







 本文介绍了MRIcron这款医学影像处理软件,包括Windows和Linux环境下的安装、使用方法,重点讲解了如何通过图形界面和命令行批量转换dcm格式到nii。
本文介绍了MRIcron这款医学影像处理软件,包括Windows和Linux环境下的安装、使用方法,重点讲解了如何通过图形界面和命令行批量转换dcm格式到nii。
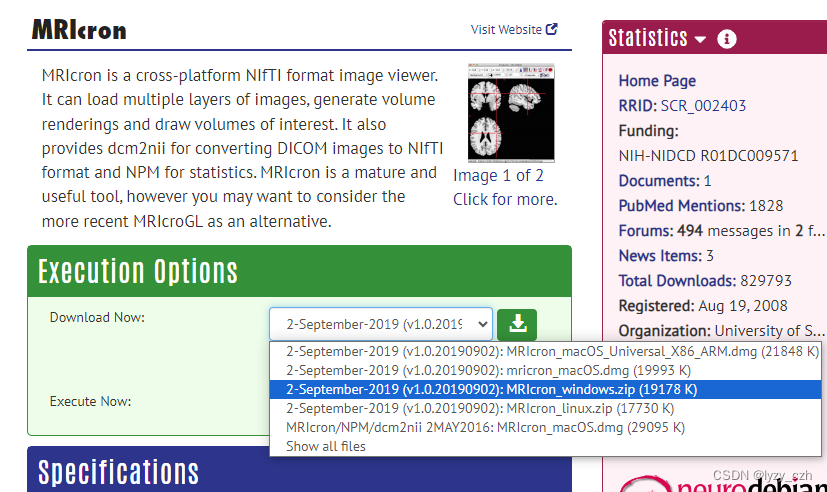
MRIcron下载
MRIcron下载官网
选择适合自己环境的版本,我使用的是windows版本
MRIcron介绍
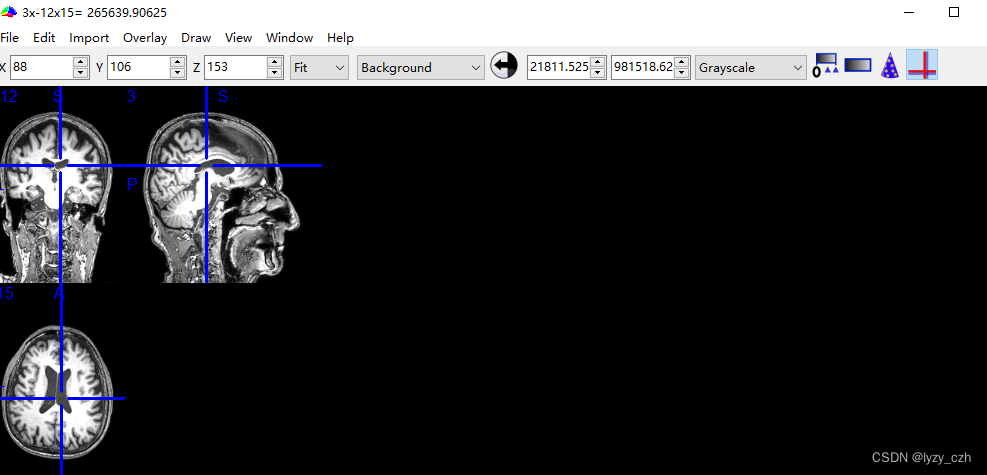
MRICron是一款用于处理磁共振成像(MRI)数据的免费开源软件工具。它是一个功能强大的图像处理程序,主要用于可视化、分析和处理医学影像数据别是MRI数据。界面如下:
除了查看医学图像,MRIcron也有将dcm格式转nii的功能并且支持图形界面转换和命令行转换
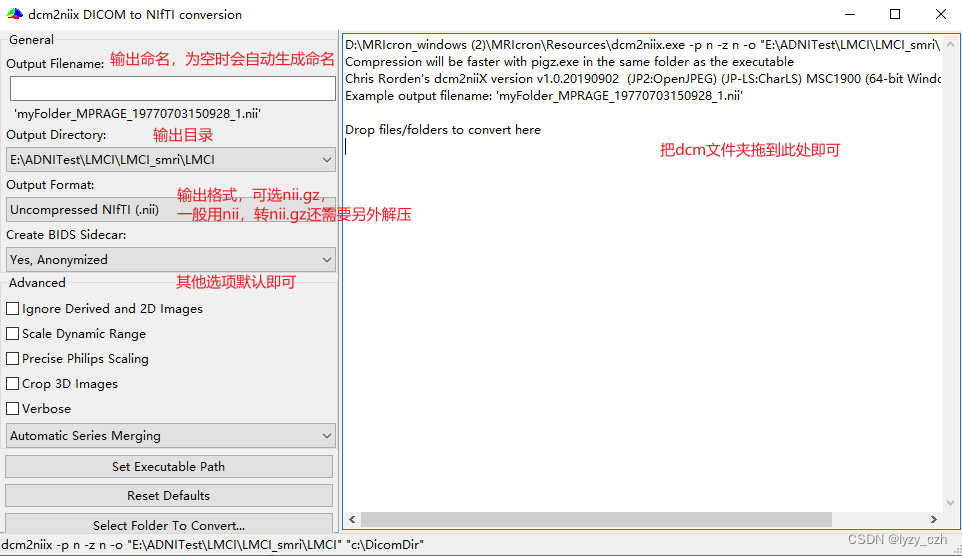
图形界面如下:
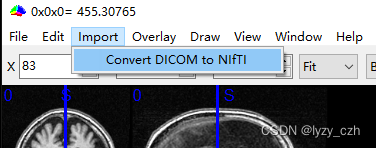
点击import->convert DICOM to NIFTI进入图形界面
命令行使用
在window上,下载好MRIcron后,安装包的Resources目录下会有一个dcm2nii.exe程序,打开window命令行窗口(cmd),转到有dcm2nii.exe的路径下(必要)即可在命令行窗口使用dcm2nii命令,命令行如下:
dcm2niix.exe -f "outputfilename" -i y -l y -p y -x y -v y -z y -o "E:\datasets" "c:\DicomDir"
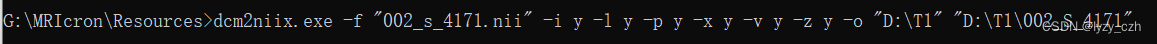
其中,"E:\datasets"是输入nii文件的目录,"c:\DicomDir"是输入dicom的目录,“outputfilename” 是输出nii.gz的文件名。
在Linux上需要先安装dcm2nii
sudo apt-get install dcm2niix
运行命令
dcm2niix -o /path/to/output_folder /path/to/dicom_folder
-o 用于指定输出文件夹。
/path/to/output_folder 是您希望保存NIfTI文件的文件夹路径。
/path/to/dicom_folder 是包含DICOM文件的文件夹路径。
使用dcm2nii.exe批量转换
1、生成路径txt文件
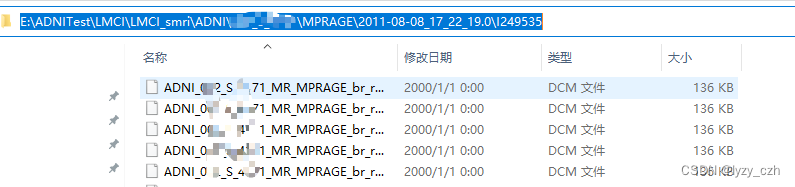
因为是要批量自动的处理文件,因此必须知道每个样本的路径,这里的路径如果是递归的存放在子文件下面的话,只需要读到第一个就行,比如从ADNI上下载的数据是使用子文件命名的形式存储患者信息,如图,我们只需要读到subjectID(就是ADNI的下一个路径)就行,并不需要读到I249535
# 当前目录下所有文件夹下的文件名(不带后缀)写入对应txt文件(以文件夹命名)中
import os
# 指定包含所有样本文件夹的根目录
root_folder = r"E:\ADNITest\EMCI\ADNI" # 修改为你的根目录路径
# 指定保存路径的文本文件
output_txt_file = r"E:\ADNITest\EMCI\EMCI.txt" # 修改为你希望保存路径的文本文件路径
# 打开文本文件以写入样本路径
with open(output_txt_file, "w") as f:
# 遍历根目录下的所有样本文件夹
for subject_folder in os.listdir(root_folder):
subject_folder_path = os.path.join(root_folder, subject_folder)
# 确保当前路径是一个目录
if os.path.isdir(subject_folder_path):
# 将样本文件夹的路径写入文本文件
f.write(subject_folder_path + "\n")
2、批处理
在批处理之前,需要将dcm2nii.exe程序放到项目里面
import sys # 导入sys模块
import os
d2n = 'dcm2niix.exe -f '
para = ' -i y -l y -p y -x y -v y -z y -o '
output_path = "E:\ADNITest\EMCI\EMCI"
# read txt
filepaths = []
for line in open("E:\ADNITest\EMCI\EMCI.txt", "r"): # 设置文件对象并读取每一行文件
filepaths.append(line)
# deal with format transform
for filepath in filepaths:
filepath = filepath[:-1] # 去掉行位的换行符
outputname = filepath[22:] # 命名,这里直接从路径里面取,因为我的路径里面包含subjectID,需要根据实际情况调整
# print(filepath[22:])
# 运行cmd命令
cmd = d2n + outputname + para + '\"' + output_path + '\" ' + '\"' + filepath + '\"' # 其中的双引号不可少
os.system(cmd)
print("Congratulation, Done!")
参考链接:https://blog.csdn.net/DragonGirI/article/details/104011541


















 4712
4712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











