






Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人首次在《Attention is All You Need》提出。Transformer架构引入了自注意力机制(self-attention mechanism),能够有效地捕捉文本中的长距离依赖关系,并在并行计算方面具有显著优势。
注意:理解本文需要有一定的深度学习的知识,比如全连接神经网络、残差神经网络、LSTM、word embedding、AutoEncoder等等。
1. Transformer能做什么?
Transformer在诸多领域都有出色的表现,主要包含如下基本任务:
- 机器翻译:例如我们常用的google翻译
- 文本生成:例如ChatGPT
- 语音系统:例如将语音转换为文字
- 多模态处理:例如图文生成
可以看到,相比于专用于时间序列的一些深度学习模型(LSTM、RNN),或者专用于计算机视觉(Computer Vision)的模型(如CNN),Transformer横跨两大领域,简直逆天。
所以,你能用它在你的领域产生什么样的火花?后面我们继续讨论
2. 整体架构: Encoder-Decoder
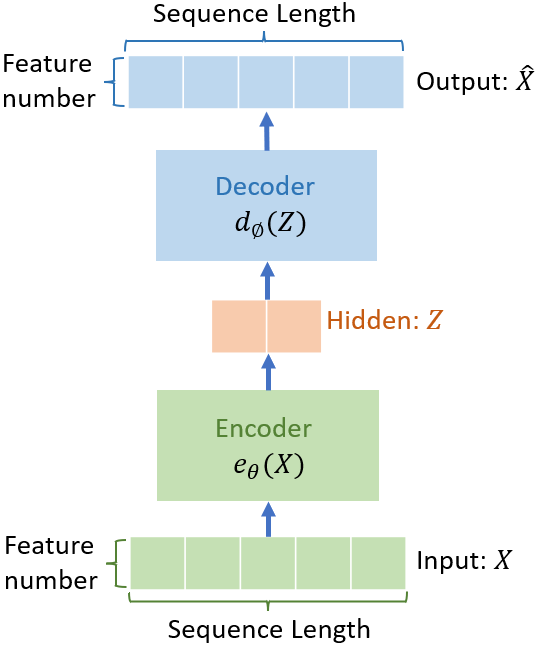
总体来说,Transformer与全连接神经网、CNN或者LSTM一样,是一种深度神经网络结构。Transformer的主体是Encoder-Decoder架构(AutoEncoder自编码器其实也是这种结构),即包含了Encoder和Decoder两个部分。如下图所示。简单理解就是:输入X->Encoder->潜在表示(抽象的概念)->Decoder->输出Y
当预测目标Y与X一致的时候,那Encoder-Decoder就变成了AutoEncoder了。
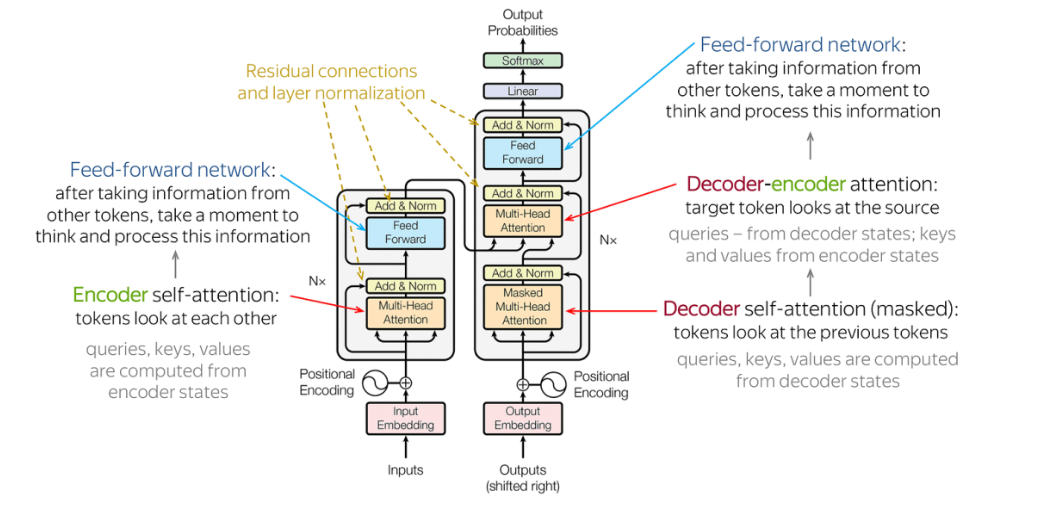
尽管各类教程都用原论文当中的这个图来表示Transformer架构,但是对于新手来说可能不太友好,因此这里对该结构进行一个简化表示,如下图所示。
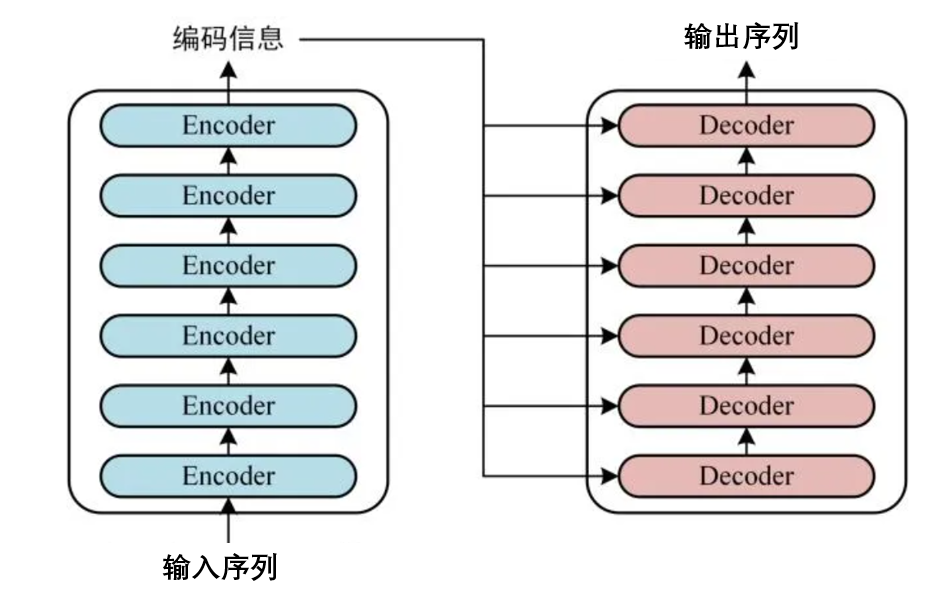
可以发现该结构包含如下特征:
- 左侧包含6个Encoder,右侧6个Decoder(至于为什么是6个,原文就是6个)。
- 左侧的大框是一个大Encoder,最终会输出一个编码信息(抽象概念,无物理意义)。
- 这个编码信息会作为右侧大Decoder的输入,且会输入到每一个小Decoder。
- 右侧大Decoder最终会输出一个序列
- 将预测的输出序列和我们的真实结果一对比,再优化,训练就开始了。
接下来,我将会按照:输入-Encoder-Decoder-输出,四个部分,逐一详细讲解。
3. 详解Transformer的输入
由于Transformer很多时候都是用于自然语言处理类的任务,故本文也用常见的机器翻译任务来进行讲解。
所以,我们的输入是什么?请关注下图中红色方框的部分。
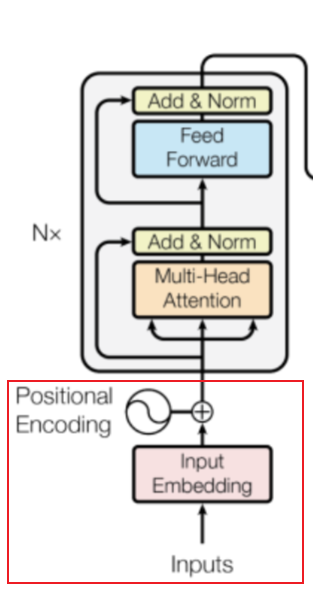
方框中有两个主要内容:①input embedding②positional encoding,对应了序列任务中包含的两个主要特征,一个是序列内容,一个是序列位置。一句话,比如:我爱你,包含了“我”“爱”“你”三个内容,以及三者的前后顺序信息。因此,这两种信息应该都要输入给Transformer。
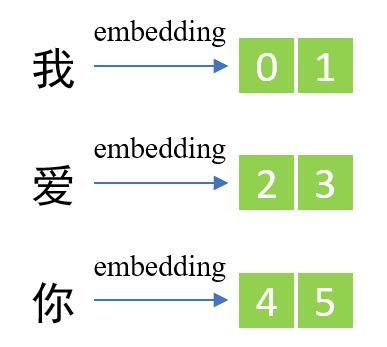
序列内容embedding: 对于数字序列,模型能识别数字;但是对于语言呢?机器没办法识别文字,因此只能将文字转化为数字。这里就要用到word embedding技术了。比如
- 将“我”变成01,“爱”变成23,“你”变成45;
- 这里的数字是随便取的,真实的word embedding肯定不是这个结果;
- 但是需要注意的是,由1个”我“字,变成了0和1共计2个字符,这就是embedding的魅力(升维)。
序列位置embedding: 和内容的embedding一样,将位置信息也变成数字。具体怎么实现的,暂时可以不用去学习,其实就是几个公式或者训练出来的。
具体word embedding怎么实现的可以后面再详细了解,这里只需要知道它是做什么的就行了。最后将内容和位置的embedding矩阵结果逐一对应相加就行了。
4 详解Encoder
Transformer中的Encoder是大名鼎鼎Bert的主体结构
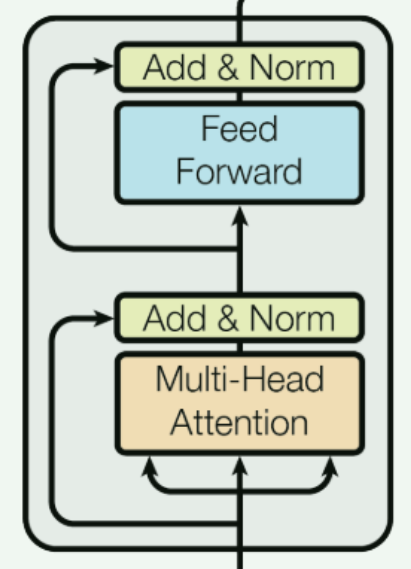
Encoder中,包含了两个最主要的内容,一个是大名鼎鼎的Attention, 一个就是残差网络了。
4.1 Attention是什么?
总结来说,Attention就是一个公式。当然,transformer结构中是Muti-Head Attention,其实本质无任何区别,多头自注意力就是单头的叠加(矩阵纵向的叠加)。
在自然语言处理的任务当中,我们需要结合上下文的信息来输出结果,因此,位置信息尤为重要。Attention就是来解决这个问题的,它引入了三个神奇的向量: Q Q Q、 K K K、 V V V。上图中,由下至上的三个箭头就是表示 Q Q Q、 K K K和 V V V。
- Q:Query,即查询向量
- K:Key,即键向量
- V:Value,即值向量
以Query为例,示意如下。
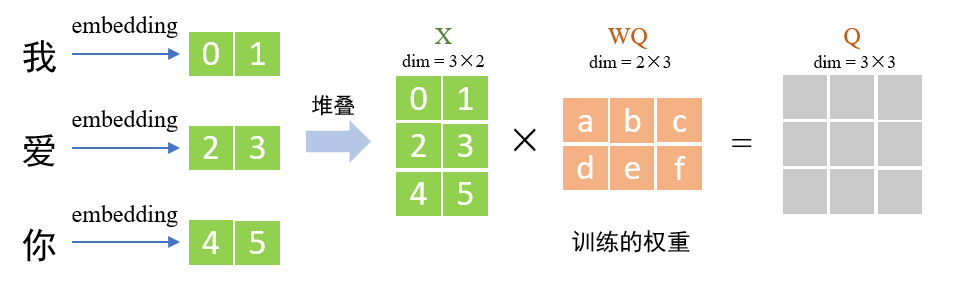
在上图中,X为由各个词向量堆叠而成,WQ为待训练的权重值,两者矩阵相乘即可获得Q向量。K和V也是一样的操作方法。但三者的用处不一样。
获取了Q、K和V之后,利用下面的公式计算就行了。PS: s o f t m a x softmax softmax就是一个归一化的操作, d k d_k dk就一个拍脑袋出来的数(原文中是QKV的维度)。
Z = A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Z = Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Z=Attention(Q,K,V)=softmax(dkQKT)V
利用这个公式,得到的就是Attention。【PS:一些教程利用图片来解释这个公式,其实没必要,只需要知道这样计算就行】
我们来探索一下这个公式所得到的矩阵维度:(深度学习中矩阵维度的把握很重要)
- 定义几个矩阵的维度: X a × b X_{a \times b} Xa×b, W b × c Q W^Q_{b \times c} Wb×cQ。 a a a为句子的长度, b b b为embedding后升高的维度数(可自定), c c c为权重矩阵 W Q W^Q WQ的维度(可自定)
- 可得到 Q Q Q的维度为 a × c a\times c a×c。同理 K K K和 V V V,三者的维度是一致的
- 经过上式计算: Z a × c = Q a × c K c × a T V a × c Z_{a\times c}=Q_{a\times c} K^T_{c\times a}V_{a\times c} Za×c=Qa×cKc×aTVa×c
- 可以发现: Z Z Z的维度与 Q Q Q、 K K K和 V V V是保持一致的
至此,我们已经可以很清楚,**经过Attenion之后的 Z Z Z包含了一个句子上下文的所有信息,**这也是attention的奇妙之处。
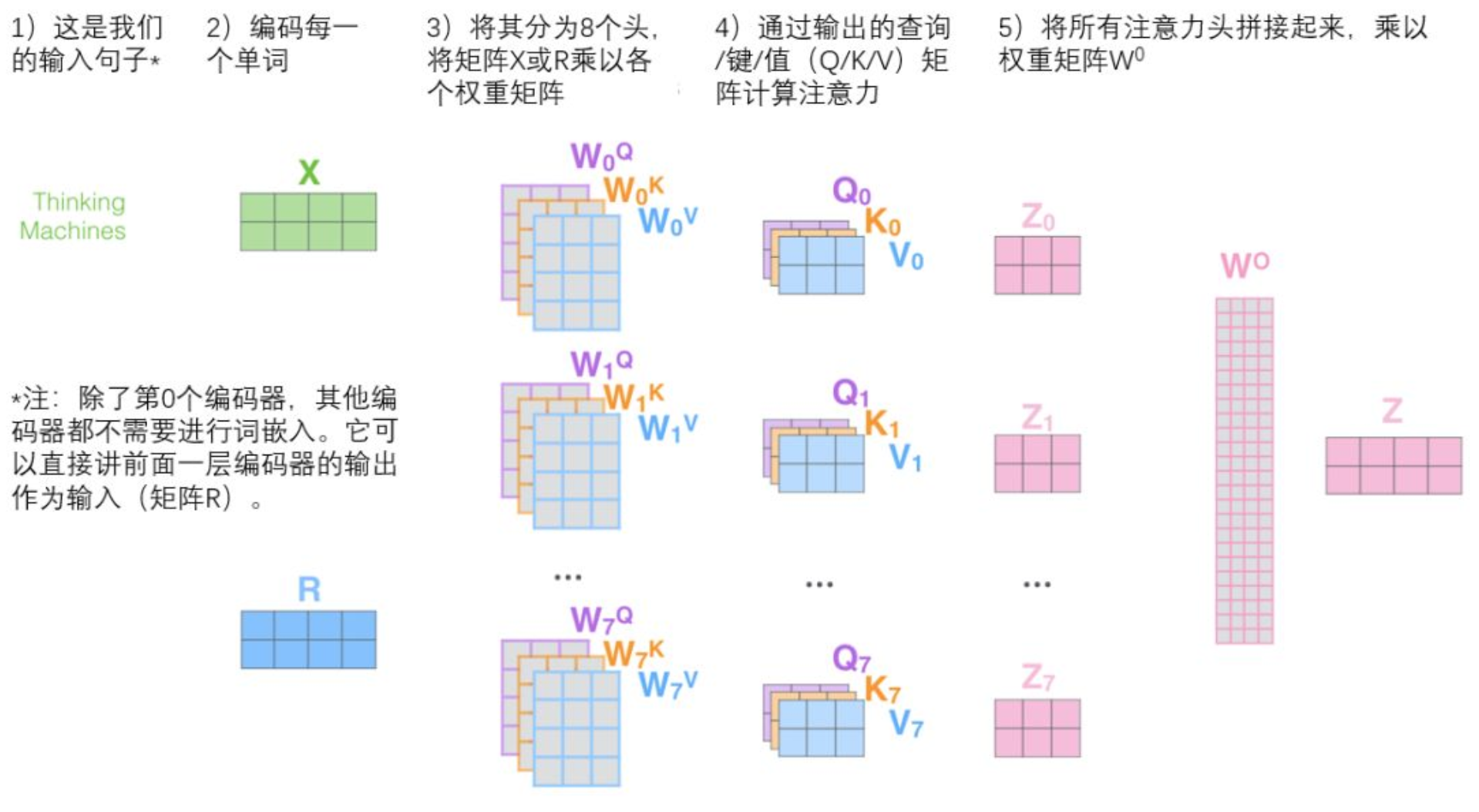
那,Multi-Head Attention(多头注意力) 呢?
其实是一样的,我们多加几个并行的 Z Z Z就可以了。具体操作如下:
- 假设我们使用8头注意力机制,则为 Z 0 , Z 1 , . . . , Z 7 Z_0, Z_1, ...,Z_7 Z0,Z1,...,Z7
- 横向拼接8个 Z i Z_i Zi,变成一个大的 Z Z Z。单个 Z i Z_i Zi的维度为 a × c a\times c a×c, Z Z Z的维度为 a × ( 8 c ) a\times(8c) a×(8c)。
- 我们再将 Z Z Z乘以一个 W ( 8 c ) × b W_{(8c)\times b} W(8c)×b,得到了 Z a × b = Z a × ( 8 c ) × W ( 8 c ) × b {Z_{a\times b}}=Z_{a\times (8c)}\times W_{(8c)\times b} Za×b=Za×(8c)×W(8c)×b
- 可以看到, Z a × b Z_{a\times b} Za×b的维度和 X a × b X_{a\times b} Xa×b是一致的。也就是说,得到的多头Attention是 X X X经过一系列变换后的结果。
4.2 残差结构Add & Norm
残差网络是在深度学习中一种很常见的网络。发明它的主要目的在于解决模型层数增加后梯度消失或爆炸的问题。
这种操作其实很简单,就是将上一层网络的输出 F ( x ) F(x) F(x),再叠加上输入x,变成 F ( x ) + x F(x)+x F(x)+x,然后继续训练。
PS:深度学习中有很多类似的神奇莫名其妙的操作,但确实有效。
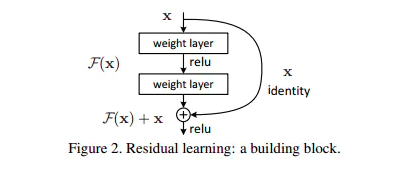
这个神奇的操作也用在了transformer当中,如下图所示( x x x和 z z z的维度相同,这不正好相加了嘛)。
再后面就是常规的Feed Forward和normalization了,没啥好讲的,都比较基础了。最后会得到一个输出,这个是Encoder的输出,后面会作为Decoder的输入。
【transformer用到的是Layer normalization, LN,都差不多,不难】
5 详解Decoder
Decoder是GPT作为预训练的主体,无标签数据,只得到了最终的语义表示
5.1 Decoder的结构特征
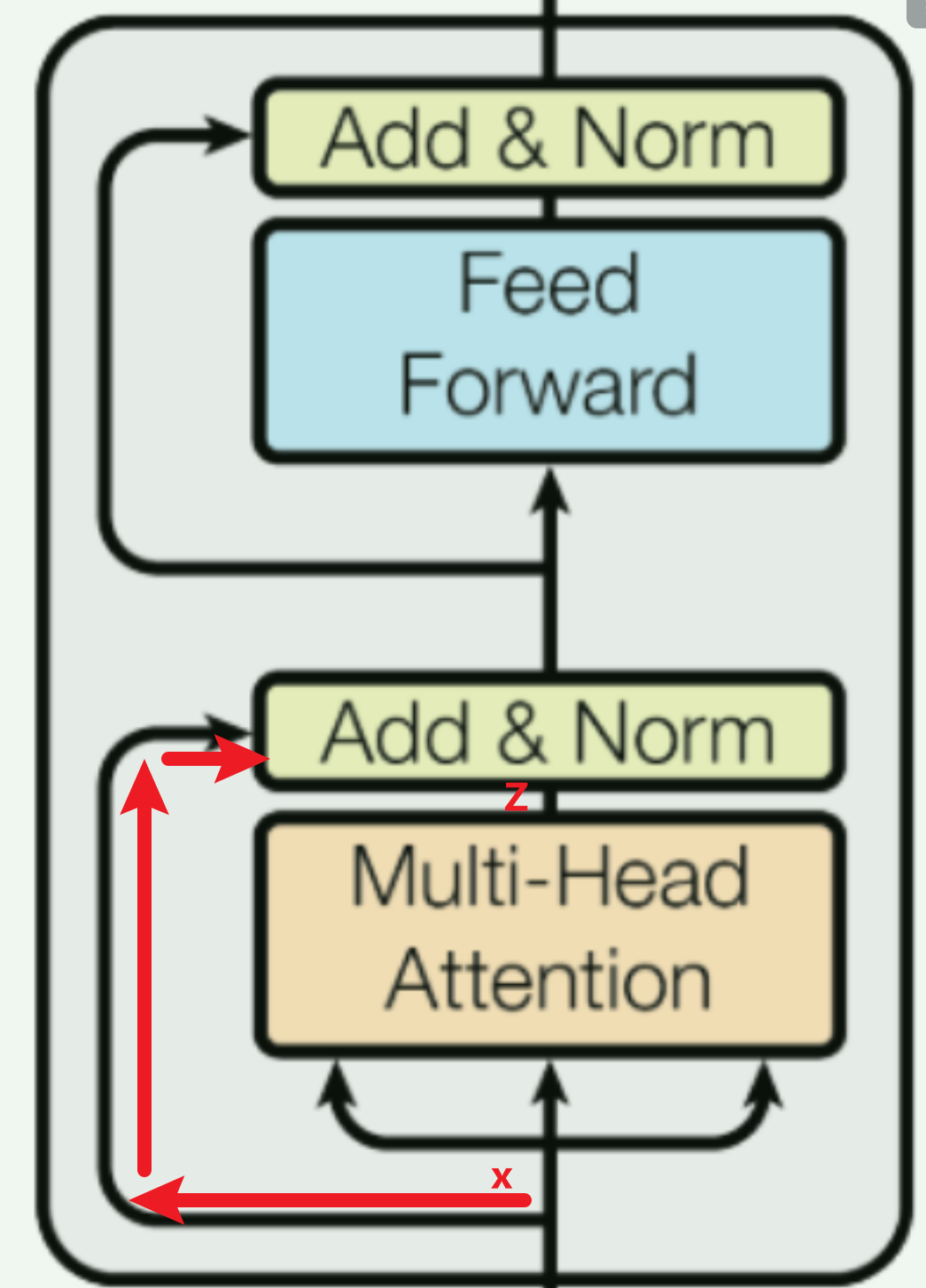
Decoder的主体结构其实和Encoder差不多(如下图),也用到了多头注意力机制,但需要注意几个点:
- Decoder最下方是有我们标签数据(真实输出)作为输入的
- Decoder有两个Multi-head Attention结构的。注意:第一个加入了Masked
- Encoder的输出是在第二个Multi-head Attention作为输入的,而且只放入了 K K K和 V V V。
- 第2个Multi-head Attention的 K K K和 V V V是根据encoder的输出来计算出来的, Q Q Q是根据第一个Multi-head Attention计算出来的。此时,信息已融合!

5.2 Masked multi-head attention
所以,什么是Masked multi-head attention呢?
其实很简单的理解,如下:
- Decoder中是有我们的真实标签作为输入的,如果一股脑的把真实标签输入进去,那相当于信息泄露了,模型还训练个啥?直接啥权重都不用调了
- masked就是加了个面具,把真实标签加了个面具。这个面具只允许真实标签数据的一个词一个词的进入Decoder,所以信息并没有泄露,而仅仅作为一个引导作用。
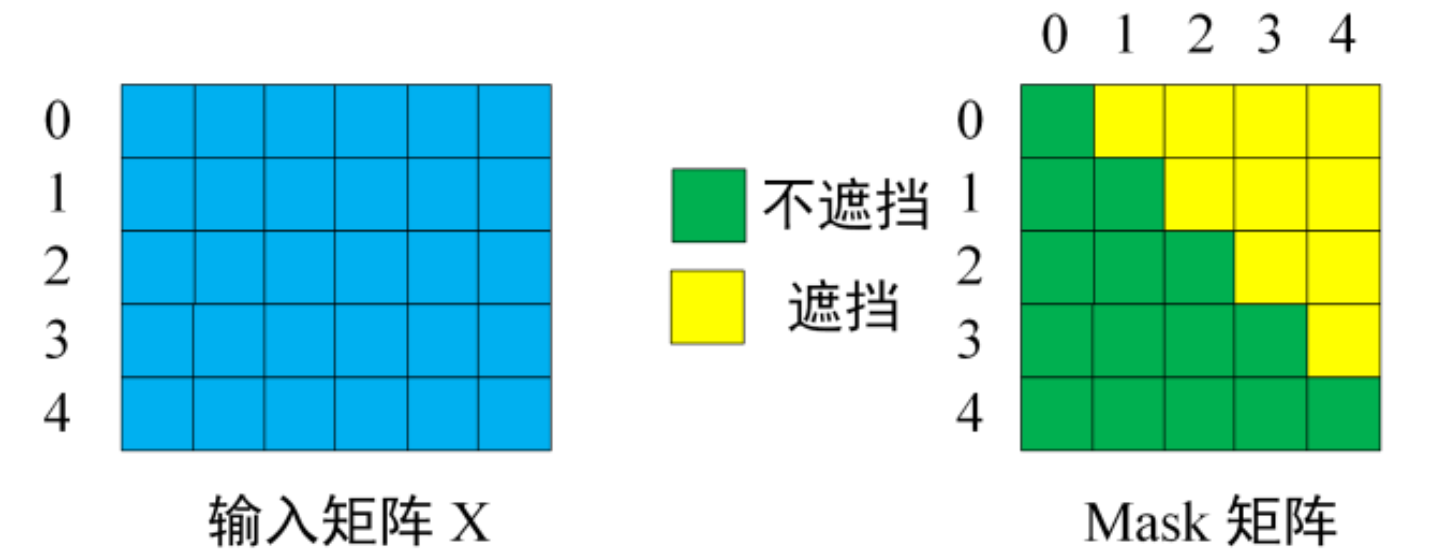
下图很形象地描述了这个特征:
- 假设我们的真实标签为I love you baby。但是我们会加入一个起始标记 <begin> ,即: <begin> I love you baby,分别对应0,1,2,3,4
- 对于第一步,我们输入一个起始标记 <begin> (用0表示)
- 对于第二步,我们使用 <begin> 和 ‘I’ ,即(0和1)
- 对于第三步,我们使用 <begin>、‘I’、‘Love’, 即(0, 1, 2)。依次类推。
在算法层面上,我们使用一个上三角为0的矩阵即可实现这种masked的效果。
6 详解Transformer的输出
对于有标签的数据,我们将Decoder的输出结果,与真实标签的结果求一个损失,再梯度下降,即可实现整套训练流程。
问题一:transformer能输入不同长度的句子吗?
答:可以,但是是经过操作的。我刚开始以为句子长度的维度会淹没在attention中,经过仔细分析发现长度并没有淹没。原来我们在训练的时候会尽量让句子保持一致的长度,如果长度不一致,则会使用两种操作:填充(padding) 和截断(truncation) 。填充就是在句子末尾增加一些标记,如,输出的时候去掉这些标记即可。
问题二:训练的时候我们有真实标签,那预测的时候呢?我们没有真实标签,那Decoder下方的输入该怎么解决呢?
答:其实很好解决。我们只需要添加引导词标记即可实现整个句子的预测。具体预测流程是:
- 我爱你+= I
- 我爱你+I = I love
- 我爱你+I love = I love you
这其中的奥妙需要自己去理解了。
提示:“我爱你”就是Encoder的输出。就是引导词。Decoder将上一步预测出来的"I"又作为下一步的输入了,依次推进。这就是masked multi-head attention的作用。
7 结论
Transformer很玄妙,用处也很多,关键在于如何去针对自己的应用场景来使用它。以下是我个人能想到的学术界的一些应用场景:
- 时间序列数据压缩
- 异常数据诊断
- 常规的回归任务应该都能胜任















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









