







今天看了yolov4的论文,发现他在相关工作部分的最后总结的很好,对于整个yolo系列无非就是按照下面图所构建的,输入:图片(经过各种各样的数据增强)。主干网络(残差网络,vgg网络,mobile网络,darknet网络。脖子部分(Neck):SPP,PAN,FPN等增强特征的网络。检测头:分为回归框和分类类别等(其中有耦合和非耦合(Yolox中使用的))

2.2免费菜:
1.数据增强:目的是增加输入图像的可变性,使所设计的目标检测模型对从不同环境获得的图像具有更高的鲁棒性。例如,光度畸变和几何畸变是两种常用的数据增强方法,它们肯定有利于目标检测任务。在处理光度失真时,我们调整图像的亮度、对比度、色调、饱和度和噪声。对于几何变形,我们添加了随机缩放、裁剪、翻转和旋转。并且还有一种就是掩码形式的数据增强,比如马赛克数据增强,还有一种基于gan网络的数据增强。
2.检测头:作者认为对于标签平滑也是一种不错的方式,并且能够防止过拟合
3.回归框:作者的大致的意思就是,如果直接预测框的坐标和大小不好,很难训练或者不准确,而对于预测偏移值会更棒,并且作者也说明,对于IOU的应用,要更改一些更有效果的CIOU,DIOU等作为损失函数,从而使在BBox回归问题上获得更好的收敛速度和精度。
2.3特色菜
作者认为能够即插即用的,并且能够增加少许效果的方式叫做特色菜。如扩大感受野(SPP)、引入注意机制(通道注意力机制,空间注意力机制等)或增强特征整合能力(FPN,PAN)等,后处理(NMS,soft-NMS)是筛选模型预测结果的一种方法。还有一些激活函数的使用,LReLU和PReLU的主要目的是解决当输出小于零时,ReLU的梯度为零的问题。至于ReLU6和hard Swish,它们是专门为量化网络设计的。为了实现神经网络的自规范化,提出了SELU激活函数。需要注意的是,Swish和Mish都是连续可微的激活函数。
对于主干网络,作者给了一定的阐述,并且给了下面3个主要的分类网络:并且在经过实验的情况下,CSPDarknet53神经网络是将两者作为探测器主干的最佳模型。

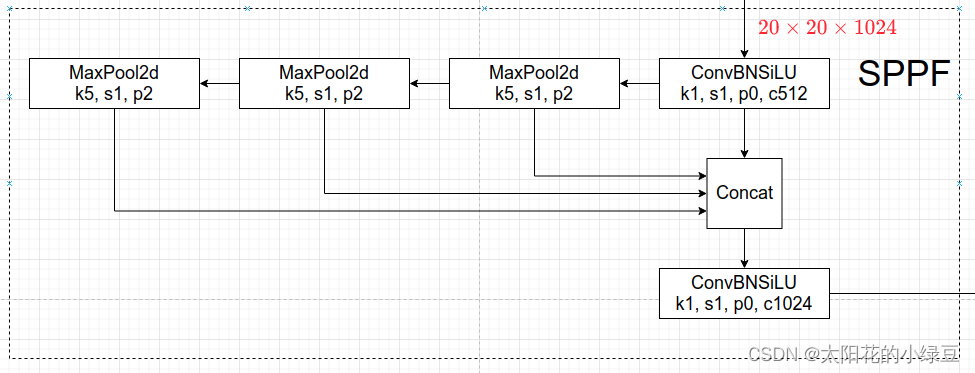
最后,作者选择CSPDarknet53主干、SPP附加模块、PANet路径聚合颈和基于锚的YOLOv3头作为YOLOv4的体系结构。 其中SPP在最新的yolov5已经发生了改进,并且在相同结果下,推理时间更低,它就是SPPF。代码图片来源:YOLOv5网络详解_太阳花的小绿豆的博客-CSDN博客
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
一般的目标检测中会有下面的基本内容,那么作者在这基本内容中删除了一些,然后加上了自己的改进,如下两个图:


对于注意力机制,作者也进行改变,如下图:如果不懂就看这篇大佬的博客:神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_Bubbliiiing的博客-CSDN博客_pytorch图像自注意力机制

还有一点的改进就是对于PAN网络的改变,原先的PAN网络是直接在特征上面进行相加的(就是输入输出的特征大小一样的),改进后的PAN网络在通道上进行拼接(就是输出的通道数比输入通道数大),具体看下面的图:

最后总结一下,作者在yolov4中使用的方法(相信大家应该能看懂吧,哈哈):

对于后面的部分,个人觉得还是看这位大佬所写的,非常详细。YOLOv4网络详解_太阳花的小绿豆的博客-CSDN博客_yolov4网络结构图
其中SAT是一种自对抗训练数据增强方法,这一种新的对抗性训练方式。在第一阶段,神经网络改变原始图像而不改变网络权值。以这种方式,神经网络对自身进行对抗性攻击,改变原始图像,以制造图像上没有所需对象的欺骗。在第二阶段,对修改后的图像进行正常的目标检测。
不知道大家看上面的含义有没有懂哈,就是SAT的目的就是增加网络的鲁棒性,意思就是一张图片如果有了一些污点,网络照样能够识别出来这个图片的物体,所以SAT的目的就是在第一次反向传播的时候,不对网络权重进行求导,反而对输入图片x进行求导,这样就在原始图片上增加了一些噪音,相当于原始图片就有了一些污点,然后后面就开始对网络的权重进行更新,让网络更加聪明,能够知道图片的物体是什么。
















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









