






1. LLaGA: Large Language and Graph Assistant(ICML2024)
LLaGA: Large Language and Graph Assistant | OpenReview![]() https://openreview.net/forum?id=B48Pzc4oKi
https://openreview.net/forum?id=B48Pzc4oKi
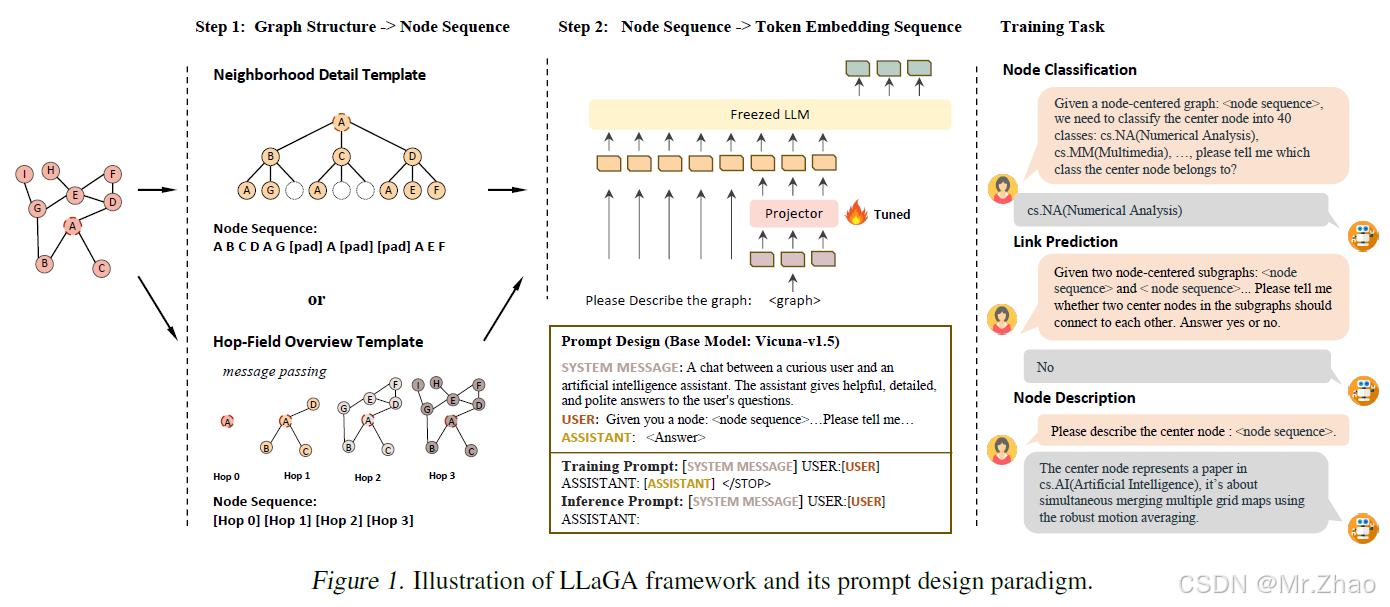
由于将图结构转化为语言本身的难度,它们在图形数据中的应用带来了独特的挑战。为此,推出了大型语言和图形助手 (LLaGA),这是一种创新模型,可有效集成 LLM 功能来处理图结构数据的复杂性。LLaGA 保留了 LLM 的通用性质,同时将图形数据调整为与 LLM 输入兼容的格式。LLaGA 通过将图节点重新组织为结构感知序列,然后通过多功能投影仪将它们映射到 token 嵌入空间来实现这一点。LLaGA 在多功能性、通用性和可解释性方面表现出色,使其能够在不同的数据集和任务中始终表现良好,将其能力扩展到看不见的数据集或任务,并为图形提供解释。
2. Label-free Node Classification on Graphs with Large Language Models(ICLR2024)
2310.04668 (arxiv.org)![]() https://arxiv.org/pdf/2310.04668
https://arxiv.org/pdf/2310.04668
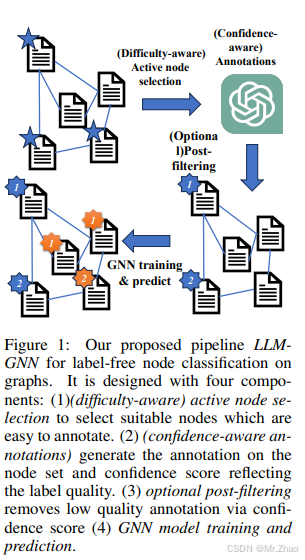
近年来,图神经网络 (GNN) 在节点分类方面取得了显著进展。然而,它们需要大量高质量的标签才能确保良好的性能。相比之下,大型语言模型 (LLM) 在文本属性图上表现出令人印象深刻的零样本能力。然而,它们在有效处理结构数据方面面临挑战,并且推理成本高昂。鉴于这些观察结果,这项工作引入了一种使用 LLM 管道的无标签图节点分类 LLM-GNN。它融合了 GNN 和 LLM 的优势,同时减轻了它们的局限性。具体来说,LLM 被用来注释一小部分节点,然后在 LLM 的注释上训练 GNN 以对剩余的大部分节点进行预测。LLM-GNN 的实施面临着一个独特的挑战:我们如何主动选择节点让 LLM 注释,从而增强 GNN 训练?如何利用 LLM 获得高质量、有代表性和多样性的注释,从而以更低的成本提高 GNN 性能?为了应对这一挑战,我们开发了一种注释质量启发式方法,并利用从 LLM 获得的置信度分数来进行高级节点选择。
3.Harnessing explanations: LLM-to-LM interpreter for enhanced text-attributed graph representation learning(ICLR2024)
2305.19523 (arxiv.org)![]() https://arxiv.org/pdf/2305.19523
https://arxiv.org/pdf/2305.19523
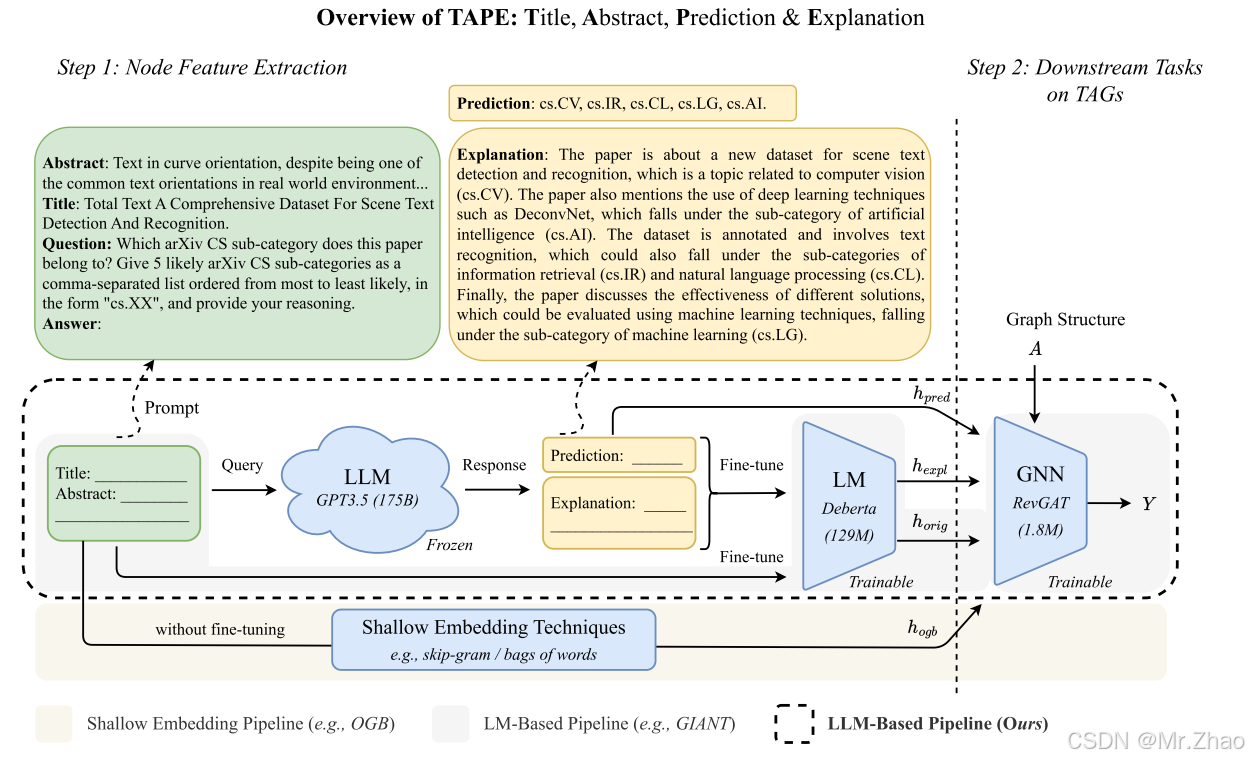
在这项工作中,专注于利用LLM来捕获文本属性图中文本信息作为特征,这些特征可用于提高GNN在下游任务上的性能。一个关键的创新是使用解释作为特征:提示LLM执行zero-shot分类,为其决策过程请求文本解释,并设计一个LLM到LM解释器将这些解释转换为下游GNN的信息特征。
4. LLM4DyG: CanLarge Language Models Solve Spatial-Temporal Problems on Dynamic Graphs?(KDD24)
https://arxiv.org/abs/2310.17110![]() https://arxiv.org/abs/2310.17110
https://arxiv.org/abs/2310.17110
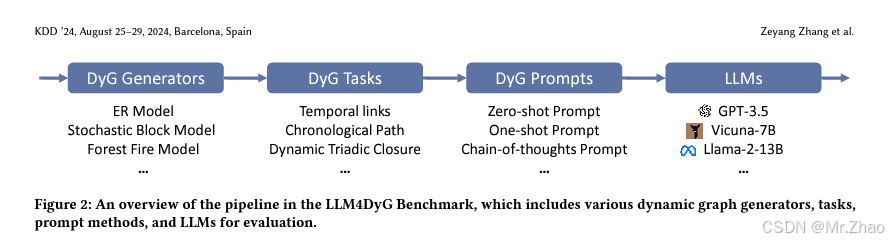
动态图捕捉时间网络演化模式,在现实世界的网络数据中无处不在。评估 LLM 在理解动态图上时空信息的能力对于它们在网络应用中的应用至关重要,而这在文献中仍未得到探索。在本文中,我们通过首次提出评估 LLM 在动态图上的时空理解能力来弥补这一差距。1)LLM对动态图具有初步的时空理解能力;2)随着图的大小和密度的增加,动态图任务对LLM来说变得越来越困难,但对时间跨度和数据生成机制不敏感;3)提出的DST2提示方法可以帮助提高LLM在大多数任务上对动态图的时空理解能力。
5.GAugLLM: Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models(KDD24)
https://arxiv.org/abs/2406.11945![]() https://arxiv.org/abs/2406.11945
https://arxiv.org/abs/2406.11945
本研究研究了文本属性图 (TAG) 的自监督图学习,其中节点由文本属性表示。首先,文本属性的长度和质量通常各不相同,因此很难在不改变原始文本描述原始语义含义的情况下对其进行扰乱。其次,尽管文本属性补充了图结构,但它们本身并不是很好地对齐的。为了弥补这一差距,我们引入了 GAugLLM,这是一种用于增强 TAG 的新框架。具体来说,我们引入了一种混合提示专家技术来生成增强节点特征。这种方法自适应地将多个提示专家(映射到数值特征空间中。此外,设计了一个协作边缘修改器来利用结构和文本共性,通过检查或建立节点之间的连接来增强边缘增强。
6.Can GNN be Good Adapter for LLMs?(WWW24)
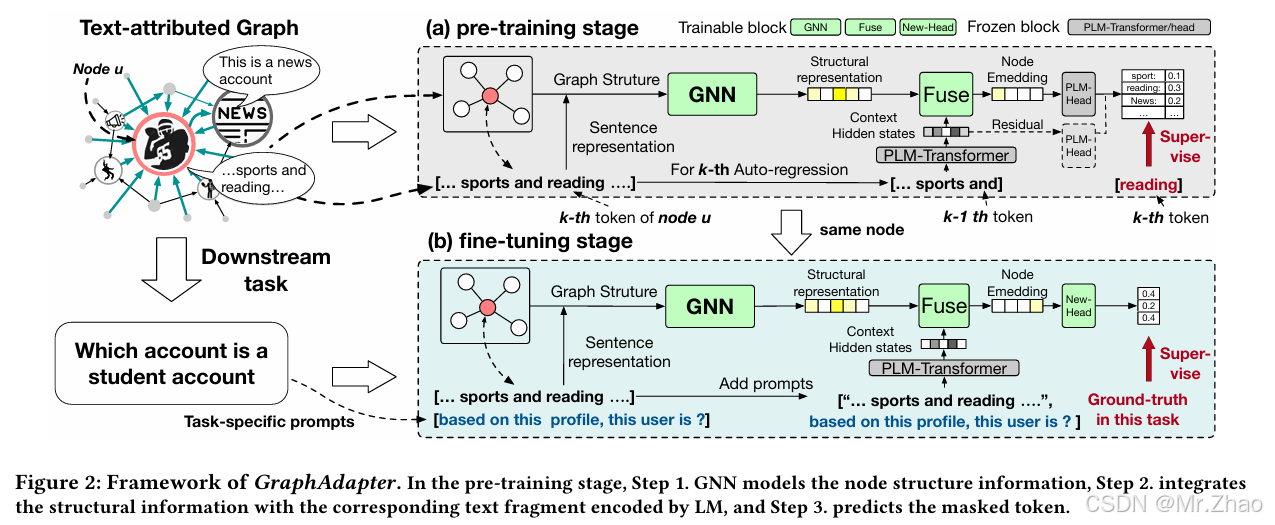
在图域中,各种现实场景也涉及文本数据,其中任务和节点特征可以用文本来描述。这些文本属性图 (TAG) 在社交媒体、推荐系统等领域有着广泛的应用。因此,本文探讨了如何利用 LLM 来建模 TAG。以前的 TAG 建模方法基于百万级 LM。当扩展到十亿级 LLM 时,它们面临着巨大的计算成本挑战。此外,它们还忽略了 LLM 的零样本推理能力。因此,我们提出了 GraphAdapter,它使用图神经网络 (GNN) 作为高效适配器与 LLM 协作来处理 TAG。在效率方面,GNNadapter 仅引入了少量可训练参数,并且可以以较低的计算成本进行训练。整个框架使用节点文本(下一个标记预测)的自回归进行训练。一旦训练完成,GraphAdapter 就可以根据各种下游任务的任务特定提示进行无缝微调。
7.GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks(WWW24)
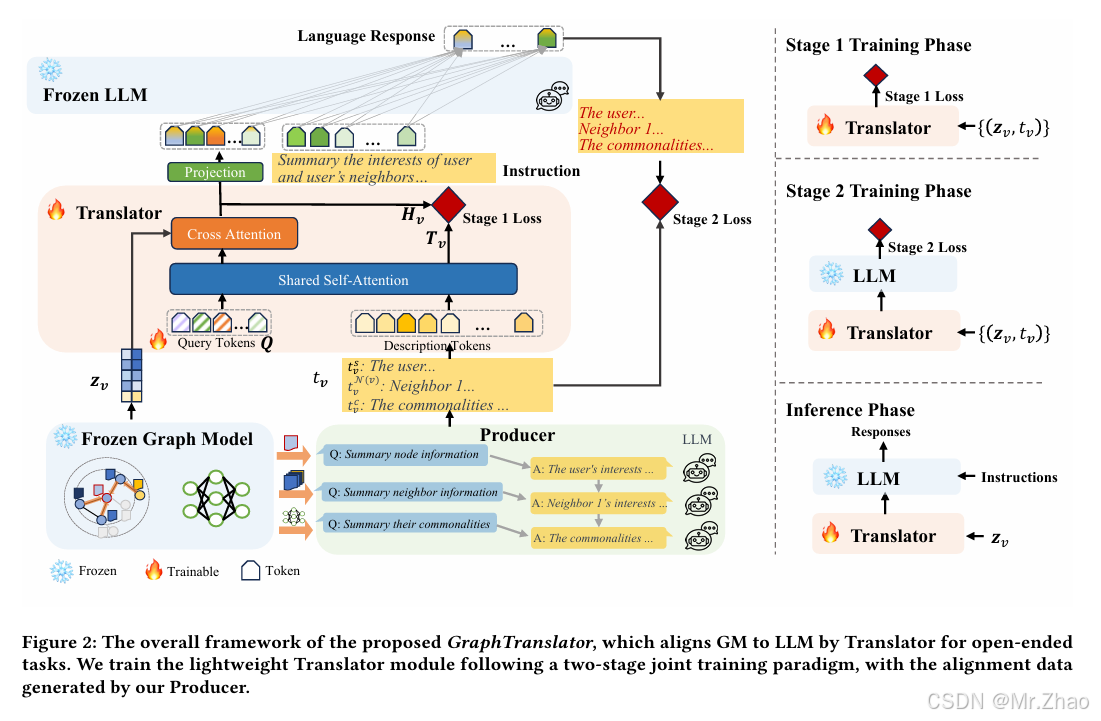
大型语言模型 (LLM)(例如 ChatGPT)表现出强大的零样本和指令跟踪能力,催化了不同领域的革命性变革,尤其是对于开放式任务。尽管有许多强大的图模型 (GM) 可用,但这个想法在图领域中的探索较少,但它们仅限于预定义形式的任务。尽管已经提出了几种将 LLM 应用于图的方法,但它们无法同时处理预定义和开放式任务,而 LLM 则作为节点特征增强器或独立预测器。为了打破这一困境,通过一个名为 GraphTranslator 的翻译器连接预训练的 GM 和 LLM,旨在利用 GM 有效地处理预定义任务,并利用 LLM 的扩展接口为 GM 提供各种开放式任务。为了训练这样的翻译器,提出了一个能够根据节点信息、邻居信息和模型信息构建图文本对齐数据的生产者。通过将节点表示转换为标记,Graph Translator 使 LLM 能够根据语言指令进行预测,为预定义和开放式任务提供统一的视角。
8. Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs(KDD24)
图学习因其广泛的实际应用而引起了极大的关注。最流行的具有文本节点属性的图学习流程主要依赖于图神经网络 (GNN),并使用浅层文本嵌入作为初始节点表示,这在一般知识和深刻的语义理解方面存在局限性。近年来,大型语言模型 (LLM) 已被证明拥有广泛的常识和强大的语义理解能力,彻底改变了处理文本数据的现有工作流程。在本文中,我们旨在探索 LLM 在图机器学习中的潜力,特别是节点分类任务中,并研究两种可能的流程:LLM 作为增强器和 LLM 作为预测器。前者利用 LLM 及其海量知识增强节点的文本属性,然后通过 GNN 生成预测。后者尝试直接使用 LLM 作为独立的预测器。我们在不同的环境下对这两条管道进行了全面、系统的研究。
9.Graph Intelligence with Large Language Models and Prompt Learning(KDD24)
我们基于一种新颖的分类法介绍现有工作,该分类法根据 LLM 在图任务中的作用将它们分为三个不同的类别:增强器、预测器或对齐组件。其次,介绍了一种利用图提示的新学习方法,为增强跨不同任务和领域的图传输能力提供了巨大的潜力。我们将在统一框架内讨论现有的graph提示工作,并介绍开发的用于执行各种graph提示任务的工具。
10. Large Language Models on Graphs: A Comprehensive Survey(TKDE24)
2312.02783 (arxiv.org)![]() https://arxiv.org/pdf/2312.02783
https://arxiv.org/pdf/2312.02783
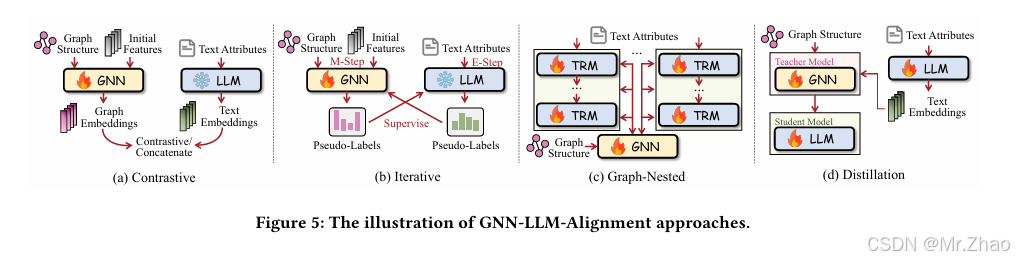
尽管 LLM 已经展示了其纯文本推理能力,但这种能力是否可以推广到图(即基于图的推理)尚未得到充分探索。在本文中,我们系统地回顾了与图上的大型语言模型相关的场景和技术。我们首先将采用图上的 LLM 的潜在场景总结为三类,即纯图、文本属性图和文本配对图。然后,我们讨论了在图上使用 LLM 的详细技术,包括 LLM 作为预测器、LLM 作为编码器和 LLM 作为对齐器,并比较了不同模型的优缺点。
11.A Survey of Large Language Models for Graphs(KDD24)
A Survey of Large Language Models for Graphs (arxiv.org)![]() https://arxiv.org/pdf/2405.08011
https://arxiv.org/pdf/2405.08011
12.Can LLMsEffectively Leverage Graph Structural Information: When and Why(NeurIPs23)
pdf (openreview.net)![]() https://openreview.net/pdf?id=jyfiPivRBH
https://openreview.net/pdf?id=jyfiPivRBH
本文研究了使用结构化数据(特别是图)增强的大型语言模型 (LLM),这是一种在 LLM 文献中尚未得到充分探索的关键数据模式。我们旨在了解何时以及为何将图数据中固有的结构信息纳入其中可以提高 LLM 在文本分类方面的预测性能。为了解决“何时”的问题,我们在文本节点特征丰富或稀缺的环境中研究了各种用于编码结构信息的提示方法。对于“为什么”的问题,我们探讨了影响 LLM 性能的两个潜在因素:数据泄漏和同质性。我们对这些问题的探索表明:(i) LLM 可以从结构信息中受益,尤其是在文本节点特征稀缺的情况下;(ii) 没有实质性证据表明 LLM 的性能显著归因于数据泄漏;(iii) LLM 在目标节点上的性能与节点的局部同质性比率呈强正相关

















 168
168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









