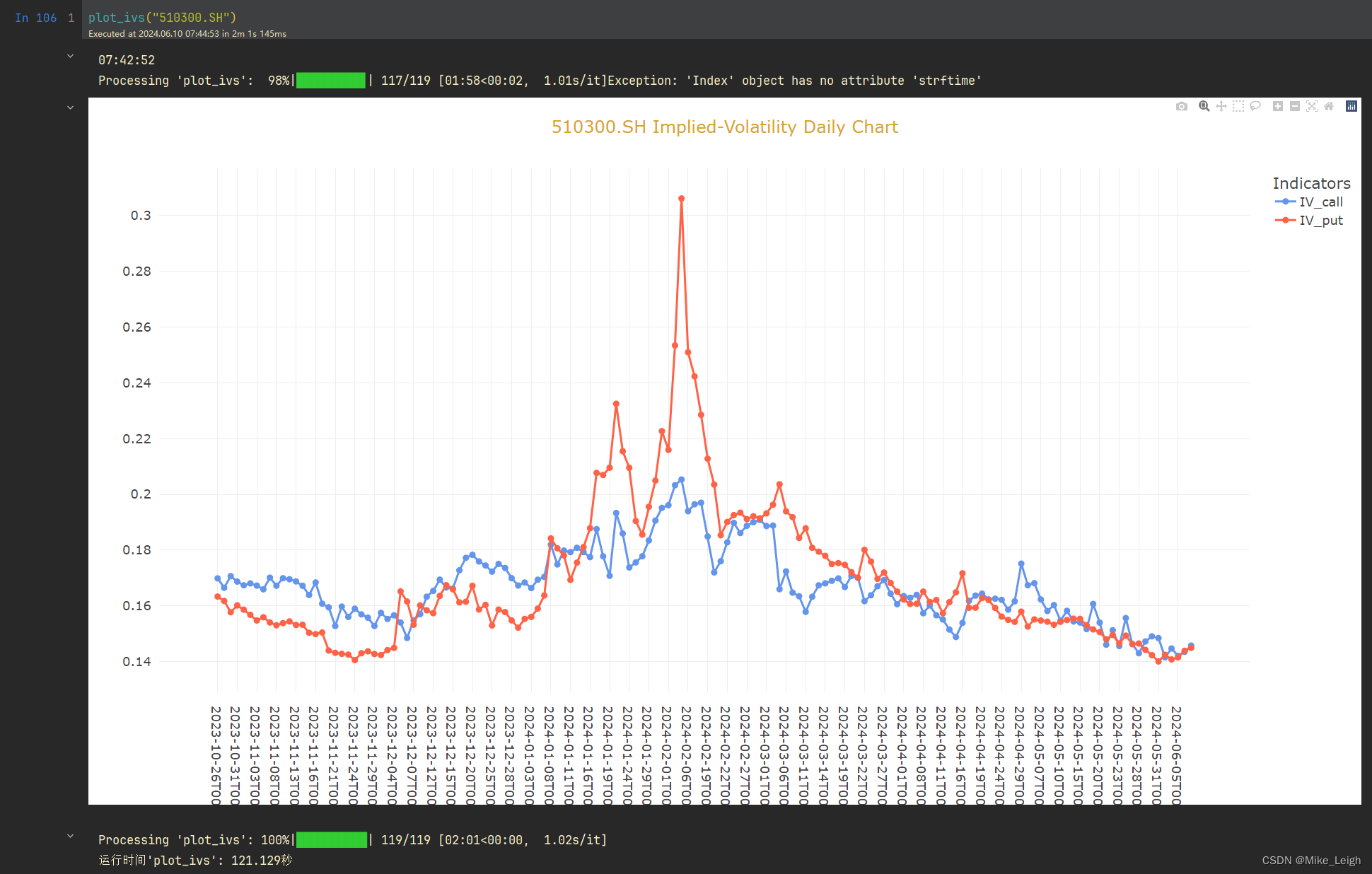
一般来讲,差不多跑两分钟。上证50的图20秒是因为@cache这个装饰器,它预存了我之前的结果。我们可以看两幅图,可以得出的结论是沪深300的波动率要比上证50的大,毕竟上证50都是些巨无霸国企央企,沪深300还是有一些优质的民企,但是数量越多,不确定性越大,也就导致了波动率越高。看个人对于风险的厌恶程度吧,我个人更喜欢投资沪深300,也只是个人喜好而已,欢迎大家一起讨论研究。希望今天的帖子对大家有一定的启发和帮助,也愿大家在期权投资的路上高歌猛进、财源滚滚、心想事成!
对装饰器感兴趣的朋友也可以去我上周发的两篇关于计时和进度条装饰器的帖子。
希望大家能够给予一键三连啥的,您的鼓励就是我最大的动力!
历史帖子
量化投资分析平台 迅投 QMT(一)激活python迅投对接端口
量化投资分析平台 迅投 QMT(二)服务器端订阅下载数据
量化投资分析平台 迅投 QMT(三)字典数据下载后读取成Dataframe形式
量化投资分析平台 迅投 QMT(四)获取标的期权的代码
量化投资分析平台 迅投 QMT(五)我对期权的理解和定义,普及向,无代码
量化投资分析平台 迅投 QMT(六)资产定价绕不过去的BSM模型

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











