







1. 环境准备
- 三台虚拟机,
192.168.68.101、192.168.68.102、192.168.68.103《win10下VMware15安装CentOS7虚拟机》 - JDK(自行准备)
- hadoop安装包(官网下载地址:https://hadoop.apache.org/releases.html)
2. 创建用户
- 创建hadoop用户,并修改hadoop用户的密码
[root@localhost hadoop-3.3.1]# useradd hadoop
[root@localhost hadoop-3.3.1]# passwd hadoop
vim /etc/sudoers配置 hadoop 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令,在 %whieel 这行下面添加一行,如下所示:
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
- 修改
/data目录所有者和所属组
chown -R hadoop:hadoop /data/
- 三台虚拟机依次添加地址映射
vim /etc/hosts
将下面三行加入文件末尾
192.168.68.101 hadoop1
192.168.68.102 hadoop2
192.168.68.103 hadoop3
- 关闭防火墙(生产不能这么搞,生产开通几个指定端口即可)
firewall-cmd --state #查看防火墙状态
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁用firewalld服务
3. 免密登录
- 到
/home/hadoop/.ssh/目录下,使用 hadoop 用户执行ssh-keygen -t rsa,然后回车三次,会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥) - 执行下面的命令将公钥拷贝到要免密登录的机器上,在另外两台机器上一次重复这两个步骤
ssh-copy-id 192.168.68.101
ssh-copy-id 192.168.68.102
ssh-copy-id 192.168.68.103
- 现在三台机器的 hadoop 用户就可以免密登录了,再添加一个
192.168.68.101的 root 用户免密登录到另外两台机器,用192.168.68.101的 root 用户,执行下面的命令
cd ~
cd .ssh
ssh-keygen -t rsa
ssh-copy-id 192.168.68.101
ssh-copy-id 192.168.68.102
ssh-copy-id 192.168.68.103
.ssh文件夹下的文件功能解释
| 文件名 | 功能 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
4. 安装部署
- 将安装包分别上传到三台虚拟机

- 执行命令
tar -zxvf hadoop-3.3.1.tar.gz -C /data/解压到/data目录下

- 三台虚拟机依次添加环境变量,编辑
/etc/profile文件,添加以下内容,然后source /etc/profile保存,执行hadoop version命令检查是否添加成功
#HADOOP_HOME
export HADOOP_HOME=/data/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 进入
/data/hadoop-3.3.1/etc/hadoop路径,执行命令vim core-site.xml,编辑核心配置文件,添加以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置NameNode的URL -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.68.101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录,是hadoop文件系统依赖的基本配置,默认位置在/tmp/{$user}下,是个临时目录,一旦因为断电等外在因素影响,/tmp/${user}下的所有东西都会丢失 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-3.3.1/data/tmp</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
- 执行命令
vim hdfs-site.xml,编辑 HDFS 配置文件,添加以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop-3.3.1/data/namenode</value>
</property>
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop-3.3.1/data/datanode</value>
</property>
<!-- NameNode web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.68.101:9870</value>
</property>
<!-- SecondaryNameNode web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.68.103:9868</value>
</property>
</configuration>
- 执行命令
vim yarn-site.xml编辑 YARN 配置文件,添加以下内容:
<?xml version="1.0"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.68.102</value>
</property>
<!-- 为每个容器请求分配的最小内存限制资源管理器(512M) -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 为每个容器请求分配的最大内存限制资源管理器(4G) -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- 虚拟内存比例,默认为2.1,此处设置为4倍 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 执行命令
vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 执行MapReduce的方式:yarn/local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 在
/data/hadoop-3.3.1/etc/hadoop路径下,执行命令vim workers配置 workers(注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
192.168.68.101
192.168.68.102
192.168.68.103
- 创建对应目录
mkdir /data/hadoop-3.3.1/data/datanode
mkdir /data/hadoop-3.3.1/data/tmp
- 执行以下命令将配置好的 hadoop 安装包分发到另外两台机器
scp -r hadoop-3.3.1 root@192.168.68.102:/data/
scp -r hadoop-3.3.1 root@192.168.68.103:/data/
- 集群第一次启动,需要在主节点格式化 NameNode(均使用 hadoop 用户)(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化)
hdfs namenode -format
- 使用 hadoop 用户启动 HDFS
sbin/start-dfs.sh
- 在
192.168.68.102上启动 YARN
sbin/start-yarn.sh
jps查看三台虚拟机的服务进程是否如下表所示
| 192.168.68.101 | 192.168.68.102 | 192.168.68.103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| Yarn | NodeManager | ResourceManager NodeManager | NodeManager |
- Web 端查看 HDFS 的 NameNode(可以在
Utilities=>Browse the file system查看 HDFS 目录结构)
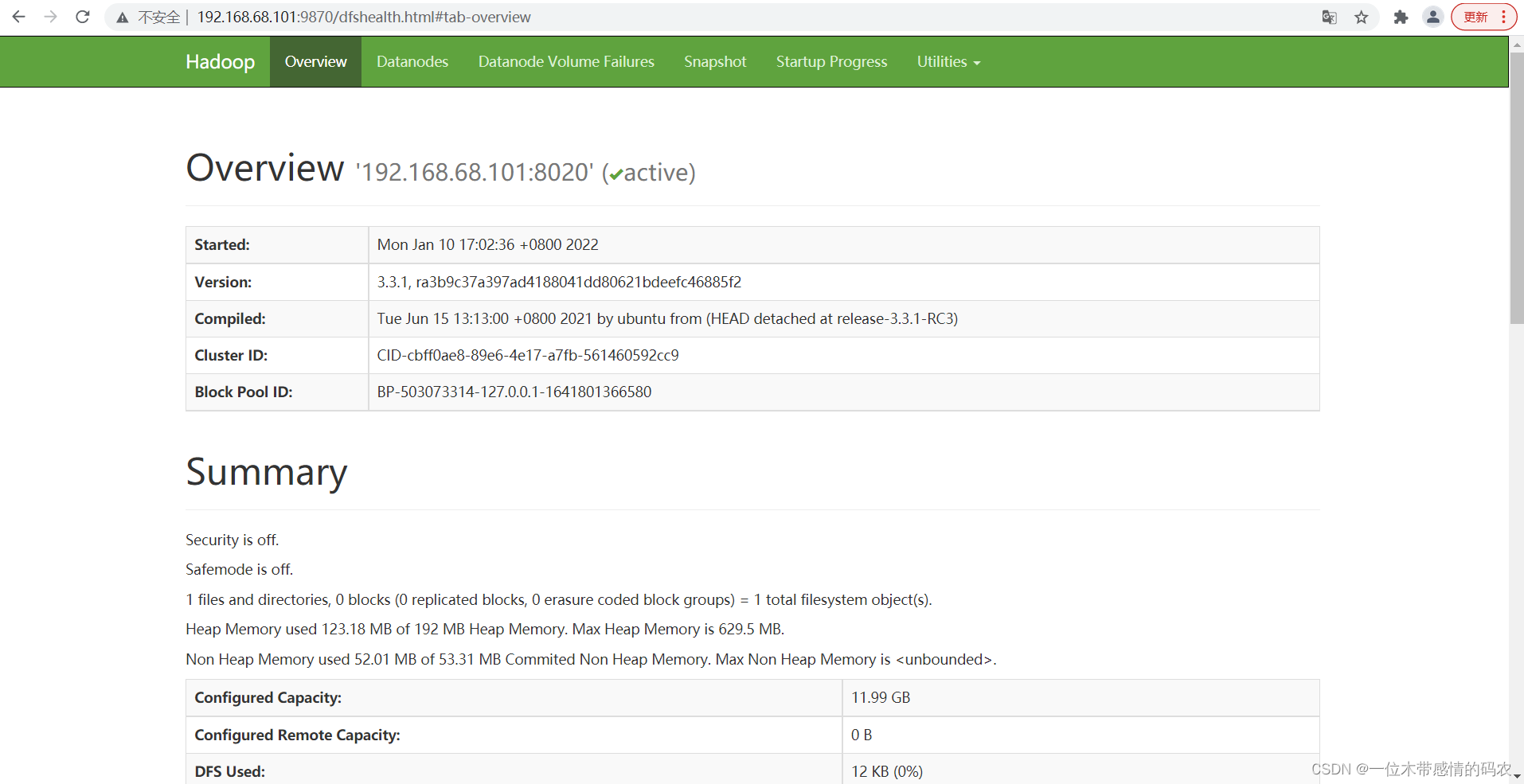
- Web 端查看 YARN 的 ResourceManager

5. 集群基本测试
- 上传文件到集群
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -mkdir /input
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -put /data/input/1.txt /input
- 前往 HDFS 文件存储路径,查看 HDFS 在磁盘存储文件的内容
[hadoop@localhost subdir0]$ pwd
/data/hadoop-3.3.1/data/dfs/data/current/BP-503073314-127.0.0.1-1641801366580/current/finalized/subdir0/subdir0
[hadoop@localhost subdir0]$ ls
blk_1073741825 blk_1073741825_1001.meta
[hadoop@localhost subdir0]$ cat blk_1073741825
hello hadoop
stream data
flink spark
- 下载文件
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -get /input/1.txt /data/output/
[hadoop@localhost hadoop-3.3.1]$ ls /data/output/
1.txt
[hadoop@localhost hadoop-3.3.1]$ cat /data/output/1.txt
hello hadoop
stream data
flink spark
- 执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
-----------------------------------------------------------------------------------------------------------
查看/output/下的文件内容(windows浏览器web页面拉取文件查看时,需在C:\Windows\System32\drivers\etc\hosts中添加 2.4 节说过的地址映射)
data 1
flink 1
hadoop 1
hello 1
spark 1
stream 1
- 计算圆周率(计算命令中 2 表示计算的线程数,50 表示投点数,该值越大,则计算的 pi 值越准确)
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 2 50
-----------------------------------------------------------------------------------------------------------
Job Finished in 23.948 seconds
Estimated value of Pi is 3.20000000000000000000
6. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容(三台虚拟机均需):
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.68.101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.68.101:19888</value>
</property>
- 在
192.168.68.101启动历史服务器
开启:mapred --daemon start historyserver
关闭:mapred --daemon stop historyserver
-----------------------------------------------------------------------------------------------------------
#jps
15299 DataNode
15507 NodeManager
15829 Jps
15769 JobHistoryServer
15132 NameNode
- 查看
JobHistory
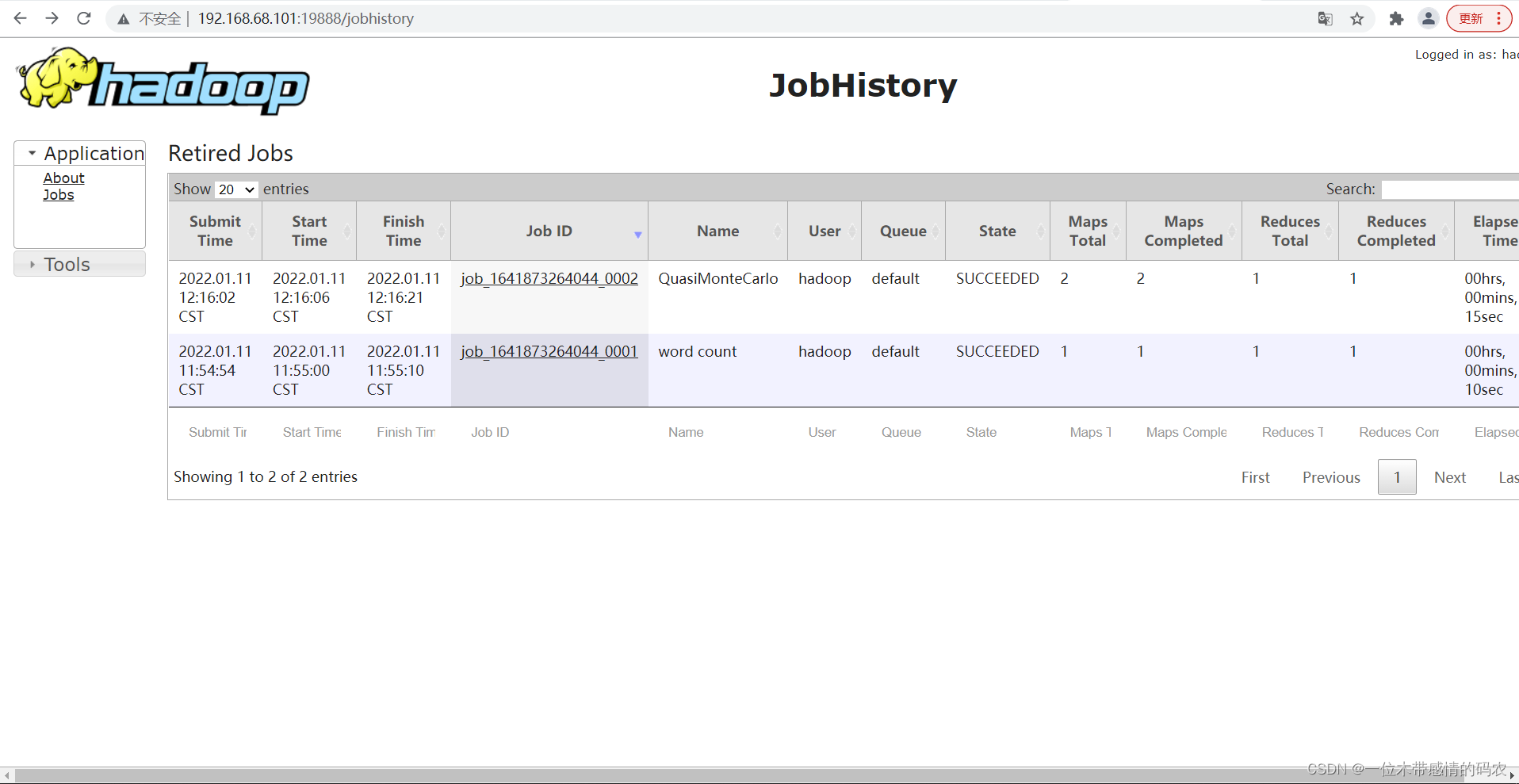
7. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。

日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
vim yarn-site.xml配置 yarn-site.xml,添加下面的内容(三台均需):
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.68.101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<!--<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>-->
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<!--<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>-->
- 重启服务,执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
- 查看日志
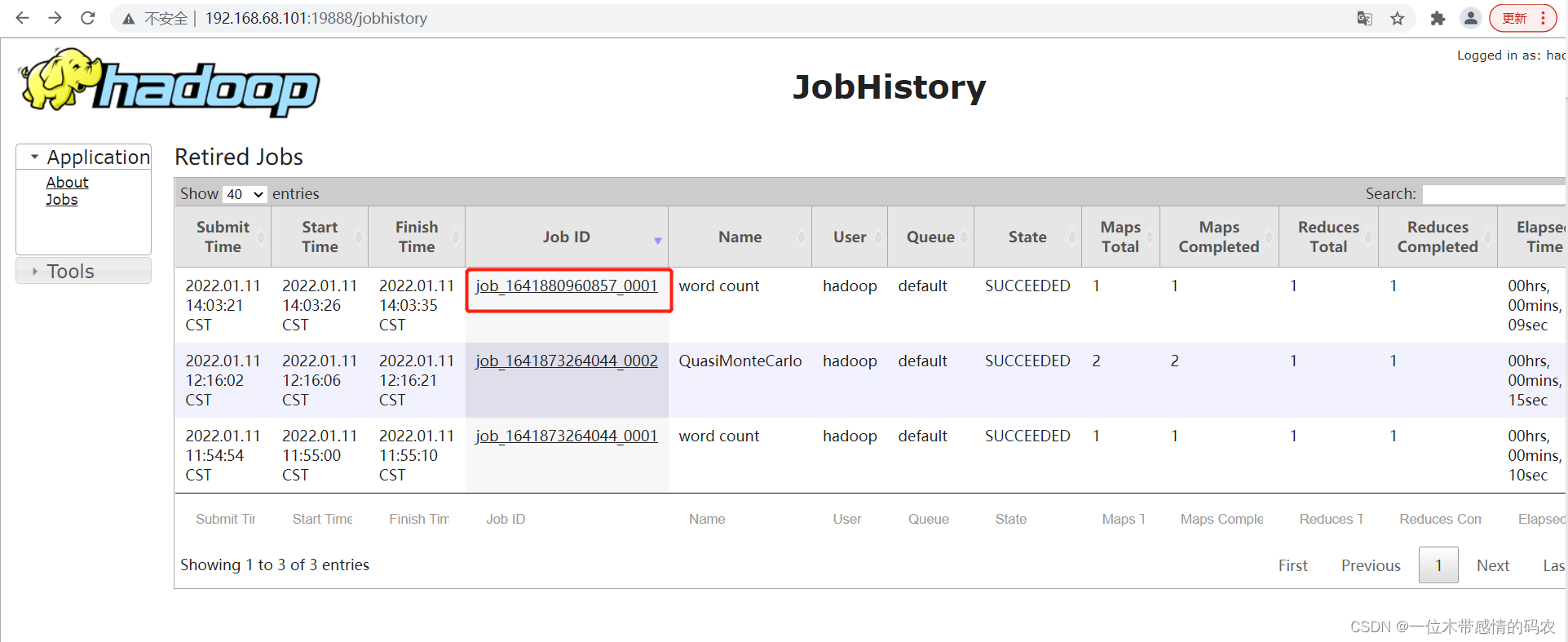
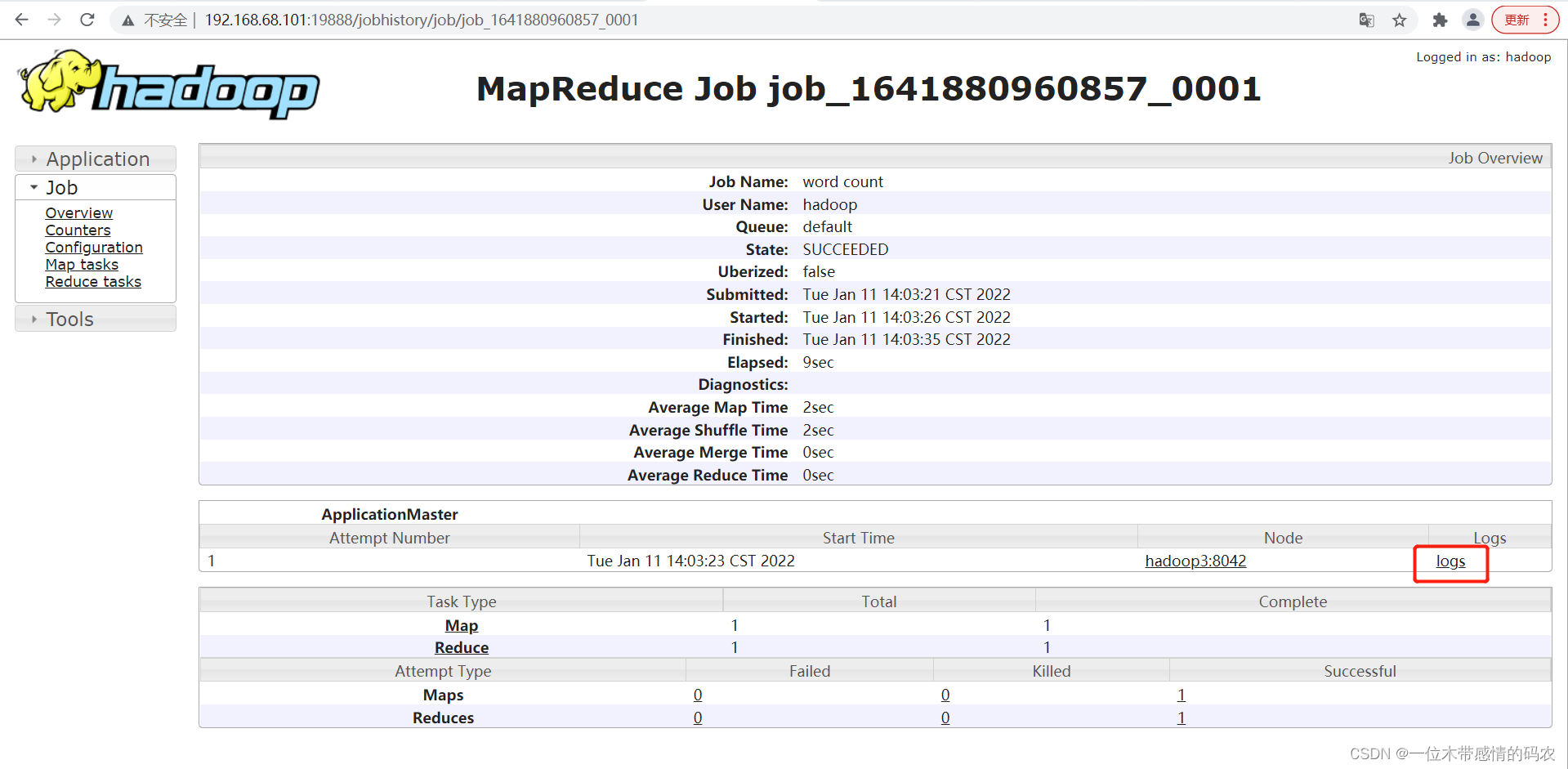

8. 集群启动/停止命令总结
- 各个模块分开启动/停止(前提配置ssh)
- 整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh
- 整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
- 各个服务组件逐一启动/停止
- 分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
- 启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
9. 集群群起脚本
vim myhadoop.sh添加下面内容并保存
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh 192.168.68.102 "/data/hadoop-3.3.1/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh 192.168.68.102 "/data/hadoop-3.3.1/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
chmod +x myhadoop.sh赋予脚本执行权限- 启动/停止集群
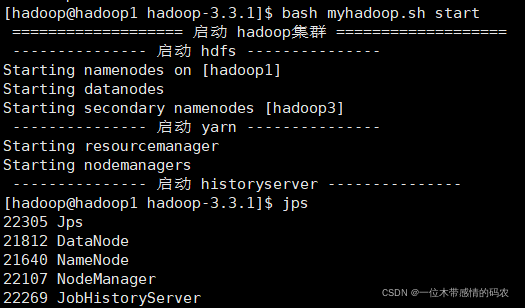
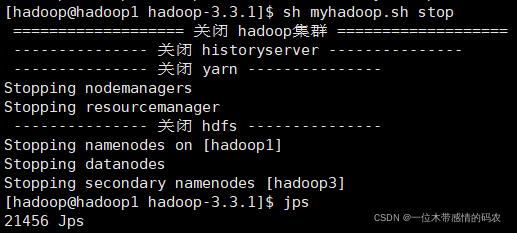
10. 常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000 / 9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |



















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











