







摘要
背景:在自然语言和视觉识别方面,大规模数据上预训练的多模态基础模型取得了成功。但由于医疗任务的细粒度性质和对领域知识的高需求,它们在医学领域的使用仍然受到限制。
方法:提出了一种称为知识增强自动诊断( Knowledge-enhanced Auto Diagnosis ,KAD)的新方法,该方法利用现有的医学领域知识,使用配对的胸部 X 射线和放射学报告来指导视觉语言预训练。
结果:
(1)在四个外部 X 射线数据集上评估了 KAD
①证明了零样本性能可以与完全监督模型相媲美
②优于三位放射科专家针对三种(out of five)病理学的统计平均值意义。
(2)此外,当可以用少样本注释时,在微调设置方面KAD 优于所有现有方法,证明了其在不同临床场景中的应用潜力。
1. 介绍
基础模型:例如 BERT [16]、GPT [7] 和 CLIP [44],在特征转移和泛化到广泛的下游任务方面表现出了巨大的希望(在自然语言处理或计算机视觉中)。但是,医学领域基础模型的发展很大程度上落后了。直接扩展现有方法 [63, 12] 来协调医学领域的视觉和文本模式,很难泛化超出训练中所见的疾病或放射学检查结果(radiology findings)。很大程度上是由于医疗任务中对细粒度识别的要求(即医学诊断的线索往往在于细微的、区域性的信号),以及许多复杂且专业的医学术语的抽象性(例如,渗透指的是肺部的白点)。因此,为了有效地对医疗应用中复杂且专业的概念进行建模,领域知识是必不可少的。
本文的目标是通过对配对图像和报告进行训练来构建胸部 X 光检查的基础模型 [29],称为知识增强自动诊断 (KAD)。如图 1 所示,与现有的方法不同,不是简单地将图像与原始文本报告对齐(align),本文研究了从给定报告中提取信息的各种方法,并利用完善的医学知识图谱来训练知识编码器( knowledge encoder)。

具体来说,KDA是一个两阶段框架:
(1)首先,学习知识图谱中的神经表示,其中,节点表示实体,边表示实体之间的关系,它们为实体的结构化、多步骤推理提供了支架;
(2)然后,用三种不同的方式从放射学报告中提取临床实体和关系,例如,通过启发式定义的规则(heuristically defined rules)、使用 RadGraph 或使用 ChatGPT,然后,利用预训练的知识编码器,在使用图像和放射学报告的条件下去指导视觉表示学习,有效地将领域知识注入视觉编码器。
在架构上,为了能够对任意疾病或放射学结果进行灵活的零样本评估,我们利用基于查询的transformer架构,称为疾病查询网络(Disease Query Network,DQN),它可以将疾病名称作为“查询”,迭代地处理视觉特征得到模型预测,注意力图(attention map)为临床决策提供可靠的视觉证据。
四个外部 X 射线(external X-ray)数据集:
①PadChest [8]
②ChestXray14 [53]
③CheXpert [26]
④ChestX-Det10 [35].
KAD 在自动诊断(auto-diagnosis)训练过程中,未见的病理方面表现出优异的性能;对于 PadChest 上的 193 种病理,其零样本性能显着高于现有最先进的医学视觉语言模型,甚至可以媲美全监督的方法。据本文研究员所知,这是第一个使用 X 射线图像和报告进行预训练的模型,并且在 CheXpert 上表现出与放射科专家的平均水平相当或更好的性能。此外,当额外的手工注释有的情况下,本文的模型还可以在(与现有自监督学习方法相同的)协议中进行微调,进一步提升性能,展示其卓越的可迁移性。本文相信这项工作为开发**(放射成像中的)AI辅助诊断基础模型的领域知识的注入**( domain knowledge injection)提供了一个有前景的想法。
2. 相关工作
2.1. 视觉语言的预训练模型
视觉语言预训练模型(Vision-Language Pre-training ,VLP)在视觉方面已经获得巨大的成功。 一般VLP模型有两种典型的结构,即单流方法[32,11]和双流方法[3,30,28]。在医学领域,已经开始了几种方法[61,9,23,5,55]研究。 ConVIRT [61]首先提出使用对比学习作为医学中的代理任务( proxy task)。然后,LoVT [9] 和 GLoRIA [23] 专注于提高局部对齐( local alignment)性能。 BioViL [5]注意到医学报告中的语言模式与其他自然文本不同,并重新设计了用于医学VLP的语言模型。MedKLIP [55]提出利用医学特定(medical-specific)知识、疾病描述来增强表示学习(representation learning)。然而,这些研究在知识整合和开放集泛化(open-set generalization)方面存在局限性。
本文的工作明确地将完善的医学知识图谱利用到自监督训练过程中,以解决上述限制。
2.2. 医学的命名实体识别模型
医学的命名实体识别模型(Medical Named-Entity-Recognition Models)。各种自然语言处理(NLP)方法被提出,以达到从放射学报告中提取有用的信息[43,26,39,47]。最近,一些分析工具 [4, 2] 被开发出来,用于从生物医学文本中提取关键的临床概念及其属性。相关推进性工作提出了 [27, 56] 进一步提取不同实体之间的关系,从而能够以结构格式(structural format)保留大部分有用信息。这一进展给本文研究员很大的启发,也为VLP提供了新的视角。然而,如何利用这些命名实体识别(NER)模型在 VLP 领域尚未得到充分讨论。
2.3. 医学知识增强模型
医学知识增强模型(Medical Knowledge Enhanced Models):在利用外部医学知识来增强深度学习模型 [57, 54]的方法,前人进行了一些探索。这些方法可以分为两种类型:基于模型的方法和基于输入的方法。在基于模型的方法中,一种想法是通过模仿放射学实践(radiological practice)来设计模型[31,20,52,24]或根据诊断模式改变模型结构[40,19,13]。而在基于输入的方法中,知识被视为外部输入来计算特征 [59, 58, 48] 或指导最终损失 [10, 25]。经常采用多任务学习和注意力机制[33,34,38]来实现医学知识组合。与之前的方法相比,本文通过显式学习医学知识图谱的神经表示(neural representation)将专家知识(expert knowledge)注入文本嵌入空间(the text embedding space ),为视觉方面的表示学习(representation learning)提供知识指导(knowledge guidance)。
3. 方法
3.1. 算法概述
本文提出的想法的核心是利用医学先验知识来训练基础模型,在本文中,明确利用了完善的医学知识图谱,即统一医学语言系统(Unified Medical Language System,UMLS)和各种信息提取方法,基于启发式规则(heuristic rules)、RadGraph 或 ChatGPT。本文分两个阶段训练模型,首先,训练知识编码器来学习医学知识库的神经表示;其次,我们从放射学报告中提取临床实体和关系,并使用预先训练的知识编码器在胸部 X 射线图像-文本对上指导视觉表示学习。
3.2. 问题场景
假设一个训练集有
N
N
N个样本,例如:
D
t
r
a
i
n
=
D_{train}=
Dtrain={
(
x
1
,
t
1
)
,
⋅
⋅
⋅
,
(
x
n
,
t
n
)
(x_1,t_1),···,(x_n,t_n)
(x1,t1),⋅⋅⋅,(xn,tn)},其中
x
i
x_i
xi,
t
i
t_i
ti分别代表X射线图片和它相应的医学报告,本文的目标是训练一个能够诊断任何病理是否存在的视觉语言模型。具体来说,在推理时,我们可以自由地要求系统识别患者患某种疾病的可能性:

其中,
x
i
∈
R
H
×
W
×
3
x_i∈R^{H×W×3}
xi∈RH×W×3表示测试集的一个图像样本,
H
,
W
H,W
H,W分别代表长和宽,
s
^
i
∈
[
0
,
1
]
\widehat{s}_i∈[0,1]
s
i∈[0,1]表示推理病人患某种疾病的可能性。
3.3. 知识编码器
这个部分,本文提供训练知识编码器( Φ k o n w l e d g e \Phi_{konwledge} Φkonwledge)的细节,利用专家的知识对纹理嵌入空间(textural embedding space)中的医疗实体之间的关系进行隐式建模(implicitly model)。具体来说,本文通过从统一医学语言系统 (UMLS) [4] 中采样正例和负例的方法,来使用对比学习微调预训练的BERT。
(1)标识:令
D
U
M
L
S
=
D_{UMLS}=
DUMLS={
(
n
,
c
,
d
)
i
(n,c,d)_i
(n,c,d)i}
i
=
1
∣
∣
D
∣
∣
_{i=1}^{||D||}
i=1∣∣D∣∣代表UMLS的概念字典(concept dictionary),每一个概念(
n
i
n_i
ni)有一个概念唯一标识符(Concept Unique Identifier)(CUI,
c
i
c_i
ci)其有相应的定义(
d
i
d_i
di)和类型唯一标识符(Type Unique Identifier ,TUI),如图1所示。“肺浸润”的概念被定义为发现了肺实质( lung parenchyma)中存在炎症或肿瘤细胞浸润”,相应的 CUI 为 C0235896。对于UMLS知识图谱来说,顶点( vertices)就是概念(
D
U
M
L
S
D_{UMLS}
DUMLS),每条边可以表示为一个三元组,即
(
n
i
,
r
,
n
j
)
(n_i , r, n_j )
(ni,r,nj),其中
n
i
n_i
ni指头概念,
n
j
n_j
nj指尾概念,
r
r
r表示头概念到尾概念的关系。
(2)训练:在这里,本文通过最大化从知识图谱生成的正概念-定义对和概念-关系-概念三元组之间的相似性来训练知识编码器,使得指向相同CUI的语言描述具有相似的表示。
对于一个特定的
C
U
I
c
i
{CUI}_{c_i}
CUIci ,对应的语言描述可以有三种格式表达:概念
n
i
n_i
ni 、定义
d
i
d_i
di 以及其他具有正确关系(correct relationship)的概念 {
n
j
+
r
n_j + r
nj+r} ,
r
r
r 是头概念
n
j
n_j
nj 指向尾概念
n
i
n_i
ni之间的关系。注意:也许会有多个头概念指向相同的尾概念的情况,作者随机地选择其中一个去训练。给定随机 N 个采样的
C
U
I
s
CUIs
CUIs,可以计算相应语言描述的文本嵌入,比如,概念
n
i
∈
R
N
×
d
n_i∈R^{N×d}
ni∈RN×d,定义
d
i
∈
R
N
×
d
d_i∈R^{N×d}
di∈RN×d,具有关系的概念{
n
j
+
r
n_j+r
nj+r}
∈
R
N
×
d
∈R^{N×d}
∈RN×d。每对具有相同 CUI 的文本嵌入可以被视为正对,而具有不同 CUI 的文本嵌入可以被视为负对。
在训练期间,对于每个
C
U
I
CUI
CUI,相应地随机对两个文本嵌入进行采样,每个小批量(mini-batch)可以表示为{
(
z
i
,
c
i
)
(z_i,c_i)
(zi,ci)}
i
=
1
2
n
^{2n}_{i=1}
i=12n,
c
i
c_i
ci表示
z
i
z_i
zi指向的
C
U
I
CUI
CUI。这里,
z
z
z表示文本嵌入通过知识编码器后的输出。因此,可以通过对比学习来训练模型,方法是最小化指向同一 CUI 的
z
i
z_i
zi 之间的距离:
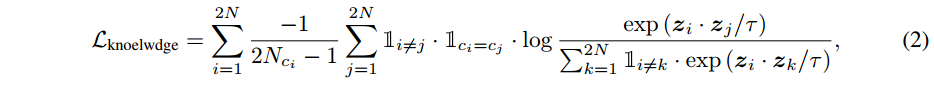
其中,
N
c
i
N_{c_i}
Nci表示该小批量中带有标签
c
i
c_i
ci的
z
i
z_i
zi的数量,
τ
∈
R
+
τ∈R^+
τ∈R+是一个标量温度参数(scalar temperature parameter)。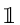 是指示函数(the indicator function)。
是指示函数(the indicator function)。
3.4. 实体提取( Entity extraction)
在本节中,介绍用于处理文本报告的实体提取模块,将其提取到医学实体,例如解剖学或观察,及其存在信息中。解剖学是指放射学报告中出现的解剖身体部位,例如“肺”。观察是指与视觉特征、生理过程或诊断疾病分类相关的词,例如“积液”,对于每次观察,其存在的不确定性水平将被指定为存在或不存在。对于每一个放射学文本都有多个句子,它们将被转换成一个含有实体和类别(category)的序列,即
t
=
t=
t={
e
1
1
,
s
1
1
,
[
S
E
P
]
,
.
.
.
e
i
k
,
s
i
k
,
[
S
E
P
]
.
.
.
e_1^1,s_1^1,[SEP],...e_i^k,s_i^k,[SEP]...
e11,s11,[SEP],...eik,sik,[SEP]...},其中
e
i
k
e_i^k
eik是从第
i
i
i个句子中提取的第
k
k
k个实体,
s
i
k
s_i^k
sik是
e
i
k
e_i^k
eik的类别。
[
S
E
P
]
[SEP]
[SEP]令牌(token)分隔实体。从报告中提取出所有实体后,我们从整个报告语料库(reports corpus)中选择前 Q 个最常出现的观察实体,表示为实体集
Q
=
Q =
Q= {
q
1
,
q
2
,
.
.
.
,
q
Q
q_1, q_2, ..., q_Q
q1,q2,...,qQ},并得到一个的标签,该标签能够从不确定水平中表明实体的存在。对于报告中未提及的实体,我们默认将其标签设置为“不存在”。为了这个目标,我们做了三个尝试。
(1)采用统一医学语言系统 (UMLS) 的启发式规则。具体来说,对于放射学报告中的每个句子,能够使用 Python中的spacy包提取实体序列(实体、概念、
C
U
I
CUI
CUI、
T
U
I
TUI
TUI)。补充图 12 中提供了伪代码。 为了确定实体是否存在,首先根据
T
U
I
TUI
TUI 过滤每个句子的实体列表(the entity list),仅保留在(T033:Finding 和 T047:Disease or Syndrome)中具有
T
U
I
TUI
TUI 的实体。接下来,我们将这些实体与我们的实体集进行匹配,“正常”除外。此外,采用了一个简单的启发式规则:如果句子包含“不”、“无”或“正常”等词,则标签设置为不存在;否则,标签设置为 1 表示存在。对于报告中未提及的实体,我们分配了“不存在”标签。如果所有实体都不存在,我们将**“正常”标签设置为存在**。
(2)利用现成的 RadGraph 来识别特定的放射学实体(radiology-specific entities),并根据临床文本断言它们的存在和解剖关系。 RadGraph 接受了来自 MIMIC-CXR 数据集的 500 份放射学报告的训练,这些报告由委员会认证的放射科医生注释。使用RadGraph,每个放射学文本都被直接转换为实体和类别序列。每个实体
e
i
k
e_i^k
eik将被分为以下类别之一,定义为
s
i
k
s^k_i
sik :解剖学(ANAT)、观察:绝对存在(Definitely Present,OBS-DP)、观察:不确定(Uncertain,OBS-U)和观察:绝对不存在(Definitely Absent ,OBS-DA) )。对于报告中未提及的实体,我们默认将其标签设置为“绝对不存在”。
(3)在ChatGPT上进行了实验,ChatGPT是一个大型的语言模型,在自然语言处理方面表现出了显着的成果。实验将放射学报告作为内容输入到 ChatGPT 中,并使用以下提示:
对于给定的**胸部 X 光报告**,确定患者是否**有以下任何发现**:finding_list = [[pleural effusion(胸腔积液)、opacity(不透明)、pneumothorax(气胸)、edema(水肿)、atelectasis(肺不张)、tube(管状)、consolidation(实变)、enlarged cardiomediastinum(纵隔扩大)、tip(尖端)、pneumonia(肺炎)、line(线)、cardiomegaly(心脏肥大)、 fracture(骨折)、calcification(钙化)、medical device(医疗器械)、engorgement(肿胀)、nodule(结节)、wire(电线)、pacemaker(起搏器)、 pleural thicken(胸膜增厚)、marking(标记)、scar(疤痕)、hyperinflate(过度膨胀)、blunt(钝性)、collapse(塌陷)、emphysema(肺气肿)、 aerate(通气)、mass(肿块)、infiltration(浸润)、obscure(模糊)、deformity(畸形)、hernia(疝气)、drainage(引流)、drainage(膨胀)、shift(移位)、lesion(病变)、hardware(硬件)、dilation(扩张)、aspiration(吸气)]。**输出**应使用以下模板:label_list = [i if finding_list exists for finding in finding_list]。如果**没有发现**,则输出 label_list = [ ]
然后处理输出 的label_list 以获取实体的存在。
3.5. 知识引导的视觉表征学习
本节描述知识引导的视觉表示学习(Knowledge-guided visual representation learning)的细节。首先,介绍了模型架构的各个组件,包括图像编码器(
Φ
i
m
a
g
e
Φ_{image}
Φimage)、知识编码器(
Φ
k
n
o
w
l
e
d
g
e
\Phi_{knowledge}
Φknowledge)、疾病查询网络(
Φ
d
q
n
Φ_{dqn}
Φdqn)。最后,描述训练过程。
图像编码器:给定 X 射线图像扫描
x
i
∈
R
H
×
W
×
3
x_i ∈ R^{H×W×3}
xi∈RH×W×3 ,用视觉主干(visual backbone)计算特征:
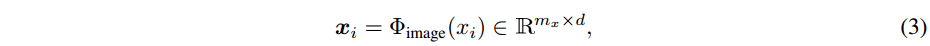
其中
d
d
d指的是特征维度,
m
x
=
h
×
w
m_x=h×w
mx=h×w,其中
h
h
h、
w
w
w表示输出特征图的尺寸(size)。在本文的例子中,如果采用标准 ResNet-50 [22] 作为视觉主干,我们将采用第 4 个残差块的输出。如果使用标准 ViT-16作为视觉主干,只需使用transformer编码器输出的特征。
知识编码器:给定一个预处理的文本报告
t
i
t_i
ti ,使用预先训练的知识编码器计算特征:
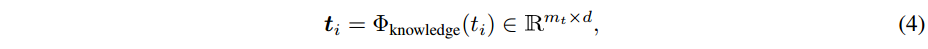
其中,
d
d
d表示特征维度,
m
t
m_t
mt表示token数量。
疾病查询网络:给定预定义的实体集
Q
Q
Q,我们使用预训练的知识编码器计算一组查询向量,
Q
=
Q=
Q={
q
1
,
q
2
,
.
.
.
,
q
Q
\pmb{q_1 , q_2 , ..., q_Q}
q1,q2,...,qQ},其中
q
i
=
Φ
k
n
o
w
l
e
d
g
e
(
q
i
)
\pmb q_i = Φ_{knowledge}(q_i)
qi=Φknowledge(qi)。在训练期间,随机选择编码的视觉特征
x
i
x_i
xi或文本特征
t
i
t_i
ti作为疾病查询网络(
Φ
d
q
n
Φ_{dqn}
Φdqn)的键和值,对应于图1.c中的“Random Select”模块。理想情况下,我们希望视觉和文本嵌入空间可以交换使用。
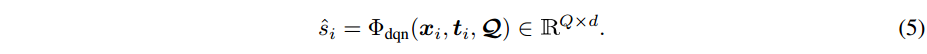
注意在推理过程中,我们仅使用视觉特征作为
D
Q
N
DQN
DQN 的输入。
D
Q
N
DQN
DQN 的输出进一步馈送到 MLP 中,以推断查询实体(query entity)是否存在。
训练:我们从训练数据中随机采样 N 个输入对的小批量,并优化对比损失:

L
c
o
n
t
r
a
s
t
L_{contrast}
Lcontrast 分别表示第
i
\pmb i
i 对的图像到文本(image-to-text)和文本到图像( text-to-image)的对比损失,其中
x
^
i
\widehat{x}_i
x
i 表示视觉特征
x
i
x_i
xi 上的平均池化,
t
^
i
\widehat{t}_i
t
i 表示文本特征
t
i
t_i
ti 上的平均池化,
⟨
⋅
,
⋅
⟩
⟨·,·⟩
⟨⋅,⋅⟩表示余弦相似度,
τ
τ
τ表示温度参数。
如前面所述,对于每个样本,我们可以通过实体提取模块获得实体集$ Q$的存在标签。然后对是否存在进行预测,我们使用带有存在标签的二元交叉熵,表示为
L
d
q
n
L_{dqn}
Ldqn。最后,对于每个小批量,将
L
c
o
n
t
r
a
s
t
L_{contrast}
Lcontrast 和
L
d
q
n
L_{dqn}
Ldqn 简单地相加作为总损失。
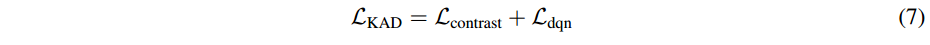
4. 实验
4.1. 特定领域的知识(Domain-specific Knowledge)
为了将医学领域知识纳入论文提出的知识增强自动诊断系统的训练过程中,实验利用完善的医学知识图谱(UMLS)进行预训练,并研究从报告中提取医疗实体的各种方法。
UMLS 知识图谱:论文中利用统一医学语言系统 (UMLS) [4, 17] 作为训练我们提出的架构的知识库。具体来说,UMLS包含从不同词典资源集成的医学概念(实体),每个实体都有一个具有相应定义的概念唯一标识符(CUI)和多个同义名称,并且被分配了一种或偶尔多种的语义类型。 UMLS还以三元组的形式提供医疗实体之间的关系信息,通常表示为(头实体,关系,尾实体),例如(adenoviral pneumonia, has finding site, lungs pair),如图1.a所示。
实体提取:本文探索了三种不同的方法,即启发式规则、RadGraph 或 ChatGPT,来预处理给定的 X 射线报告,将它们从原始文本转换为医学实体及其存在,例如句子“There is no consolidation, effusion, or pneumothorax(没有实变、积液或气胸).”将转换为 {consolidation, absent, [SEP], effusion, absent, [SEP], pneumothorax, absent}{实变,不存在,[SEP],积液,不存在,[SEP],气胸,不存在}。提取过程将在下面部分详细介绍。
4.2. 数据集
4.2.1. 预训练的数据集
实验中,研究员在 MIMIC-CXR [29] 上进行模型预训练,MIMIC-CXR是带有放射学文本报告的胸部 X 光照片的公开数据集。 MIMIC-CXR 数据集包含 377,110 张图像,对应有 65,379 名患者的 227,835 项放射学研究。每项放射学研究都附带一份自由文本放射学报告和相应的胸部 X 射线图像(正面或侧面视图)。放射学报告是放射科医生对其发现的总结,由多个部分组成:examination(检查)、examination(适应症)、 impression (印象)、findings(发现)、technique(技术)和comparison(比较)。实际上,我们只在报告中保留impressions和findings部分。
4.2.2. 用于下游评估的数据集
为了评估模型,研究员对零样本迁移和模型微调进行了实验。数据集的详细信息和实施细节如下所述。
PadChest:PadChest 有 160,868 张胸部 X 光图像,有 174 种放射学结果标的记、19 种鉴别诊断(differential diagnoses),只有 27% 的标签(总共 39,053 个例子)来自(经过委员会认证的)放射科医生,其余的都是通过使用带有注意力机制的循环神经网络对放射学报告训练出来的。出于评估目的,我们仅对(由委员会认证的)放射科医生注释的样本进行测试,并报告零样本迁移的结果。
ChestXray14 [53]: NIH ChestXray14 有来自 30,805 名独特患者的 112,120 张胸部 X 射线图像以及疾病标签。通过使用自然语言处理工具挖掘相关的放射学报告来获取疾病标签。总共有 14 个疾病标签:Atelectasis, Cardiomegaly, Effusion, Infiltration, Mass, Nodule, Pneumonia, Pneumothorax, Consolidation, Edema, Emphysema, Fibrosis, Pleural Thickening and Hernia.(肺不张、心脏扩大、积液、浸润、肿块、结节、肺炎、气胸、实变、水肿、肺气肿、纤维化、胸膜增厚和疝气)。在本文中,所有模型的任务是为数据集中的每个 X 射线图像的这 14 个疾病标签中的每一个标签预测二进制标签,类似于多标签分类问题。我们严格遵循原始ChestXray14 版本中的官方患者数据划分,并使用训练集中 10% 受试者的图像来形成验证集。
CheXpert[26]:CheXpert 拥有从 65,240 名患者收集的 224,316 张胸部 X 射线图像。官方验证集包含 200 项胸部放射学研究,由 3 名委员会认证的放射科医生手动注释,官方测试集包含 500 项胸部放射学研究,由 5 名委员会认证的放射科医生一起注释[45]。我们使用验证数据集来选择预测阈值(thresholds of predictions)。我们遵循原始论文,重点评估官方测试集(竞赛任务)上的 5 个观察结果:Cardiomegaly, Consolidation, Edema and Pleural Effusion(肺不张、心脏肥大、实变、水肿和胸腔积液)。
ChestX-Det10 [35]:ChestX-Det10 是 NIH ChestXray14 的子集,由 3543 张胸部 X 射线图像组成,并由 3 位委员会认证的放射科医生提供 10 种疾病/异常的框级注释,包括Atelectasis, Calcification, Consolidation, Effusion, Emphysema, Fibrosis, Fracture, Mass, Nodule and Pneumothorax(肺不张、钙化、实变、积液、肺气肿、纤维化、骨折、肿块、结节和气胸)。在本文中,我们遵循官方数据划分并报告测试集上的零样本真实结果(the zero-shot grounding results)。
4.3. 基线(Baselines)
一般来说,现有的最先进的模型可以根据预训练阶段涉及的方式分为两类:医学图像-文本预训练方法,它可以实现零样本迁移和微调,医学图像预训练方法,仅支持微调评估(fine-tuning evaluation)。请注意,所有上述基线都是使用与本文 KAD 相同的主干架构来实现的,即 ResNet-50 [22] 架构作为基本图像编码器模块。这样的实施决策排除了网络架构对最终性能的影响,并有益于实验比较的公平性。
4.3.1. 医学图-文预训练方法
在本节中,介绍了比较SOTA的医学图像-文本预训练方法,即ConVIRT [61]、GLoRIA [23]、BioViL [5]和CheXzero [49]。由于 ConVIRT 和 GLoRIA 是在内部数据集(in-house dataset)上预先训练的,因此我们在 MIMIC-CXR [29] 数据集上重新训练它们的模型以进行公平比较。对于 BioViL 和 CheXzero,使用作者正式发布的模型。
ConVIRT 通过双向对比学习( bidirectional contrastive learning),使用配对的医学图像和报告联合训练视觉和文本编码器。
GLoRIA 通过全局和区域对比学习对医学图像和报告之间的交互进行建模。
BioVIL 利用预先训练的放射学专用(radiology-specific)文本编码器,使用配对的图像-文本放射学数据进行对比学习。
CheXzero 在 X 射线上微调预训练 CLIP 模型,并使用图像-文本对进行对比学习报告。
MedKLIP 利用医学特定的知识描述来使用配对的图像文本数据来增强视觉语言预训练。
4.3.2. 医学图像预训练方法
在本节中,介绍了比较的医学图像预训练方法,即 Model Genesis 、Comparing to Learn (C2L) 和 ImageNet Pre-training 。对于Model Genesis和C2L,使用他们的官方代码在 MIMIC-CXR [29] 数据集上重新训练他们的模型,以进行公平比较。
Model Genesis指的是自监督视觉表示学习方法,考虑从人工失真(artificial distortion)中恢复原始图像,包括局部改组(local shuffling)、非线性变换(non-linear transformation)、内画和外画(in- and out-painting)。
Comparing to Learn (C2L)是指自监督的视觉表示学习方法,它通过图像和特征级别的混合生成正负对以进行对比学习。
ImageNet Pre-training是指在大规模自然图像数据集上通过监督学习进行预训练的代表性方法。
4.4. 实施细节
数据预处理。在视觉语言预训练阶段,我们将每个胸部 X 射线图像的大小调整为 224 × 224,并使用从整个训练数据集计算出的样本均值和标准差对其进行归一化。随机调整裁剪大小、随机水平翻转、随机旋转(–10 到 10 度)和随机灰度(亮度、清晰度和对比度)作为数据增强的手段。对于放射学报告,我们首先应用命名实体识别(entity recognition)和链接工具(linking tool), ScispaCy [42] 来预处理文本,即从报告中提取实体并将其放入 UMLS 知识库中以进行实体消歧(entity disambiguation)。然后,我们使用 RadGraph 获取每个具有不确定性级别的实体对应的语义类型。将具有相应语义类型和不确定性级别的实体连接(concatenate)为输入,例如, {pleural effusion, observation definitely present, [SEP], lung, anatomy, [SEP],…}({胸腔积液,观察肯定存在,[SEP],肺,解剖学,[SEP],...}),最大序列长度为 256。在微调阶段,我们应用相同的一组策略进行预处理,就像对所有四个目标域数据集进行预训练一样。
模型预训练:总体框架通常遵循两阶段训练流程。
对于 阶段1,我们从英文版 PubMedBERT 初始化知识编码器,并将其微调为 100K 训练step。在每个小批量中,使用 64 个概念-定义对和 64 个概念关系-概念三元组进行训练。因为定义可能很长,设置最大序列长度为 256。使用 AdamW [36] 作为优化器,其中
l
r
=
1
×
1
0
−
4
lr = 1 × 10^{−4}
lr=1×10−4 和
l
r
w
a
r
m
u
p
=
1
×
1
0
−
5
lr_{warm up} = 1 × 10^{−5}
lrwarmup=1×10−5。
对于Stage2,图像编码器是ResNet50的前四层,DQN由一系列标准Transformer解码器组成[50]。使用 AdamW 优化器,其中
l
r
=
1
×
1
0
−
4
lr = 1 × 10^{−4}
lr=1×10−4 和
l
r
w
a
r
m
u
p
=
1
×
1
0
−
5
lr_{warm up} = 1 × 10^{−5}
lrwarmup=1×10−5 。在批量大小为 64 的 A100 上训练 50 个 epoch。前 5 个epoch用于热身(warming up)。
零样本迁移:为了评估模型在多标签分类任务上的零样本性能,DQN 将疾病名称列表(disease name list)作为查询输入(query input),以图像特征作为键和值(key and value),并输出(所考虑的胸部 X 射线图像中)存在疾病的可能性。疾病和视觉特征之间的平均交叉注意力用于grounding。对于其他的医学图像-文本预训练基线,使用 BioVIL 中定义的提示,例如表示是否存在肺炎:“Findings suggesting pneumonia” and “No evidence of pneumonia”(“结果提示肺炎”和“没有肺炎证据”)。
模型微调:在此阶段,使用
l
r
=
1
×
1
0
−
4
lr = 1 × 10^{−4}
lr=1×10−4 的AdamW 优化器对所有数据集的进行微调。该模型使用与预训练阶段相同的学习率(learning rate)和衰减策略(decay strategy)进行训练,使用 64 的批量大小进行训练。
4.5. 评估详情
统计分析:在本实验的评估中,AUC代表“ROC曲线下的面积”,MCC代表“马修斯相关系数”,F1代表“F1分数”,ACC代表“准确度”。
我们直接使用模型的预测来收集 AUC 结果,而为了获得 MCC,首先对测试集进行推理,以获得每个胸部 X 射线图像上不同类别的概率值(the probability values)。然后将概率转换为正/负预测,其阈值是通过在验证数据集上优化的 MCC 找到的。然后,使用这些预测计算基于条件的 MCC 分数。类似地计算 F1 分数和 ACC,但使用与计算 MCC 相同的阈值。对于零样本对齐(zero-shot grounding),我们使用 Pointing Game 进行评估。具体来说,我们提取输出热图中响应最大的区域,如果该区域命中真实掩模,则被认为是正预测,否则是负预测。最后,准确度可以计算为指向游戏得分(the pointing game score)。
置信区间:我们使用非参数引导程序(the non-parametric bootstrap)来生成置信区间:大小为 n(等于原始数据集大小)的随机样本从原始数据集中重复采样 1,000 次并进行替换。然后,使用每个 bootstrap 样本估计 AUC、MCC、F1 和 ACC 指标。然后使用通过在验证数据集上优化 MCC 找到的阈值将预测概率转换为正/负预测。使用
100
×
(
α
/
2
)
100 × (α/2)
100×(α/2) 和
100
×
(
1
−
α
/
2
)
100 × (1 − α/2)
100×(1−α/2) 百分位数之间的间隔,根据重新采样的估计值的相对频率分布得出置信区间;我们选择
α
=
0.05
α = 0.05
α=0.05。
5. 结果
论文提出的知识增强自动诊断(KAD)的目标是通过利用领域知识(例如,在预定义的知识图谱中(统一医学语言系统,UMLS))来改进视觉语言预训练并促进胸部 X 射线图像的自动诊断[4],或现成的命名实体识别工具箱(off-the-shelf named entity recognition toolbox)(RadGraph)[27]。在本节中,所有基线都在 MIMIC-CXR [29] 数据集上进行预训练,并直接在四个成熟(well-established)的多中心数据集上进行评估,即零样本推理,包括 PadChest [8]、NIH ChestX-ray [53 ]、CheXpert [26] 和 ChestX-Det10 [35]。在所有情况下,模型都会预测输入图像中是否存在查询的疾病( queried
disease)。
请注意:论文研究的核心是开发一个预训练程序来整合医学领域知识,例如 UMLS、RadGraph,这种设计自然为 KAD 提供了比现有自我监督方法更多的信息。然而,从实践的角度来看,KAD 训练仅利用现成的工具,因此与自监督学习方法一样可以扩展到大型数据集,同时在识别训练时未遇到的疾病和处理长尾识别问题方面表现出明显更优越的性能。该论文进行广泛的消融实验,以分析某些模型组件的贡献以及图像分辨率和视觉主干的影响。
5.1. PadChest
在 PadChest 数据集中的诊断任务上评估 KAD,其中图像标记有 174 种不同的放射学结果和 19 种鉴别诊断。 PadChest 数据集的根本挑战在于长尾类别分布,如补充图 7 所示,其中只有 21 个类别拥有超过 1000 个样本,并且在预训练期间仅看到 16 个类别。在这里,我们将模型训练阶段疾病查询网络(DQN)看到的疾病表示为已见疾病,将其他疾病表示为未见疾病。















 2685
2685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











