










Subtelomeric 5-enolpyruvylshikimate-3-phosphate synthase copy number variation confers glyphosate resistance in Eleusine indica
端粒下区5-烯醇丙酮酸莽草酸-3-磷酸合成酶拷贝数变异赋予牛筋草草甘膦抗性

摘要
基因组结构变异(SV)对生物体进化有深远影响,常作为新遗传变异的来源。基因拷贝数变异(CNV)是SV的一种类型,反复与真核生物的适应性进化有关,尤其是在应对环境压力时。许多杂草植物物种,包括经济重要的牛筋草(Eleusine indica,俗称马唐),已经通过靶点基因的拷贝数变异进化出对广泛使用的除草剂草甘膦的抗性。然而,由于遗传和基因组资源的限制,这些CNV的起源和机制在许多杂草物种中仍然不清楚。为了研究牛筋草中的这一CNV,我们提供了对草甘膦敏感和抗性的牛筋草系的高质量参考基因组,并对草甘膦靶点基因5-烯醇丙酮酸莽草酸-3-磷酸合成酶(EPSPS)的重复进行了精细组装。我们揭示了一个涉及染色体端粒下区的EPSPS独特重排。这一发现增加了对端粒下区作为遗传变异生成器重要性的有限了解,并为除草剂抗性进化提供了另一个独特的例子。
引言
牛筋草(Eleusine indica)是全球热带和亚热带地区最具经济重要性的杂草物种之一,常见于侵染谷物(特别是水稻)、豆类、棉花、蔬菜作物和草坪系统。几十年来,为控制牛筋草使用的除草剂草甘膦对其抗性进化施加了巨大的选择压力。草甘膦是一种非选择性除草剂,靶向植物体内负责芳香族氨基酸合成的关键酶——5-烯醇丙酮酸莽草酸-3-磷酸合成酶(EPSPS)【1】。在某些情况下,牛筋草的草甘膦抗性是由EPSPS靶点基因突变引起的,例如Pro106单点突变和Thr102Ile与Pro106Ser(即TIPS)双重突变【2】。然而,更为常见的抗性机制是EPSPS拷贝数变异(CNV),这是一种基因组结构变异(SV)【3】。由于牛筋草中同时存在这两种机制,一些种群或个体可能同时拥有EPSPS的拷贝数变异和靶点突变,并且这些拷贝中的一些或全部可能带有一个或多个突变【4】。
基因组结构变异(SV)对生物进化具有深远影响【5】。不同于其他形式的遗传变异(如单核苷酸多态性SNPs),SV并不总是以恒定速率发生【6】。SV的形成通常由环境、可转移元素活动、遗传、杂交事件和染色体组织等多种因素引发【7】。在植物中,SV是一类广泛的变异,涵盖了小规模的事件,如顺式/反式重复、串联重复和倒位,以及大规模事件,如染色体臂倒位甚至多倍体化【8】。基因拷贝数变异(CNV)可以直接影响基因表达,而无需改变基因本身的核苷酸序列。此外,随着时间的推移,额外的基因拷贝常常会发生分化,最终可能实现新功能化或亚功能化,增加遗传多样性【9】。
基因组中的某些区域和基因家族尤其容易产生SV和CNV。首当其冲的是高度重复的序列区域,这些区域由于姐妹染色单体、同源染色体甚至非同源染色体的错位,往往发生不等交换【10】。染色体末端的端粒和端粒下区通常具有高度重复性。端粒下区的定义并不固定,因物种不同而异,但通常指紧邻端粒的下一段50–100 kb的基因组区域。虽然端粒下区通常基因较少,但由于交换频繁,它们可以成为新CNV事件的来源。例如,研究发现普通菜豆(Phaseolus vulgaris)中的某些抗病基因位于或接近端粒下区,由于它们与端粒下区的邻近性,这些R基因发生了高度重复,从而导致特定的抗病表型【11】。这一现象同样适用于单子叶植物。在六倍体小麦(Triticum aestivum)中,端粒下区的亚基因组间基因区域的共线性普遍较低,部分原因是CNV的高发生率【12】。端粒下区中的CNV不仅限于植物;在人类端粒下区,CNV约占染色体最远端100 kb区域的80%【13】。
得益于廉价且普及的基因组测序技术,我们才刚刚开始了解SV作为新遗传变异来源的重要性【14】。诸如1001基因组计划【15】等项目正在深入研究SV及其在拟南芥(Arabidopsis thaliana)中的重要性。此外,已经有许多其他例子展示了SV在作物和非作物进化中的重要性,以及它们对表型产生的巨大影响【6,16,17,18】。SV最引人注目的实例之一是杂草物种中草甘膦(即Roundup)抗性进化的过程,尤其是对行作物生产的影响。在CNV导致草甘膦抗性的情况下,植物过度产生EPSPS酶,需要极大量的草甘膦才能抑制整个EPSPS蛋白池。
至少有九种不同的单子叶和双子叶杂草物种通过EPSPS CNV独立进化出草甘膦抗性,这是趋同进化的惊人例子【19】。更进一步,每种物种以独特的方式进化出这些CNV。第一个被发现的EPSPS CNV是在藜科植物Amaranthus palmeri中【20】。最终发现,EPSPS基因是通过一个新型的、额外的染色体外环形DNA(称为“复制子”)重复的【21,22】。该复制子独立于Amaranthus palmeri的核心基因组进行复制,并在细胞分裂时与核心基因组结合【22,23】。其他杂草物种通过更为常见的方式复制EPSPS,例如在粉蒿草(Bassia scoparia)中,EPSPS通过串联重复被复制,据信是由可转移元素活动和不等交换共同导致的【24,25】。尽管对CNV形成机制的研究主要集中在美洲的双子叶植物,但在全球范围内,单子叶杂草物种更为棘手。
尽管牛筋草具有全球经济重要性,其分子生物学和基因组学研究由于缺乏高质量的参考基因组和其他分子工具而一直困难重重【26,27】。在本研究中,我们生成了对草甘膦敏感(GS)个体的近乎完整的基因组组装以及对草甘膦抗性(GR)个体的几乎完整的基因组组装。此外,我们利用基因组重测序、比较基因组学和转录组学技术,鉴定出牛筋草EPSPS CNV事件所涉及的完整基因组区域,并提供了驱动基因拷贝数增加机制的见解。这项工作深入探讨了该草种的EPSPS CNV的性质,并描述了端粒下区重复如何推动除草剂抗性。
结果与讨论
基因组组装、注释及概述
我们利用PacBio Sequel II和长程相互作用(Hi-C)数据集组装了一个草甘膦敏感(GS)牛筋草的染色体级别基因组。该组装包含9条染色体,总长度为509,878,742碱基对,经过Benchmarking Universal Single-Copy Orthologs(BUSCO)【28】分析估计其完成度约为97.8%,其长末端重复(LTR)组装指数(LAI)【29】得分为18.77(见补充表1和表2)。我们使用de novo Isoseq数据集进行基因模型的构建,并通过同源性分析及其他蛋白质结构域预测软件为预测的基因指定功能。最终在GS牛筋草基因组中预测了27,487个基因模型(BUSCO:92.1%;见补充表2)。此外,我们使用一个来自草甘膦抗性(GR)个体的单个PacBio HiFi数据集,组装了另一个染色体级别的基因组(>99%的基因组位于15个contigs中),长度为541,164,105碱基对(见补充表1)。该GR基因组的BUSCO完成度估计为97.8%,LAI得分为16.85(见补充表2)。使用相同的注释流程,GR牛筋草基因组中预测了29,090个基因(BUSCO:92.2%;见补充表2)。先前的研究通过qPCR和Sanger测序确认了该抗性个体通过增加EPSPS基因拷贝数作为其主要草甘膦抗性机制【4】。
在GS和GR基因组中,基因密度和转座子元素密度平均呈反向变化;基因密度在着丝粒附近下降,而在染色体臂的远端部分增加,转座子元素的密度则相反(图1)。在着丝粒区域,LTR转座子(如Copia和Gypsy)及其他转座子元素的数量较多(图1)。尤其是Gypsy超家族的转座子密度最高(图1)。GS基因组中包含59.89%的重复序列,其中2.53%为DNA转座子,40.21%为逆转录元件(其中38.29%为长末端重复元件)。GR基因组包含58.30%的重复序列,其中2.08%为DNA转座子,35.71%为逆转录元件(其中33.91%为长末端重复元件)。在两种基因组组装中,最主要的转座子家族均被分类为Gypsy转座子(约占25%),Copia转座子是第二多的(约占11%)。其他转座子在每个基因组中的比例均低于2%。在我们对GS和GR基因组进行重复内容注释的粗粒度层面上,未发现显著差异。
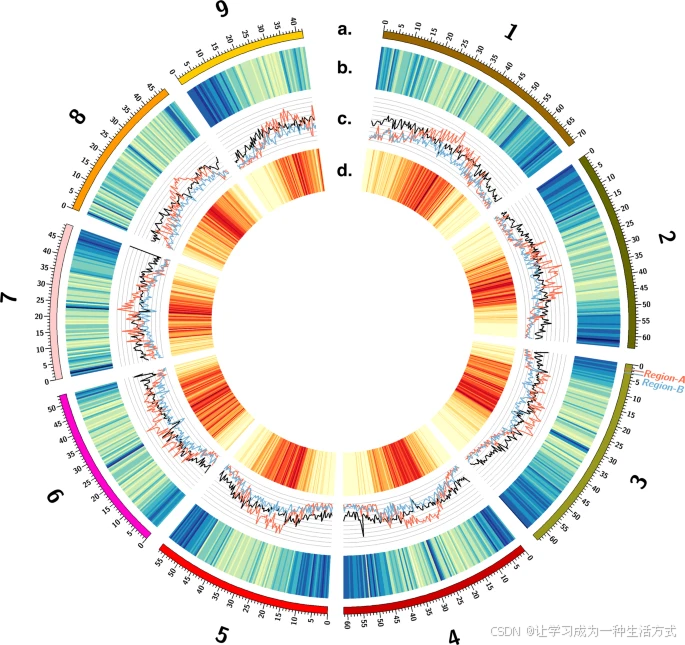
Circos图展示了:(a) 作为索引的1至9号染色体的长度(Mb),以及相应的(b) 基因密集(蓝色)和基因稀疏(黄色)的基因组区域,(c) Gypsy(红色)、Copia(蓝色)和其他(黑色)转座子家族在整个基因组的覆盖范围(比例尺:0-50%),(d) 转座子元素密集(红色)和转座子元素稀疏(黄色)的基因组区域,以及端粒下区EPSPS盒的区域A(红色标签)和区域B(蓝色标签)的原生位置。源数据以源数据文件的形式提供。
牛筋草(E. indica)具有拟南芥类型的端粒序列(TTTAGGGn)【30】,这些序列以串联重复的形式出现在染色体末端,重复长度可达39,800 bp。在GS基因组中,2号、3号、4号和9号染色体在一端具有这些串联端粒重复,而其余染色体(1号、5号、6号、7号和8号)没有包含任何末端串联端粒重复(图2)。在GR基因组中,1号、2号、4号、7号和8号染色体在两端都具有串联端粒重复,而3号、5号、6号和9号染色体仅在一端具有串联端粒重复(图2)。这表明我们捕获了GR基因组中大部分但并非全部的全长染色体。相比于GS基因组,GR基因组中从端粒到端粒的覆盖增加可能是由生物因素(如抗性品系的纯合度增加)或计算因素(如不同数量的输入PacBio数据或PacBio读段N50长度)引起的。最有可能的原因是染色体末端的高度重复性和端粒重复序列之间的冗余性,使得在没有使用专门设计来解决这些区域的新技术的情况下,进一步精细化变得困难。
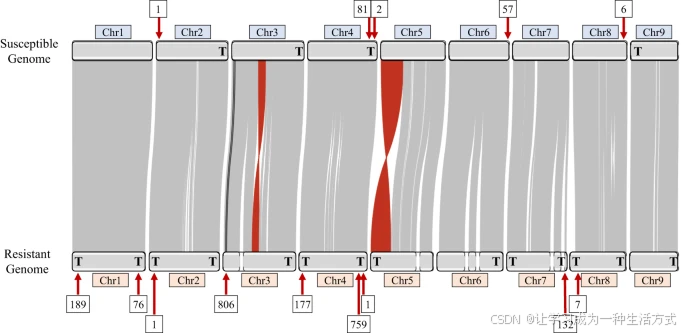
灰色连线表示染色体对之间共享的共线性区域。红色连线表示基因组之间的共线性大规模倒位。黑色连线代表EPSPS盒的Region-A和Region-B在其原始位置的关系。核型图上方和下方框内的数字表示每个位点处端粒下重复序列的拷贝数。核型图上的粗体字母“T”表示组装到达染色体末端(即端粒)的部分。源数据以源数据文件的形式提供。
GS和GR基因组组装具有高度共线性,这体现在几乎完全相同的长片段(>10 kb)的线性排列,这些序列在整条染色体上保持一致(图2)。由于两组装之间存在高度的共线性,稍微碎片化的GR基因组经过手动排序并命名,以最大程度上与GS基因组对齐。在GR组装中,3号和5号染色体由两个contigs组成,6号和7号染色体由三个contigs组成,剩余染色体则为单个contig。
GR基因组中组装了两个大规模倒位:一个位于5号染色体末端,另一个位于3号染色体中部(图2)。当将GR和GS牛筋草PacBio数据集的读段映射到抗性和敏感基因组5号染色体倒位连接点时,结果显示GR中有多个读段支持该倒位,而在GS中没有读段支持5号染色体的当前方向(补充图1)。这可能表明GS基因组中存在组装错误,然而GS基因组的Hi-C数据支持其当前的方向(补充图2)。当对3号染色体的倒位连接点进行相同分析时,结果并不确定,映射到GS和GR基因组(倒位上下游)的读段都很少(补充图3)。同样,GS的Hi-C数据支持其3号染色体的方向(补充图2)。两个倒位都由复杂且重复丰富的DNA区域所包围,这可能部分解释了读段映射不佳的原因。在未来需要时,可以使用抗性品系的光学图谱或Hi-C验证GR中3号和5号染色体的这些倒位,但在没有额外数据的情况下,我们无法确定这些倒位的支持程度;然而,鉴于这些倒位都不影响包含EPSPS的区域,因此它们不太可能与草甘膦抗性有关。
在GS和GR基因组中,草甘膦的靶点EPSPS位于3号染色体距离端粒约1.6 Mb处。在GR基因组中,EPSPS还在23个短的未组装成染色体的contigs中被鉴定出,但这些未组装的contigs总是与通常位于3号染色体距离端粒约2.4 Mb处的序列共同组装,即在EPSPS下游约1 Mb处。为了便于讨论和清晰表达,我们将EPSPS在基因组中的原始位置称为“Region-A”,将与Region-A共同组装的区域称为“Region-B”(图1和图3)。与杂草Bassia scoparia(粉蒿草)中串联EPSPS重复导致草甘膦抗性不同【24,25】,GR基因组中3号染色体的原始位置上仅组装了一个Region-A的拷贝,这表明在随后的重复之前,EPSPS至少经历了一次初始的反向重复事件。
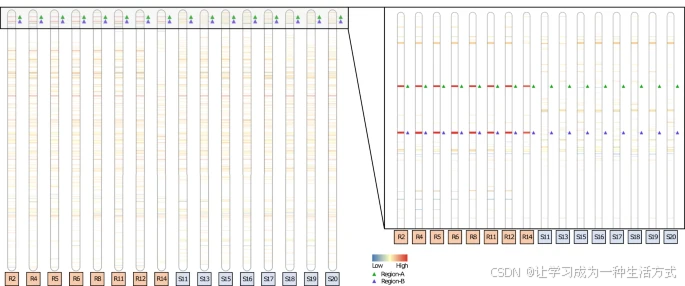
该染色体图显示了在8个草甘膦抗性(R)个体与8个草甘膦敏感(S)个体的牛筋草3号染色体上,不同区域的拷贝数变异情况。图中蓝色表示读深低于平均值的0.25倍的缺失区域,白色表示读深在平均值的0.25倍至4倍之间且p值大于0.01的拷贝数变异区域,红色表示读深超过平均值4倍的重复区域。该图展示了整条染色体(63,742,515个碱基对)的情况以及染色体3前5,000,000个碱基对的放大视图。带宽与表现出拷贝数变异的基因组区域的长度成正比。Region-A(绿色三角形)包含EPSPS基因,Region-B(紫色三角形)是与EPSPS基因共同重复的基因组区域。在R个体中,这两个区域的重复水平约为平均读深的25倍,而在S个体中没有重复。源数据以源数据文件的形式提供。
EPSPS结构变异
对8个草甘膦敏感(GS)和8个草甘膦抗性(GR)的牛筋草基因组进行了Illumina HiSeq X Ten重测序,以确定EPSPS拷贝数变异(CNV)事件在结构上的一致性,以及其他多态性(如SNPs和InDels)。将这些重测序数据比对到GS基因组并分析了以下两方面:(1) 在GR群体中一致变化且与GS个体不同的某些区域的读深变化(指示重复或缺失),以及(2) 读段比对中断裂,表明重排、易位、倒位和重复的存在。所有GR个体中共有34个共享的预测CNV重复事件,其中15个位于伪分子中,19个位于未组装成染色体的contigs中。然而,只有两个CNV,即CNV2和CNV3的拷贝数与拷贝数变异PCR的预测结果一致。CNV2(Region-A;平均读深:22.03)和CNV3(Region-B;平均读深:22.46)在所有个体中的读深几乎相同(表1和图3)。7个GR个体的EPSPS读深大约是背景的25-29倍,唯一的例外是样本R14,其读深仅为8倍(图3)。根据这一观察结果,我们认为该样本是杂合子,而其他7个GR个体在父本和母本基因组中都有拷贝。此外,这些结果表明,在每一个EPSPS CNV的拷贝中,Region-A和Region-B都是共同重复的,且Region-A和Region-B在CNV扩增之前发生了易位和融合。另外,四个其他CNV事件(CNV21、CNV26、CNV29和CNV30)预计有较高的拷贝数(>20×),但这些CNV仅位于未组装成染色体的contigs中,这些contigs主要由高度重复的DNA和/或转座子组成。所有GS个体的Region-A和Region-B的读深均正常,因此这两个区域均未发生拷贝数变异(图3)。
| CNV event number | Chromosome or scaffold | Start | Stop | Length | Average read depth in GR |
|---|---|---|---|---|---|
| CNV1 | Chr1 | 54,792,251 | 54,809,000 | 16,749 | 2.39 |
| CNV2 (A) | Chr3 | 1,666,751 | 1,701,750 | 34,999 | 22.03 |
| CNV3 (B) | Chr3 | 2,719,751 | 2,767,250 | 47,499 | 22.46 |
| CNV4 | Chr4 | 30,001,501 | 30,024,250 | 22,749 | 3.31 |
| CNV5 | Chr4 | 32,703,001 | 32,731,250 | 28,249 | 9.19 |
| CNV6 | Chr5 | 10,538,001 | 10,552,000 | 13,999 | 2.23 |
| CNV7 | Chr5 | 13,291,251 | 13,298,500 | 7249 | 2.22 |
| CNV8 | Chr6 | 120,001 | 124,750 | 4749 | 2.18 |
| CNV9 | Chr6 | 142,751 | 153,250 | 10,499 | 3.40 |
| CNV10 | Chr7 | 27,384,251 | 27,401,750 | 17,499 | 2.03 |
| CNV11 | Chr7 | 35,146,001 | 35,150,750 | 4749 | 2.14 |
| CNV12 | Chr7 | 40,076,251 | 40,112,750 | 36,499 | 3.68 |
| CNV13 | Chr8 | 42,437,251 | 42,510,250 | 72,999 | 2.06 |
| CNV14 | Chr9 | 11,015,251 | 11,024,750 | 9499 | 5.86 |
| CNV15 | Chr9 | 18,044,251 | 18,072,250 | 27,999 | 2.80 |
| CNV16 | Scaffold12 | 46,751 | 94,500 | 47,749 | 3.29 |
| CNV17 | Scaffold12 | 121,751 | 135,250 | 13,499 | 4.66 |
| CNV18 | Scaffold26 | 99,251 | 118,500 | 19,249 | 4.71 |
| CNV19 | Scaffold29 | 32,251 | 58,000 | 25,749 | 3.04 |
| CNV20 | Scaffold29 | 88,251 | 124,750 | 36,499 | 4.28 |
| CNV21 | Scaffold30 | 13,251 | 123,250 | 109,999 | 32.46 |
| CNV22 | Scaffold35 | 10,001 | 120,500 | 110,499 | 2.93 |
| CNV23 | Scaffold36 | 1 | 38,500 | 38,499 | 3.04 |
| CNV24 | Scaffold36 | 52,001 | 88,750 | 36,749 | 2.16 |
| CNV25 | Scaffold36 | 104,751 | 117,250 | 12,499 | 5.38 |
| CNV26 | Scaffold44 | 1 | 93,250 | 93,249 | 47.34 |
| CNV27 | Scaffold45 | 1 | 50,250 | 50,249 | 2.07 |
| CNV28 | Scaffold45 | 68,001 | 91,000 | 22,999 | 5.88 |
| CNV29 | Scaffold47 | 1251 | 80,000 | 78,749 | 45.20 |
| CNV30 | Scaffold49 | 1 | 77,750 | 77,749 | 65.48 |
| CNV31 | Scaffold51 | 1 | 23,250 | 23,249 | 2.25 |
| CNV32 | Scaffold55 | 1 | 16,250 | 16,249 | 3.84 |
| CNV33 | Scaffold56 | 37,251 | 65,500 | 28,249 | 6.15 |
| CNV34 | Scaffold58 | 48,501 | 64,000 | 15,499 | 4.42 |
Region-A在GS基因组中的坐标为Chr3:1,666,751-1,701,750,长度约35 kb,在GR基因组中的坐标为Chr3:2,163,092-2,198,095。Region-A包含草甘膦的靶标EPSPS基因以及其他四个预测的基因:A390、A400、A410和A440。Region-B的长度约为41 kb,在GS基因组中的坐标为Chr3:2,719,751-2,760,750,在GR基因组中的坐标为Chr3:3,206,579-3,247,578,包含四个预测的基因:B510、B520、B560和B570(表2)。EPSPS的TIPS双重氨基酸替换仅在样本R14中发现。在R14中,T102I突变在583个比对到EPSPS的cDNA读段中占12%,P106S突变在562个读段中占12%,每个突变大约出现在8个预测拷贝中的一个。这表明,如前所述,该个体为杂合体,一个单倍型包含EPSPS的CNV,而另一个单倍型包含TIPS突变。与TIPS突变可能相关的是,在含有TIPS突变的所有读段中,同样12%的读段还发现了T102I突变上游28个氨基酸处的同义丙氨酸替换(GCA变为GCG)。在该个体中,TIPS和EPSPS的CNV共存并不令人意外,因为先前研究表明,牛筋草个体可能同时具有叠加的抗性机制,并且与突变相关的适应性代价可以通过未突变的EPSPS拷贝得到补偿。当首次识别到TIPS双重突变时,这种情况就已被预测到【2】,并随后在牛筋草中得到验证【4】。此外,这还表明,在低频率EPSPS CNV的GR杂草中应仔细查找SNPs,作为草甘膦抗性的潜在主要来源。
| Gene ID | Label | Annotation | Coordinates | RNA-seq | ||
|---|---|---|---|---|---|---|
| Glyphosate susceptible (GS) Glyphosate resistant (GR) | Start GS Start GR | Stop GS Stop GR | log2FC | p-value | ||
| Region-A | ||||||
| EleInSChr3g081370 | EPSPS | EPSPS | 1,669,076 | 1,673,225 | 4.6 | 1.6e-11 |
| EleInRChr3_2g092340 | 2,165,535 | 2,169,359 | ||||
| EleInSChr3g081410 | A410 | Ribosomal subunit protein | 1,673,439 | 1,675,161 | 5.8 | 2.8e-11 |
| EleInRChr3_2g092360 | 2,169,409 | 2,171,640 | ||||
| EleInSChr3g081390 | A390 | tRNA 2’-phosphotransferase 1 | 1,675,833 | 1,680,441 | 4.6 | 4.9e-13 |
| EleInRChr3_2g092350 | 2,172,099 | 2,176,989 | ||||
| EleInSChr3g081400a | A400 | Unknown protein | 1,682,414 | 1,687,866 | 1.2 | 0.42 |
| None. | 2,178,757 | 2,184,208 | ||||
| EleInSChr3g081440 | A440 | Unknown protein of E. coracana | 1,695,565 | 1,701,288 | 5.2 | 3e-14 |
| EleInRChr3_2g080580 | 2,192,031 | 2,198,135 | ||||
| Region-B | ||||||
| EleInSChr3g082510 | B510 | DNA repair protein RadA-like | 2,724,808 | 2,735,415 | 5.2 | 6.9e-11 |
| EleInRChr3_2g221600 | 3,211,487 | 3,224,071 | ||||
| EleInSChr3g082560 | B560 | 6-phosphofructokinase 1 (PFK) gene, complete CDS | 2,742,394 | 2,747,873 | 0.41 | 0.78 |
| EleInRChr3_2g119210 | 3,229,211 | 3,234,785 | ||||
| EleInSChr3g082520a | B520 | Putative dual specificity | 2,748,924 | 2,752,196 | 1.1 | 0.03 |
| None. | protein phosphatase DSP8 | 3,235,752 | 3,239,024 | |||
| EleInSChr3g082570b | B570 | E3 ubiquitin-protein ligase 1 | 2,758,205 | 2,759,136 | – | – |
| EleInRChr3_2g091630 | 3,245,033 | 3,245,964 |
在草甘膦抗性(GR)个体中,Region-A和Region-B融合,并在Region-B的起始处插入一个来源不明的3,396 bp区域,称为“Region-I”(图4A、B)。Region-I不包含任何我们能够辨识的预测基因或显著特征。Region-A、Region-B和Region-I共同组成了完整的“EPSPS盒”,这种结构在任何草甘膦敏感的个体中都没有发现(图3a)。在EPSPS盒的两侧,各有一个451 bp的端粒下序列,这种序列也可以在草甘膦敏感和抗性牛筋草基因组的多个染色体末端以及其他禾本科植物的端粒下区中找到。在盒的一侧,端粒下序列在正向重复了12次,在反向重复了31次,起到了反转EPSPS盒的作用。在另一侧,有一个更大的重复阵列,至少包含43次正向重复和294次反向重复(图3a)。我们能够跨越并组装小的重复阵列,但较大的重复阵列变得不明确。根据先前的荧光原位杂交(FISH)实验,EPSPS在GR牛筋草的两个染色体上存在【31】。这些信息表明EPSPS盒并未分散或广泛分布,而是以串联形式位于一个或两个染色体的末端。
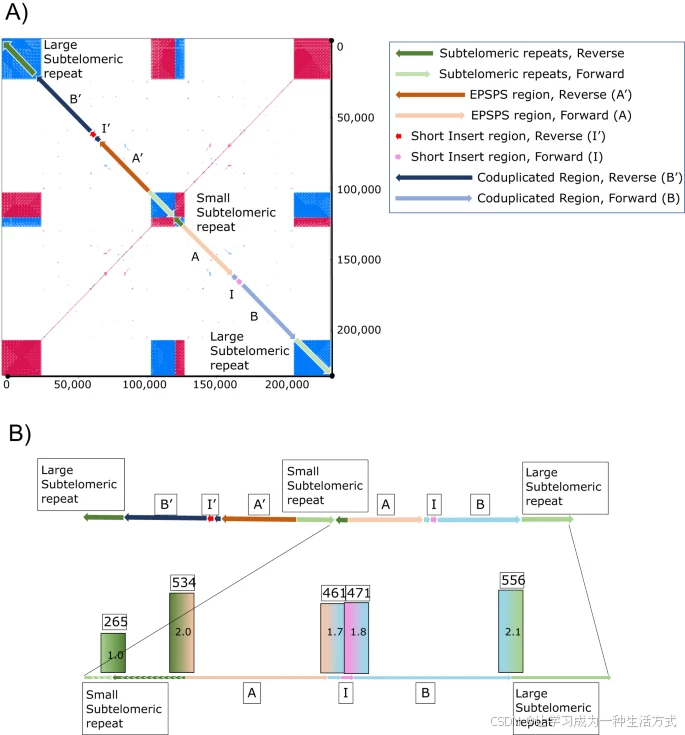
(A: 上面板) EPSPS盒由多个区域组成。Region-A长约35 kb,对应于Chr3:1666751-1701750,包含EPSPS基因。Region-B长约41 kb,对应于Chr3:2719751-2760750。Region-I是插入到Region-B开头的一个来源不明的小型450 bp序列。整个EPSPS盒是以反向组装的,反向时分别标记为A'、B'和I'。一段较短的端粒下重复序列(472 bp串联重复单位)将EPSPS盒的正向和反向拷贝分开,两端则被更长的重复序列包围。(B: 下面板) 将来自抗性基因组的PacBio读段比对到EPSPS盒的正向拷贝,以验证每个区域连接处的正确性(STs-A、A-B、B-I、I-B和B-ST)并量化其丰度。所有连接处均被确认存在且正确组装。此外,我们还确认EPSPS盒在小的端粒下重复区的倒位点的丰度大约是其他连接处的一半(覆盖率为1x,265个读段)。所有其他连接处的丰度约为两倍(461-556个读段)。源数据以源数据文件的形式提供。
为了验证这里提出的EPSPS盒模型,特别是验证每个区域连接,PacBio重测序数据被比对到EPSPS盒(显式检查的连接为:端粒下区-A、A-B、B-I、I-B和B-端粒下区)。大约545个PacBio读段比对到手动组装的EPSPS盒模型,支持端粒下区-A和B-端粒下区的连接;466个读段支持A-B、B-I和I-B的连接;265个读段支持反向和正向EPSPS盒之间的端粒下区连接(图3b)。支持倒位的读段数几乎是支持其他连接处的读段数的一半,这表明倒位的存在比例约为其他部分的一半。也就是说,完整的盒结构实际上由一个正向和一个反向的A-B融合构成,由倒置的较短端粒下重复区连接,并在两侧由更大的端粒下序列包围。
此外,还进行了RNA-seq实验,以研究EPSPS拷贝数变异(CNV)引起的基因表达变化。虽然在抗性个体中EPSPS盒及其中的所有基因均共同重复,但Region-A中的五个基因中有四个显著过表达(p值<0.01,倍增变化>2),而Region-B中的四个基因中只有一个显著过表达(表2和补充图1)。除EPSPS外,来自Region-A的过表达基因包括A410(核糖体亚基蛋白)、A390(tRNA-2'磷酸转移酶)和A440(功能未知的蛋白)(表2)。有趣的是,A410和A390的同源基因也与EPSPS一起在双子叶杂草粉蒿草(Bassia scoparia)中串联重复【24,25】。根据这些蛋白质的注释,它们不太可能直接参与EPSPS CNV的形成。Region-B中唯一显著过表达的基因是B510(log倍增变化: 5.2,p值: 6.9e-11)(补充图4和表2)。B510编码一种RadA样蛋白,这类蛋白在其他重要的杂草物种如粉蒿草中的EPSPS抗性中被发现与EPSPS有关。该基因是否参与了EPSPS CNV的形成尚不清楚;然而,其过表达表明它目前处于活跃状态。RadA蛋白是依赖DNA的ATP酶,参与DNA重组中间体的处理,因而与修复DNA断裂有关【32】。由于RadA蛋白在催化同源重组中的作用,它们在EPSPS重复的情况下特别有趣。RadA是否直接参与了来自不同杂草物种的EPSPS基因座重复,还是仅仅是巧合,仍有待进一步研究。
牛筋草中的端粒下区
全基因组比对显示,在草甘膦敏感(GS)和草甘膦抗性(GR)的牛筋草基因组中,许多组装染色体的末端附近都有来自EPSPS盒的高度保守的端粒下重复序列(图2)。有趣的是,GR基因组中每个区域的端粒下重复的平均拷贝数几乎是GS基因组的两倍(图2)。GR基因组的1号、3号、4号和7号染色体上端粒下重复的拷贝数特别高,这些区域可能是染色体之间或染色体内部减数分裂重组和端粒下区重排的位点(图2)【33】。先前的研究表明,在普通菜豆(Phaseolus vulgaris)中,类似的端粒下序列易于发生不等的链内同源重组【34】,通常导致整个抗病基因通路的大规模重复。
在EPSPS盒两侧的451 bp长端粒下重复单元与GR基因组中组成3号染色体的第二个contig的端粒下重复区最为相似(99.556%),这表明3号染色体可能是GR植物中EPSPS盒的所在位置。EPSPS基因在两组装基因组中都原生位于3号染色体。GS和GR基因组中4号染色体的端粒下序列也与EPSPS盒的端粒下重复区高度相似(98.884%)。在GR基因组的1号和7号染色体以及GS基因组的6号染色体上发现的端粒下重复与EPSPS盒的端粒下区的相似度为95.778%-96.882%,而在GS和GR基因组的8号和2号染色体上的相似度最低(86.301%-87.113%)。在两种基因组的4号和8号染色体上发现的端粒下重复是完全相同的(图5;表3)。其他研究者通过FISH细胞计量术表明,牛筋草中的EPSPS CNV存在于一条或可能两条染色体上【31】。考虑到EPSPS盒中的端粒下重复与3号和4号染色体上的端粒下区的序列相似性,通过非同源重组在这两个区域之间发生EPSPS盒易位似乎是可行的。然而,我们在GR基因组中组装了4号染色体从端粒到端粒的全长序列,完全穿过了端粒下区,但在该群体的4号染色体上没有发现EPSPS盒的证据(图2)。

下图展示了草甘膦抗性(R;金色)和草甘膦敏感(S;蓝色)牛筋草基因组中发现的端粒下区序列与EPSPS盒中端粒下序列(Cassette;绿色)的相关性。距离Cassette较远的染色体分支与EPSPS盒的相关性较低,而距离Cassette较近的染色体分支相关性较高。分支距离基于序列相似性计算。图中每条染色体上与EPSPS盒端粒下区序列相关性最高的序列被用作代表序列来构建此进化树。源数据以源数据文件的形式提供。
| Subtelomeric repeat label | Percent similarity (%) |
|---|---|
| Cassette | – |
| Chr3.2 R | 99.56 |
| Chr4R | 98.88 |
| Chr4S | 98.88 |
| Chr6S | 96.88 |
| Chr7.1R | 96.44 |
| Chr1R | 95.78 |
| Chr8R | 87.11 |
| Chr8S | 86.99 |
| Chr2R | 86.3 |
植物进化中的端粒下区
真核生物的端粒下区是适应性进化的热点区域,因为在减数分裂期间频繁且易出错的重组事件导致基因的快速变化。在普通菜豆(Phaseolus vulgaris)中,位于端粒下区的抗病基因的片段性重复(有时长达100kb)是通过非同源末端连接和频繁的染色体间重组促进的【34】。这些远端抗病基因的大规模重复允许同源基因分化成旁系同源基因,从而产生新的抗性,适应病原体的快速进化。类似于普通菜豆端粒下区新抗病基因的生成,拷贝数变异(CNV)增加了多个真核病原体(如Plasmodium falciparum、Trypanosoma brucei和Trypanosoma cruzi、Pneumocystis carinii)端粒下区中的毒力基因以及酵母中糖代谢基因的多样性【35】。类似地,与除草剂或其他非生物胁迫抗性相关的基因组区域(如EPSPS盒)易位到端粒下区,可能通过在重复基因座间迅速积累变异和增加转录本丰度,促进新的抗性发展。
考虑到端粒下区在其他禾本科植物中生成和选择性保持遗传变异的趋势,EPSPS盒在端粒下区中的重复,尤其是在牛筋草这样的禾本科植物中,可能并不罕见。在水稻(Oryza sativa)中,端粒下区被认为与高水平的转录、重组和新基因生成有关,因为这些区域包含大量高度相似的旁系同源基因,包括一些应激反应基因【36】。尽管某些水稻端粒下区区域具有明显的随机性,但高粱(Sorghum haplensis)、二穗短柄草(Brachypodium distachyon)以及若干稻属物种的其他端粒下区区域展示了相同基因组区域的重复和偏好性基因转换,表明这些端粒下区区域内的基因在进行连续协同进化和选择性保留【37】。这种精确选择性也在几种燕麦属物种(Avena)中得到体现,其中一个12个基因组成的端粒下区基因簇自燕麦族分化以来被保持下来,且基因顺序与生物合成途径一致【38】。鉴于端粒下区在其他单子叶植物生成与适应性进化相关遗传变异中的重要性以及我们的发现,我们推测牛筋草中的EPSPS在初始易位事件后重复出现在该物种的端粒下区。此外,我们推测,EPSPS的CNV可能通过端粒下区的染色体内和/或染色体间的不等交换传播,这由高频的端粒下区重组以及染色体末端之间高度相似的端粒下重复区所促进【10】,尤其是在端粒下区的重组频率较高的情况下【34,35,36】(图5;表3)。
总之,本研究的目标是获得全球重要杂草牛筋草的高质量基因组资源,并利用这些资源研究EPSPS基因复制和草甘膦抗性进化的基因组重排及其机制。通过组装GS和GR牛筋草的染色体级别基因组,重测序两个种群中的8个个体,针对每个种群的8个个体进行RNA测序,并手动整理EPSPS基因座附近的组装,我们发现GR牛筋草中的EPSPS基因已与基因组的另一部分融合,插入到一个或多个端粒下区,并平均重复了25次。我们推测,在初次的易位和融合之后,EPSPS的重复是通过染色体3及其他染色体端粒下区的不等交换进行的,得益于端粒下序列在染色体末端之间的高重组频率和相似性,未来的工作可以进一步研究这一过程。该研究将端粒下区重排添加到导致CNV生成和除草剂抗性的机制列表中,同时也增加了我们对端粒下区作为遗传变异生成器和适应性进化热点的重要性的有限了解。
材料与方法
牛筋草组织的生成
从中国广东省采集了一个草甘膦敏感(GS)和一个草甘膦抗性(GR)的牛筋草种群,这两个种群在之前的研究中已经被表征【4】。经过良好表型鉴定的GR个体(即已确认对草甘膦敏感或抗性)自花授粉,以提高纯合度和草甘膦敏感性或抗性表型的一致性。在净化之前,通过DNA定量PCR确认了GR种群中存在EPSPS拷贝数变异。
将净化后的GS和GR生物型的种子播种在培养皿中的湿滤纸上,并在28–30°C、光暗周期为12小时/12小时、相对湿度为70%的气候室中培养。两叶期幼苗移栽到28×54 cm的托盘中,每盘50株植物,托盘内填充盆栽土,并在温室中生长。分蘖期时,随机从GS和GR牛筋草种群中各选择约十个个体进行表征。每株植物的三个分蘖被分离并重新栽种(每盆一个分蘖,共60盆)。每株植物的一个分蘖用于草甘膦抗性和敏感性表型鉴定,另一个用于EPSPS拷贝数变异估计,最后一个用于后续测序。
对于草甘膦抗性和敏感性表型鉴定,使用商用草甘膦处理再生的分蘖(三天后分蘖克隆),GS个体施用41%的草甘膦异丙胺盐(400 g ai ha-1),GR个体施用1600 g ai ha-1。三周后评估GR(存活个体)和GS(死亡个体)的表型。在基因组学工作开始之前,再次对抗性植物进行EPSPS拷贝数变异评估,以确保CNV事件仍然存在。利用植物基因组DNA提取试剂盒(北京全程生物技术有限公司)从对应的抗性和敏感性植物的未处理分蘖中提取基因组DNA。使用已发布的引物对和方法进行定量PCR,将EPSPS拷贝数与作为内参的单拷贝乙酰乳酸合酶(ALS)基因进行比较。已确认的GS植物的未处理分蘖被用于基因组测序,该测序在上海欧易生物科技有限公司(上海,中国)进行。
草甘膦敏感基因组组装
最初的GS基因组是基于112.2 Gb(223倍覆盖)的PacBio Sequel II原始测序数据生成的,并使用Falcon【39】(版本0.5)进行组装。生成的初始基因组长518,672,752碱基对,包含239个contig,contig N50为18.8 Mb。使用Arrow【40】(版本1.0)算法和高覆盖的Illumina数据集进行了错误校正。将校正后的组装结果与NCBI【41】核苷酸数据库进行比对,以识别潜在的细菌或哺乳动物污染,未发现污染。在对组装结果进行打磨并移除污染后,最终组装结果长度为519,224,895碱基对,包含239个contig,contig N50为18.8 Mb。
为了进一步增加组装的连续性并修复可能存在的大规模错误,获得了Hi-C数据。Hi-C文库使用Dpn II限制酶(GATC切割位点)来产生足够的固定DNA的消化【42】。最终文库使用Illumina HiSeq进行测序,产生150 bp长的成对末端读段。使用Fastp(版本0.20;Chen et al.【34】)清理Hi-C成对末端读段中的接头和冗余PCR读段,并对清理后的读段进行分析。移除了连接序列以及包含≥5个N(非AGCT)碱基的读段。对窗口大小为4个碱基对的滑动窗口执行操作,移除平均碱基质量得分低于20的窗口。去除了长度小于75 bp或平均碱基质量得分低于15的过滤读段。最终清理后的Hi-C读段总产量为93.48 Gb,641,488,988个读段对,Q20%为97.41%,Q30%为92.69%,GC含量为44.28%。
Juicer【43】(版本1.6)使用bwa-mem(GitHub - lh3/bwa: Burrow-Wheeler Aligner for short-read alignment (see minimap2 for long-read alignment))和3D-DNA【44】的默认参数对PacBio组装的contig进行支架化。随后通过接触点邻近性对contig进行聚类,并生成Hi-C交互矩阵,该矩阵被导入juicebox【45】用于可视化和手动检查。生成的矩阵没有异常,并且contig能够聚类为9条染色体级别的支架和154条较小的支架。在每个contig之间添加了500个Ns的空隙,以便后续填充。支架化后的组装长度为519,302,895碱基对,N50为57.27 Mb。
最后,使用PBjelly【46】(版本1.0)通过将原始PacBio测序数据比对到Hi-C组装的基因组中来填补空隙。填充空隙后的组装现在为522,502,607碱基对,支架N50为57.37 Mb,contig N50为42.10 Mb。随后使用Arrow【40】进行自比对并进行另一次错误校正。最后,使用二代测序数据进行了两轮Pilon【47】(版本1.24)错误校正,最终组装结果为522,557,097碱基对,支架N50为57.37 Mb,contig N50为42.10 Mb,共62个空隙。使用BUSCO【28】(版本5.4.2)从胚胎植物数据库(embryophyta_odb10)的1375个单拷贝基因中评估基因组内容,发现1348个(97.8%)被标识为单拷贝或多拷贝。使用Extensive de novo Transposable Element Annotator (EDTA)【48】管道的输出结果计算了GS组装的长末端重复组装指数(LAI)得分为18.77(补充表2)。
草甘膦抗性基因组组装
最初的GR基因组是基于28 Gb(~53×)的PacBio HiFi【49】测序数据生成的,使用HiCanu【50】(版本2.1)进行组装,预计基因组大小为492 Mb。生成的初始基因组长541,164,105碱基对,包含2014个contig,contig N50为47.4 Mb。根据HiCanu的指示,为避免引入错误并保持99.99%的准确率,未进行组装后的错误校正。对胚胎植物数据库(embryophyta_odb10)的BUSCO评估表明组装的完成度为97.8%(补充表2)。根据EDTA管道的输出结果,计算出GR组装的LAI得分为16.85(补充表2)。随后使用Minimap2(版本2.24)将GR基因组的contig比对到GS基因组作为参考以识别染色体。虽然大多数contig是共线的,但相对于GS,在GR中检测到两个推测的倒位,一个位于5号染色体臂,另一个位于3号染色体最大contig的中部。为了验证这些倒位的准确性而非组装错误,从抗性基因组的PacBio读段中随机选择了200,000个读段并比对到GS和GR基因组的倒位连接点。跨越连接点的读段表示支持,而比对中断的读段表示组装错误(补充图1和补充图3)。来自GS的Hi-C数据用于确认GS基因组的当前方向(补充图2)。
基因组注释
使用国际杂草基因组联盟开发的自定义基因组注释管道对组装的草甘膦敏感(GS)和草甘膦抗性(GR)牛筋草基因组进行了注释。首先,使用RepeatModeler【51】(版本2.0.2)对重复区域进行注释,然后使用RepeatMasker(版本4.1.2;RepeatMasker Home Page)和bedtools【52】(版本2.30.0)对其进行掩蔽,以减少数据量,便于后续注释。然后使用Minimap2【53】(版本2.24)将IsoSeq读段映射到这两个重复掩蔽的基因组中,以确定转录位点。生成的序列比对图(SAM)文件使用SAMtools【54】(版本1.11)的view命令转换为二进制比对图(BAM)文件,随后使用cDNA Cupcake(版本28.0;GitHub - Magdoll/cDNA_Cupcake: Miscellaneous collection of Python and R scripts for processing Iso-Seq data)进行折叠。将基因组、折叠的cDNA Cupcake输出、来自RepeatModeler的重复库和来自近缘种Eleusine corocana的蛋白质FASTA文件(Phytozome基因组ID:560)输入MAKER【55】(版本3.01.04),以预测潜在基因模型的基因组坐标。编码32个氨基酸以下的蛋白质的基因在进一步注释中被删除,仅使用每个基因中最长的蛋白质和唯一的非编码区(UTR)进行功能注释。
功能注释首先通过AGAT(版本0.8.0;https://github.com/NBISweden/AGAT)和gffread【56】(版本0.12.7)选择每个基因中最长的异构体。使用MMseqs2【57】(版本4.1)对NCBI、UniRef 50【58】和InterPro【59】数据库中的序列相似性进行搜索,使用本地的InterProScan 5【60】(版本5.47-82.0)。蛋白质定位通过MultiLoc2【61】(版本1.0)预测。通过该管道,GS基因组中预测了27,487个基因(BUSCO:92.1%),GR基因组中预测了29,090个基因(BUSCO:92.2%)。
基因组重测序与转录组学
从上述GS和GR种群的8个个体的DNA中生成了Illumina 150 bp的成对末端序列。DNA通过对应的GS和GR植物的未处理分蘖叶片材料提取,使用植物基因组DNA试剂盒(TIANGEN,北京,中国)。DNA使用Illumina HiSeq X Ten测序平台(Illumina公司,圣地亚哥,加利福尼亚,美国)测序,平均覆盖度为30×。使用FASTQ清理Illumina读段,并使用HiSat2【62】(版本2.1.0)将其比对到草甘膦敏感基因组,使用成对末端读段的标准选项。使用CNVnator【63】(版本0.4.1)扫描比对中5 kb窗口的读深,以粗略识别显著偏离平均读深的基因组区域。使用bedtools【52】(版本2.30.0)进行交集操作,识别出在所有8个GR个体中放大但在GS个体中未放大的区域。最终发现了两个这样的区域,位于3号染色体包含EPSPS的区域标记为“Region-A”,另一个区域标记为“Region-B”以供进一步分析。
从用于基因组重测序的相同8个GS和8个GR个体的RNA中生成了Illumina 150 bp的成对末端序列。RNA通过mirVana miRNA提取试剂盒(Ambion)从叶鞘材料中提取。清理后的Illumina读段使用HiSat2比对到GS基因组预测的转录组,使用标准成对末端读段选项。比对结果使用SAMtools(版本1.11)转换为计数表。计数表导入R(版本4.2.0)中,并使用edgeR【64】(版本3.38.1)双侧似然比F检验计算差异基因表达。
EPSPS盒和端粒下区的研究
首先使用BLAST确定包含EPSPS、Region-A和Region-B的所有contig,以解析EPSPS盒模型。使用YASS【65】(版本1.16)对感兴趣的contig进行自比对,以可视化宏观结构,尤其是重复结构。根据其重复宏观结构手动将contig组装为假定模型。使用HiSat2(版本2.1.0)将基因组读段比对到它们上,以确认假定模型的contig连接。无法完全组装反向-正向EPSPS盒重复的两侧的大型端粒下重复区域。使用Minimap2(版本2.24)和BLAST找到类似于451 bp端粒下重复单元的序列位置及其相关性。
绘图生成
使用Circos【66】(版本0.69-9)可视化总结牛筋草的整体基因组(图1)。用于制作Circos轨迹的覆盖窗口使用bedtools(版本2.30.0;图1)生成。RIdeogram【67】(版本0.2.2)用于可视化在3号染色体上检测到的EPSPS重复和缺失,使用CNVnator(版本0.4.1;图2)进行检测。共线性图通过使用MiniMap2(版本2.24)比对两个基因组生成,并使用R中的RIdeogram可视化(版本4.2.2;图3)。EPSPS盒使用YASS可视化(图4A,B)。8个GS和8个GR牛筋草个体的差异表达使用R中的ggplot2【68】(版本3.4.0)进行可视化。端粒下区相关性树使用MUSCLE5(版本5.1.0)、RAXML-NG【69】(版本1.1.0)、ggtree【70】(版本3.6.2)、cowplot(版本1.1.1;CRAN: Package cowplot)和ggplot2在R中生成(图5)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









