







大家读完觉得有意义记得关注和点赞!!!
生成式建模(generative modeling)近几年发展神速, 网上也涌现出了大批令人惊叹的纯 AI 生成图片。 本文试图总结文生图(text-to-image)领域近几年的发展, 尤其是各种扩散模型(diffusion models)—— 它们已经是业界的标杆架构。
1 OpenAI DALL·E:起于文本,潜入图像,2021.01
1.1 GPT-3 (2020):基于 transformer 架构的多模态大语言模型
2020 年,OpenAI 发布了 GPT-3 模型 [1],这是一个基于 Transformer 架构的多模态大语言模型,能够完成机器翻译、文本生成、语义分析等任务, 也迅速被视为最先进的语言建模方案(language modeling solutions)。
1.2 DALL·E (2021.01):transformer 架构扩展到计算机视觉领域
DALL·E [7] 可以看作是将 Transformer(语言领域)的能力自然扩展到计算机视觉领域。
如何根据提示文本生成图片?DALL·E 提出了一种两阶段算法:
-
训练一个离散 VAE (Variational AutoEncoder) 模型,将图像(images)压缩成 image tokens。
VAE 是一种神经网络架构,属于 probabilistic graphical models and variational Bayesian methods 家族。
-
将编码之后的文本片段(encoded text snippet)与 image tokens 拼在一起(
concatenate), 训练一个自回归 Transformer,学习文本和图像之间的联合分布。
最终是在从网上获取的 250 million 个文本-图像对(text-image pairs)上进行训练的。
1.3 量化“文本-图像”匹配程度:CLIP 模型
训练得到模型之后,就能通过推理生成图像。但如何评估生成图像的好坏呢?
OpenAI 提出了一种名为 CLIP 的 image and text linking 方案 [9], 它能量化文本片段(text snippet)与其图像表示(image representation)的匹配程度。
抛开所有技术细节,训练这类模型的思路很简单:
- 将文本片段进行编码,得到 TiTi;
- 将图像进行编码,得到 IiIi;
对 400 million 个 (image, text) 进行这样的操作,
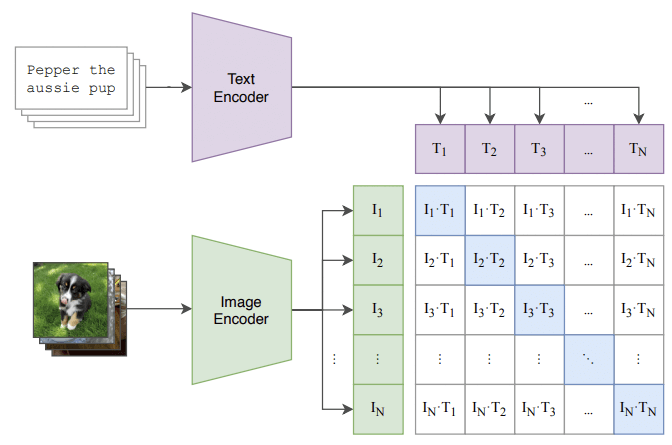
F.g CLIP contrastive pre-training 工作原理 [9]. (文本大意:澳大利亚小狗)。
基于这种映射方式,就能够评估生成的图像符合文本输入的程度。
1.4 小结
DALL·E 在 AI 和其他领域都引发了广泛的关注和讨论。 不过热度还没持续太久,风头就被另一个方向抢走了。
2 Diffusion:高斯去噪,扩散称王,2021.12
Sohl-Dickstein 等提出了一种图像生成的新思想 —— 扩散模型(diffusion models) [2]。 套用 AI 领域的熟悉句式,就是
All you need is
diffusion.
2.1 几种图像生成模型:GAN/VAE/Flow-based/Diffusion
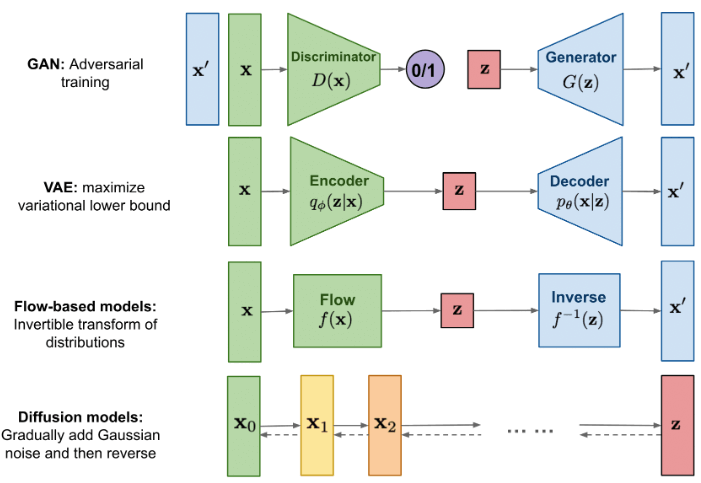
Fig. 几种生成式模型(generative models)[13]
Diffusion 模型受到了非平衡热力学(non-equilibrium thermodynamics)的启发,但其背后是一些有趣的数学概念。 它仍然有大家已经熟悉的 encoder-decoder 结构,但底层思想与传统的 VAE(variational autoencoders)已经不同。
要理解这个模型,需要从原理和数学上描述正向和反向扩散过程。
公式看不懂可忽略,仅靠本文这点篇幅也是不可能推导清楚的。感兴趣可移步 [13-15]。
2.2 正向图像扩散(forward image diffusion)
2.2.1 基本原理
向图像逐渐添加高斯噪声,直到图像完全无法识别。
这个过程可以被形式化为顺序扩散马尔可夫链(Markov chain of sequential diffusion steps)。
2.2.2 数学描述
- 假设图像服从某种初始分布 q(x0)q(x0),
- 那么,我们可以对这个分布采样,得到一个图像 x0x0,
- 接下来,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









