







目录
一、前言
本项目通过YOLOv11/YOLOv10/9/8/7/6/5/EfficientDet车辆目标检测+ultra fast lane detection v2车道线检测+ByteTrack跟踪,实现了一个具有碰撞警告、车道偏离预警、车道保持辅助三种功能的ADAS自动驾驶辅助算法,可用于实际企业工业项目,也可作为同学们的毕设参考或自己的学习资料。可提供整套代码(含详细注释)、训练好的权重、数据集、测试视频和详细说明文档。可以部署到树莓派、香橙派、Jetson Nano、瑞芯微RK3588等开发板上,也可调用摄像头输入视频流进行实时推理。
视频实时测试效果展示如下:
https://www.bilibili.com/video/BV1yK4be1EiL/?share_source=copy_web&vd_source=138d2e7f294c3405b6ea31a67534ae1a
1、项目介绍
ADAS(Advanced Driver Assistance Systems)自动驾驶辅助系统是一系列技术,旨在提高驾驶安全性、及时提示驾驶员或自动驾驶系统,避免可能出现的安全事故。本项目利用摄像头(行车记录仪等)实时采集视频数据并结合多个逻辑后处理算法来监测车辆前方的行驶动态,并根据情况提供预警信息。
我们的项目可为兄弟们的毕设、课设、大作业等提供参考,也可为工业实际项目提供技术支撑,可训练自己的数据集,可以换成yolov11/yolov10/9/8/7/6/5/EfficientDet各种版本的权重。包含特别详细的read.md文件和常见问题解答,关于本项目的任何问题都能在其中找到答案,对刚接触深度学习、目标检测的小白非常友好,兄弟们放心哈。
2、测试效果展示
可以看到,我们实验室的项目能有效实现ADAS自动驾驶辅助系统的各种功能(碰撞警告、车道偏离警告、车道保持辅助)。

(1)前车碰撞预警(FCWS):
1、提示"Determined …"或"Normal Risk"表示判断中或无风险,字体为黄色或绿色;
2、提示 “Prompt Risk”,表示低碰撞风险,字体为橙红色;
3、提示 “Warning Risk”,表示高碰撞风险,字体为红色;
(2)车道偏离预警(LDWS):
1、Offset的值为车辆中心偏离车道线的距离,偏右为负值,偏左为正值;
2、R为车道线平均曲率半径;
3、LDWS的值为“Please Keep Left”,警告驾驶人员或自动驾驶系统需靠左行驶,保证安全(此时车辆中心偏离车道线右侧,偏离左侧同理);
4、LDWS的值为“Good Lane Keeping”,表示车辆中心小幅度偏离或未偏离车道线;
(3)车道保持辅助(LKAS):
1、To Be Determined …,待分析;
2、Keep Straight Ahead,保持直行;
3、Gentle Left Curve Ahead,前方缓慢左转;
4、Hard Left Curve Ahead,前方左急弯;
5、Gentle Right Curve Ahead,前方缓慢右转;
6、Hard Right Curve Ahead,前方右急弯;
碰撞警告:前车碰撞预警系统(Forward Collision Warning System,FCWS)是一种先进的驾驶辅助技术,旨在提高行车安全。该系统通过分析与前方车辆或障碍物的距离,预测潜在的碰撞风险。当系统检测到可能发生碰撞的情况时,会发出警告信号,如声光报警或震动座椅,提醒驾驶员采取紧急制动或避让措施。FCWS在高速公路和城市道路上都能有效减少追尾事故的发生,提高行车安全性,尤其在驾驶员注意力不集中或视线受阻时尤为重要。
车道偏离警告:车道偏离警告系统(Lane Departure Warning System,LDWS)通过安装在车辆前方的摄像头,实时监测车道标线,并检测车辆是否意外偏离原车道。当系统检测到车辆未开启转向灯且无意偏离车道时,会发出警告信号,如声光报警或震动方向盘,提醒驾驶员纠正方向。LDWS特别适用于高速公路和长时间驾驶的情况下,有助于防止因驾驶员疲劳、注意力分散或打瞌睡等原因导致的车道偏离事故。通过及时预警,LDWS能显著降低交通事故的风险,提高行车安全性,是现代车辆安全系统中的重要组成部分。
车道保持辅助:车道保持辅助系统(Lane Keeping Assistance Systems,LKAS)利用车载摄像头实时监测道路上的车道标线,当检测到车辆偏离车道时,系统会自动对方向盘施加轻微的修正力,帮助车辆重新回到车道中央。即使在驾驶员注意力分散或疲劳的情况下,LKAS也能有效防止车辆偏离车道,降低事故风险。这一技术特别适用于高速公路和长时间驾驶,既能减少驾驶员的疲劳感,又能增强行车的稳定性和安全性。LKAS的自动干预功能不仅提高了整体驾驶体验,还为驾驶员提供了额外的安全保障。
这些功能的目的是提高驾驶安全性,减少交通事故的发生,并提供更舒适的驾驶体验。通过结合多种智能算法,ADAS系统可以实时监测和分析车辆前方的环境,并根据情况采取相应的行动,从而为驾驶员提供全方位的辅助和保护。
二、项目环境配置
我们的项目环境要求如下:
1、Python 3.7+
2、OpenCV、 Scikit-learn、onnxruntime、pycuda、pytorch
3、我们项目中requirements.txt里面包含的所有包
强调一下:建议直接拿我们的项目过去,一边配环境一边调试运行,看代码运行窗口输出报什么错,就对应搜csdn,针对性装什么包。不要想着一次性装好所有东西再执行项目,一方面有可能自己感觉装好了,还是缺包,一方面很可能存在包的版本不兼容等问题,这样效率非常低。
不熟悉pycharm的anaconda的大兄弟请先看这篇csdn博客,了解pycharm和anaconda的基本操作。
https://blog.csdn.net/ECHOSON/article/details/117220445
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
conda create -n yolov8 python==3.8.5
conda activate yolov8
1、pytorch安装
实际测试情况是我们的项目在CPU和GPU的情况下均可使用,不过CPU推理稍慢而已,有独显的小伙伴还是尽量安装GPU版本的Pytorch。GPU版本安装的具体步骤可以参考这篇文章:https://blog.csdn.net/ECHOSON/article/details/118420968。
需要注意以下几点:
1、安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
2、30系显卡只能使用cuda11的版本
3、一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
安装完毕之后,我们来测试一下GPU是否可以有效调用:

2、pycocotools的安装
pip install pycocotools-windows
3、pycuda安装
参考博客链接:http://t.csdnimg.cn/AqIYW
4、Scikit-learn安装
参考博客链接:http://t.csdnimg.cn/JytSF
5、onnxruntime-gpu安装
参考博客链接:http://t.csdnimg.cn/gkbcH
6、其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到项目代码的目录下,在终端中直接执行下列指令即可完成。
pip install -r requirements.txt
三、项目涉及到的ultra fast lane detection v2车道线检测和ByteTrack跟踪等技术
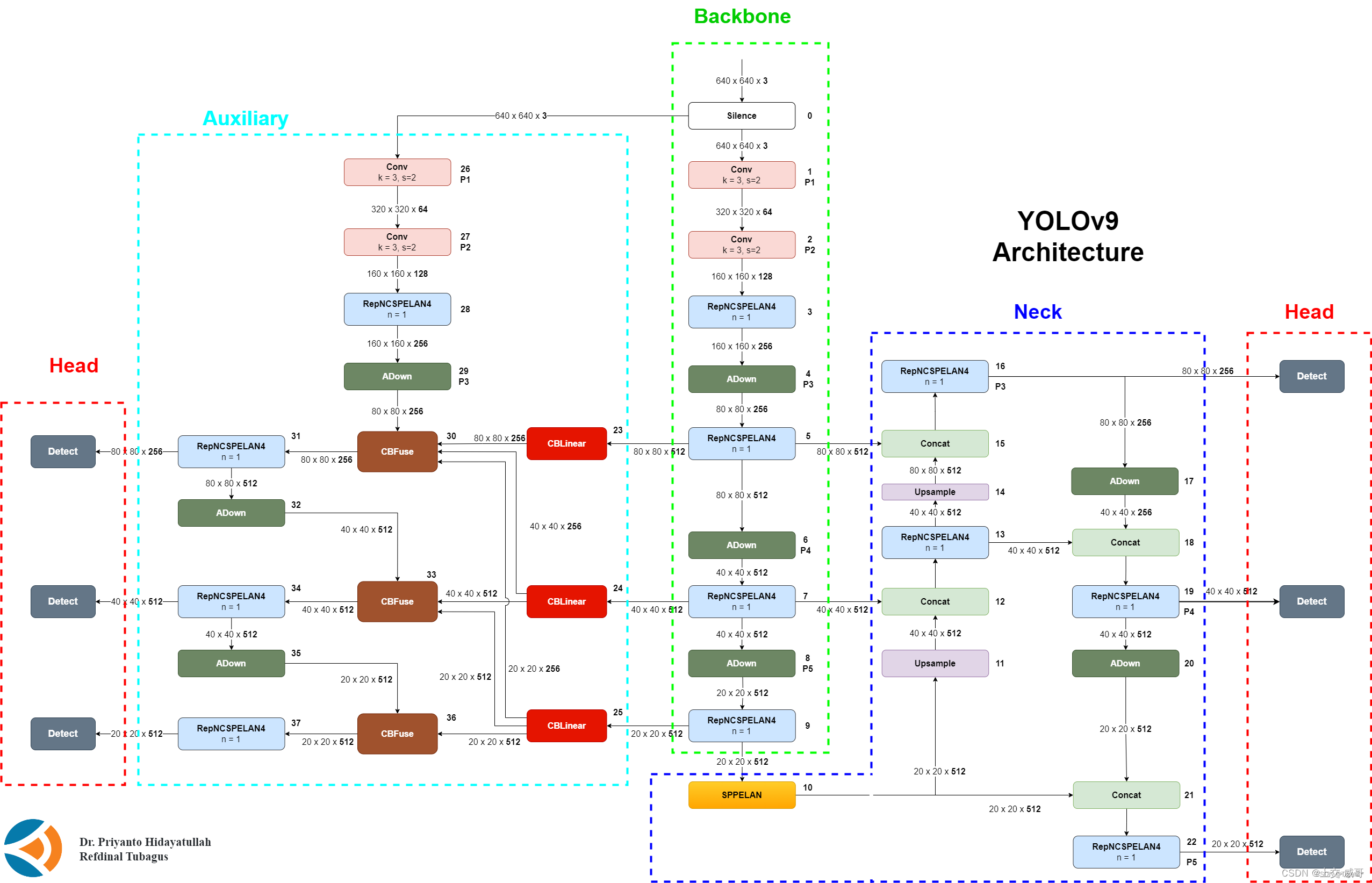
1、yolov9算法
YOLOv9是YOLO (You Only Look Once)系列实时目标检测系统的最新版本。它建立在以前的版本之上,融合了深度学习技术和架构设计的进步,以在对象检测任务中实现卓越的性能。YOLOv9将可编程梯度信息(PGI)概念与通用ELAN(GELAN)架构相结合而开发,代表了准确性、速度和效率方面的重大飞跃。
YOLOv9主要特点:
1.实时对象检测: YOLOv9通过提供实时对象检测功能保持了YOLO系列的标志性功能。这意味着它可以快速处理输入图像或视频流,并准确检测其中的对象,而不会影响速度。
2.PGI集成: YOLOv9融合了可编程梯度信息(PGI)概念,有助于通过辅助可逆分支生成可靠的梯度。这确保深度特征保留执行目标任务所需的关键特征,解决深度神经网络前馈过程中信息丢失的问题。
3.GELAN架构: YOLOv9采用通用ELAN (GELAN)架构,旨在优化参数、计算复杂度、准确性和推理速度。通过允许用户为不同的推理设备选择合适的计算模块,GELAN增强了YOLOv9的灵活性和效率。
4.性能提升:实验结果表明,YOLOv9在MS COCO等基准数据集上的目标检测任务中实现了最佳性能。它在准确性、速度和整体性能方面超越了现有的实时物体检测器,使其成为需要物体检测功能的各种应用的最先进的解决方案。
5.灵活性和适应性: YOLOv9旨在适应不同的场景和用例。其架构可以轻松集成到各种系统和环境中,使其适用于广泛的应用,包括监控、自动驾驶车辆、机器人等。
6.主分支集成: PGI的主分支代表网络在推理过程中的主要路径,可以无缝集成到YOLOv9架构中。这种集成确保推理过程保持高效,而不会产生额外的计算成本。
7.辅助可逆分支: YOLOv9和许多深度神经网络一样,随着网络的加深,可能会遇到信息瓶颈的问题。可以合并PGI的辅助可逆分支来解决这个问题,为梯度流提供额外的路径,从而确保损失函数的梯度更可靠。
8.多级辅助信息: YOLOv9通常采用特征金字塔来检测不同大小的物体。通过集成来自PGI的多级辅助信息,YOLOv9可以有效处理与深度监督相关的错误累积问题,特别是在具有多个预测分支的架构中。这种集成确保模型可以从多个级别的辅助信息中学习,从而提高不同尺度的对象检测性能。
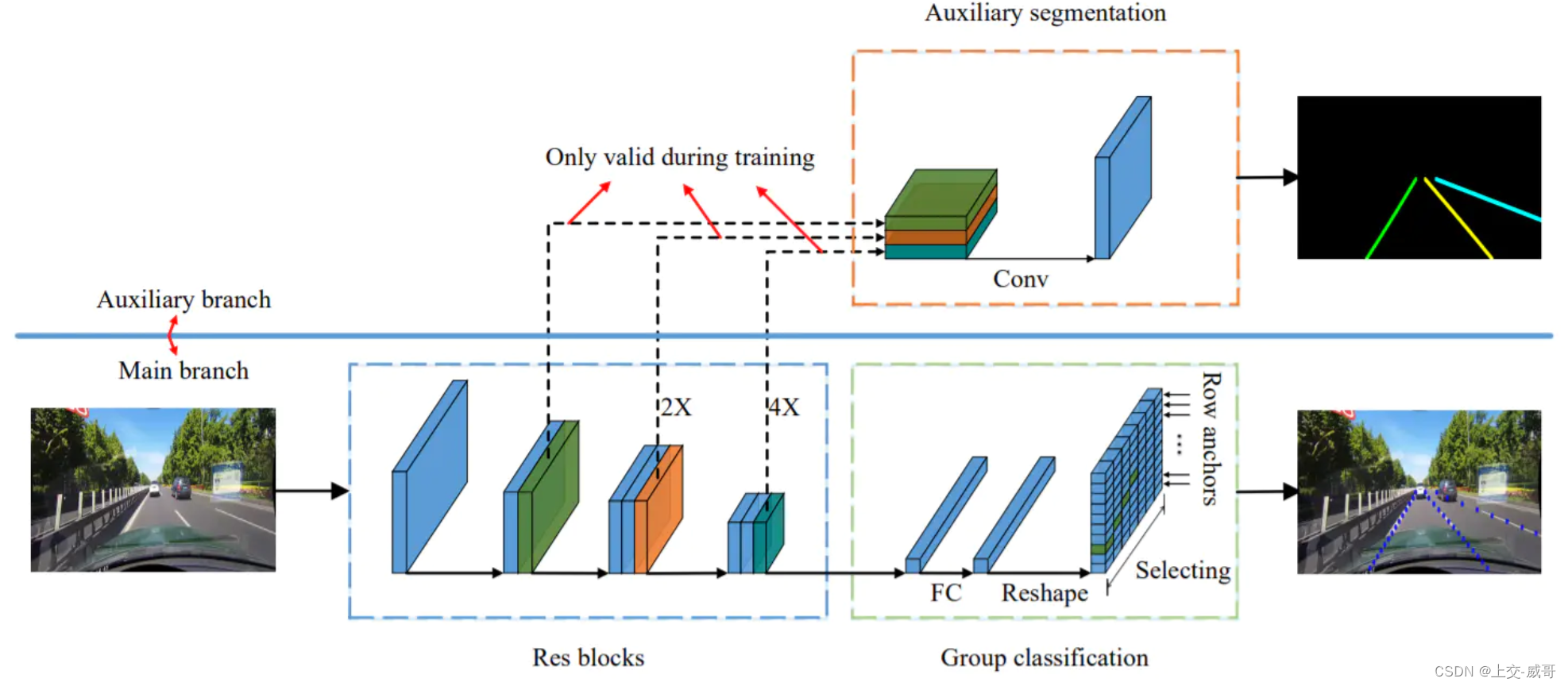
2、ultra fast lane detection v2车道线检测算法
现代的方法主要把车道线检测一看作像素级的分割问题,这导致效率问题以及遮挡和极端光照条件场景等问题变得很难解决。受人类感知的启发,严重遮挡和极端光照条件下的车道线识别主要基于上下文和全局信息。基于这一观察结果,提出了一种新颖、简单、有效的范式,旨在实现超快的速度和解决有挑战性场景的问题。具体而言,把车道检测过程看作一个使用全局特征的anchor-driven的顺序分类问题。首先,用基于一系列混合anchor(行和列anchor)的稀疏坐标来表示车道线。在anchor-driven表示的帮助下,将车道检测任务重新表述为有序分类问题,以获得车道线的坐标。该方法采用anchor-driven表示,大大降低了计算成本。利用ordinal classification范式的大感受野特性,能够处理具有挑战性的场景。在四个车道检测数据集上的广泛实验表明,我们的方法可以在速度和准确性方面达到最先进的性能。轻量级版本甚至可以达到每秒300帧以上(FPS)。
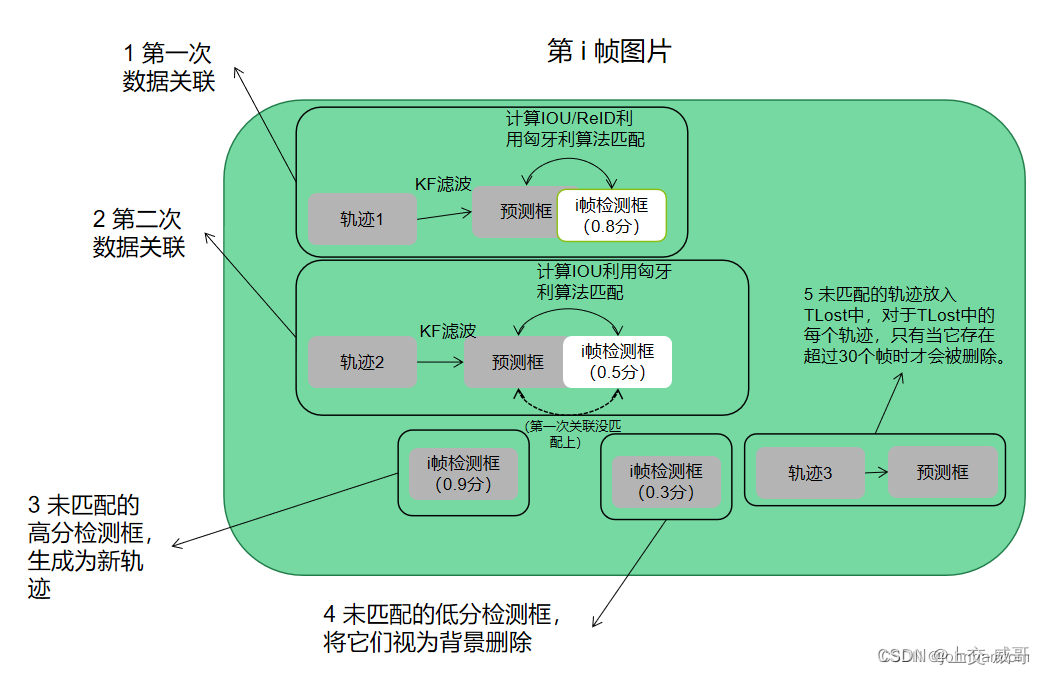
3、ByteTrack车辆跟踪算法
ByteTrack算法是一种基于目标检测的追踪算法,和其他非RelD的算法一样,仅仅使用目标追踪所得到的box进行追踪。追踪算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配。ByteTrack算法的最大创新点就是对低分框的使用,作者认为低分框可能是对物体遮挡时产生的框,直接对低分框抛弃会影响性能,所以作者使用低分框对追踪算法进行了二次匹配,有效优化了追踪过程中因为遮挡造成换id的问题。ByteTrack的主要特点:
1、没有使用RelD特征计算外观相似度
2、非深度方法,不需要训练
3、利用高分框和低分框之间的区别和匹配,有效解决遮挡问题
数据关联模块是多目标跟踪模型的核心,它首先计算轨迹和检测盒之间的相似度,然后根据相似度采用不同的策略进行匹配,ByteTrack方法与以往的只保留高分检测盒的数据关联方法不同,它几乎保留了每个检测框,并将其分为高分检测框和低分检测框。它首先将高分检测框与现有的轨迹相关联。一些轨迹不匹配是因为它们与适当的高分检测框不匹配,这通常在发生遮挡、运动模糊或大小更改时发生。然后,它将低分检测框与这些不匹配的轨迹相关联,以恢复低分检测框中的对象,并同时滤除背景。
BYTE的输入是视频序列V,以及对象检测器DET,检测分数阈值r,它的输出是视频的轨迹T,每个轨迹包含每个帧中对象的包围盒和标识。
1)对于视频中的每一帧,首先使用检测器DET获得检测框和分数,然后根据检测分数阈值r将所有的检测框分为DHigh和DLow两部分。对于得分高于r的检测框放入高分检测箱DHigh中,得分低于r的检测框放入DLow中(算法1中的第3至13行),然后采用卡尔曼滤波对每个轨迹的当前帧中的新位置进行预测。
2)对高分检测框DHigh和所有的轨迹(包括TLost)之间执行第一次关联。相似度可以通过检测框DHIGH和预测轨迹框之间的IOU或Re-ID特征距离来计算。然后,采用匈牙利算法完成基于相似度的匹配。未匹配的检测保存在Dremain中,未匹配的轨迹保存在Tremain中
3)在第一次关联之后;对Dlow和Tremian执行第二次关联,关联过程跟第一次关联大体类似,但论文中指出,第二次关联时只单独使用IOU作为相似性,因为低分检测框通常包含严重的遮挡或运动模糊,并且外观特征不可靠。保留Tremain里未匹配的轨迹,删除DLow中所有未匹配的低分检测框,将它们视为背景。
4)两次关联后,不匹配的轨迹将被删除。但是算法1中并没有介绍这些轨迹再生的过程,实际上第二次关联后剩下的未匹配的轨迹Tremain,将会被放入TLost中。对于TLost中的每个轨迹,只有当它存在超过30个帧时才会被删除。
5)最后将会对Dremain里未匹配的高分检测框初始化为新的轨迹。每个单独帧的输出是当前帧中轨迹T的边界框和标识(不输出Tloost的框和身份)。
四、ADAS自动驾驶辅助系统(前车碰撞预警、车道偏离预警、车道保持辅助)
1、前车碰撞预警(FCWS,Forward Collision Warning System)
前车碰撞预警系统(Forward Collision Warning System,FCWS)是一种先进的驾驶辅助技术,旨在提高行车安全。该系统利用传感器实时监测车辆前方的道路情况,通过分析与前方车辆或障碍物的距离,预测潜在的碰撞风险。当系统检测到可能发生碰撞的情况时,会发出警告信号,如声光报警或震动座椅,提醒驾驶员采取紧急制动或避让措施。FCWS在高速公路和城市道路上都能有效减少追尾事故的发生,提高行车安全性,尤其在驾驶员注意力不集中或视线受阻时尤为重要。
测距代码如下,定义为distanceMeasure.py中SingleCamDistanceMeasure的类函数。主要是使用图像像素距离和实际空间距离做了一个映射,与本实验室另一个测距项目原理基本一致,兄弟们可参考学习这个博客:https://blog.csdn.net/weixin_44944382/article/details/128518452?spm=1001.2014.3001.5502。里面有详细解释,这里不再赘述。当然,每个测试视频(如果各位兄弟想用自己的视频做测试的话)的拍摄设备不一样,焦距、畸变等参数差别很大,这一定程度上会影响我们算法的测距精度。因此,distanceMeasure.py中第10行设置了一个比例因子scale,可根据自己视频跑出来的实际情况进行调整,使测得的距离尽量精确。若如果需要更为详尽的测距理论,请参见前述给出的博客链接。

测距完成后,需要进行碰撞风险的判断,从而提示驾驶人员或自动驾驶系统。本项目将碰撞风险判断代码放在了taskConditions.py这个脚本中,通过在demo.py中调用UpdateCollisionStatus这个类函数,并传入前述测距代码测得的距离等数据进行判断,将判断得到的碰撞风险标志更新至ObjectDetector/utils.py中定义的碰撞标志类中,用于后续在结果视频画面上进行文字输出时读取。另外,在UpdateCollisionStatus类函数中传入了一个lane_area的标志,这个布尔变量只有ture和false两种状态,用于判断当前进行风险判断的前面的车辆是否在当前车辆行驶范围内(当前车辆行驶的车道线范围内)。



整体的判断逻辑是,首先判断当前测到的距离是否为空,若为空值,则判断前方车辆是否在有效范围内,若在有效范围内,则将类变量定义为NORMAL,提示"Normal Risk",如图:

否则前车不在有效范围内,且测得的距离为空值,则类变量定义为UNKNOWN,提示"Determined …",表示有效车道区域内没有出现车辆,且没有测到任何车辆的距离值。当然,如果在各种环境因素的影响下,车道线实在与地面颜色太过接近,轮廓太过模糊,没有检测到车道线(小概率事件),也有可能出现这种提示。如图:

若检测到的车辆距离不为空,测得的5帧内的平均距离小于自己定义的distance_thres(这里设置为3m),则类变量定义为WARNING,提示 “Warning Risk”,表示具有碰撞的风险。

若检测到的车辆距离不为空,测得的5帧内的平均距离介于自己定义的distance_thres值和的distance_thres2倍值之间,则类变量定义为PROMPT,提示 “Prompt Risk”,表示程度较轻的碰撞风险。

至于上述效果图中的Offset和R值是什么,与本节碰撞检测基本无关,我将在下一节中解释。
2、车道偏离警告(LDWS,Lane departure warning system)
车道偏离警告系统(Lane Departure Warning System,LDWS)是一种先进的驾驶辅助技术,旨在提高车辆行驶的安全性。该系统通过安装在车辆前方的摄像头,实时监测车道标线,并检测车辆是否意外偏离原车道。当系统检测到车辆未开启转向灯且无意偏离车道时,会发出警告信号,如声光报警或震动方向盘,提醒驾驶员纠正方向。LDWS特别适用于高速公路和长时间驾驶的情况下,有助于防止因驾驶员疲劳、注意力分散或打瞌睡等原因导致的车道偏离事故。通过及时预警,LDWS能显著降低交通事故的风险,提高行车安全性,是现代车辆安全系统中的重要组成部分。
首先,调用本项目使用的UltrafastLaneDetectorV2车道线检测模型,为了实现更加准确的车道线偏离警告功能,将检测出车道线的图像输入封装好的函数转换为鸟瞰图:

然后,将转换好的鸟瞰图以及鸟瞰视角下的左右车道线位置输入这个判断函数中,计算得到左右车道线的平均曲率半径(即效果视频中的R值)、曲率方向、以及车辆中心(图像中心)偏离车道线中心的距离Offset(若车辆中心偏离车道线左侧,Offset显示为正值;若车辆中心偏离车道线右侧,Offset显示为负值)。

车道线曲率半径代表车道线弯曲的程度,具体来说,它是描述车道曲线半径的几何属性。曲率半径是曲线的半径,它表示如果车道线延展成一个圆,该圆的半径是多少。较大的曲率半径表示车道较为平直,而较小的曲率半径则表示车道弯曲较大。对于驾驶辅助系统,如车道保持辅助系统(LKAS)和车道偏离警告系统(LDWS),曲率半径是重要的参数。系统利用曲率半径来判断车辆是否在车道内正确行驶,并根据道路的弯曲程度调整车辆的行驶轨迹。通过精确计算车道线的曲率半径,这些系统能够更好地预测和调整车辆的行驶路线,增强驾驶体验和安全性。曲率半径计算过程如图所示:

如图,图中“白色箭头”为车道线中心位置,“灰色箭头”为当前车辆中心位置,车辆中心偏离车道线右侧,Offset显示为负值1.2m,当前检测到的车道线平均曲率半径为3260.2m。

由于车辆中心偏离车道线右侧,则LDWS算法提示“Please Keep Left”,警告驾驶人员或自动驾驶系统需靠左行驶,保证安全。

若车辆中心偏离车道线左侧,则LDWS算法提示“Please Keep Right”,警告驾驶人员或自动驾驶系统需靠右行驶,保证安全。


若车辆中心小幅度偏离或未偏离车道线,则LDWS算法提示“Good Lane Keeping”。


3、车道保持辅助(LKAS,Lane Keeping Assistance Systems)
车道保持辅助系统(Lane Keeping Assistance Systems,LKAS)是一项先进的驾驶技术,旨在提升行车安全。该系统利用车载摄像头实时监测道路上的车道标线,当检测到车辆偏离车道时,系统会自动对方向盘施加轻微的修正力,帮助车辆重新回到车道中央。即使在驾驶员注意力分散或疲劳的情况下,LKAS也能有效防止车辆偏离车道,降低事故风险。这一技术特别适用于高速公路和长时间驾驶,既能减少驾驶员的疲劳感,又能增强行车的稳定性和安全性。LKAS的自动干预功能不仅提高了整体驾驶体验,还为驾驶员提供了额外的安全保障。
本项目中设置了一个阈值curvae_thres,用于在_calc_direction函数中调整获取曲率半径状态的阈值。这个阈值可以根据自己运行出来的效果灵活调整。

下面这段Python代码定义了一个方法,用于判断车道的曲率半径状态。如果输入的平均曲率半径值小于等于设定的阈值,则判定为硬曲线;根据曲率方向(左或右),返回相应的硬曲线类型(如左硬曲线或右硬曲线)。如果曲率半径大于阈值,则判定为软曲线,返回相应的软曲线类型(左软曲线或右软曲线),或者如果方向未知则返回直行状态。最终,该方法返回一个表示曲率状态的枚举值,帮助驾驶辅助系统做出决策。此处车道曲线的软硬代表车道的“弯曲程度”,曲线越“硬”则表示弯道越急。

本项目的车道保持辅助(LKAS,Lane Keeping Assistance Systems)算法根据曲率半径的值以及车道弯曲的方向进行车道保持辅助提醒。根据不同的情况,分别输出
UNKNOWN = “To Be Determined …”----------->待分析
STRAIGHT = “Keep Straight Ahead”----------->保持直行
EASY_LEFT = “Gentle Left Curve Ahead”----------->前方缓慢左转
HARD_LEFT = “Hard Left Curve Ahead”----------->前方左急弯
EASY_RIGHT = “Gentle Right Curve Ahead”----------->前方缓慢右转
HARD_RIGHT = “Hard Right Curve Ahead”----------->前方右急弯

效果示例(保持直行):

五、代码使用
**使用pycharm打开项目,直接单击右键执行demo.py即可。**测试视频、模型、类别txt的相对路径已经在代码中设置好,可直接运行。lane_config这个字典中设置的是车道线检测模型的参数,模型类型"model_type"要与模型的权重路径"model_path"对应。object_config这个字典中设置的是车辆目标检测模型的参数,类似的,模型类型和权重路径要对应,"classes_path"代表coco目标检测类别txt路径。“box_score"为车辆检测置信度阈值设置,车辆检测IOU阈值设置为"box_nms_iou”,若出现车辆大量漏检等,调整这两个阈值即可。
video_path = "./test.mp4" # 视频路径设置
lane_config = {
"model_path": "./TrafficLaneDetector/models/ufldv2_culane_res18_320x1600.onnx", # 车道线检测权重路径(此处使用的是ONNX格式)
"model_type" : LaneModelType.UFLDV2_CULANE # 模型类型设置,参见README.md
}
object_config = {
"model_path": './ObjectDetector/models/yolov9-c.onnx', # 车辆检测权重路径(此处使用的是ONNX格式)
"model_type" : ObjectModelType.YOLOV9, # 模型类型设置,参见README.md
"classes_path" : './ObjectDetector/models/coco_label.txt', # coco目标检测类别txt路径设置
"box_score" : 0.4, # 车辆检测置信度阈值设置,若出现车辆大量漏检等,调整这两个阈值
"box_nms_iou" : 0.5 # 车辆检测IOU阈值设置
}
其他的我们都在代码里设置好了,如果需要将Onnx转化为TenserRT模型,或者量化Onnx,参照以下方式。
将Onnx转为TenserRT模型:
python convertOnnxToTensorRT.py -i <path-of-your-onnx-model> -o <path-of-your-trt-model>
量化ONNX模型:
python onnxQuantization.py -i <path-of-your-onnx-model>
支持的模型列表:
| Target | Model Type | Describe |
| :-------------: |:-----------------------------------------------| :--------------------------------- |
| Lanes | `LaneModelType.UFLD_TUSIMPLE` | 利用ResNet18主干网络支持Tusimple数据。 |
| Lanes | `LaneModelType.UFLD_CULANE` | 利用ResNet18主干网支持CULane数据。 |
| Lanes | `LaneModelType.UFLDV2_TUSIMPLE` | 利用ResNet18/34主干网支持Tusimple数据。 |
| Lanes | `LaneModelType.UFLDV2_CULANE` | 利用ResNet18/34主干网支持CULane数据。 |
| Object | `ObjectModelType.YOLOV5` | 支持yolov5n/s/m/l/x模型. |
| Object | `ObjectModelType.YOLOV5_LITE` | 支持yolov5lite-e/s/c/g模型. |
| Object | `ObjectModelType.YOLOV6` | 支持yolov6n/s/m/l, yolov6lite-s/m/l模型. |
| Object | `ObjectModelType.YOLOV7` | 支持yolov7 tiny/x/w/e/d模型. |
| Object | `ObjectModelType.YOLOV8` | 支持yolov8n/s/m/l/x模型. |
| Object | `ObjectModelType.YOLOV9` | 支持yolov9s/m/c/e模型. |
| Object | `ObjectModelType.YOLOV10` | Support yolov10n/s/m/b/l/x model. |
| Object | `ObjectModelType.EfficientDet` | 支持efficientDet b0/b1/b2/b3模型. |
六、自己训练的步骤和数据集
1、训练步骤
对于兄弟们的毕设、课设项目来说,没有必要再重新训练一遍。一方面耗时费力,自己的电脑也不一定跑的动;另一方面我这边会提供所有的训练过程曲线、数据、和训练好的权重,直接调用就行。本项目的重点是各个辅助驾驶功能的逻辑判断算法,而不是目标检测。如有兄弟实在需要自己重新训练或者在我们提供官方权重基础上使用自己数据集fine tune的话,可参考链接:YOLOV9训练自己的数据集,使用YOLOV9官方版本代码训练,并转为.onnx后使用我们的代码调用即可。
2、数据集
我们使用的是官方检测权重,故训练所用数据集为COCO,可参考以下教程进行下载:COCO下载链接。COCO(Common Objects in Context)数据集是一个广泛应用于目标检测、图像分割和图像描述的计算机视觉数据集,由微软公司发布。COCO数据集涵盖了80个常见的物体类别,包括人、动物、交通工具和家居用品等。它包含超过32万张图像,其中约20万张是精确标注的图像,共计250万个标注实例。COCO的标注不仅包括物体的边界框,还包含物体的像素级分割掩码和关键点标注。数据集中的图像场景复杂,具有多尺度、多视角和遮挡等挑战,极大地促进了计算机视觉领域的研究和进步。
七、整套代码、训练好的权重、测试视频、详细说明文档全套资源获取
项目包含详细的使用文档以及报错解决文档,基本所有相关问题都能在其中找到答案。

我们的项目代码可自动生成训练过程的loss损失曲线、map平均准确度曲线,不用手动画(太麻烦了,能用代码做的事尽量不手动),兄弟可以直接将这些图插入论文或课设报告中。当然,也可以自己训练,重新生成对应的图。训练结束后,这些图和训练数据会(以envents文件形式)存放在根目录下的runs文件夹中。我项目中已导出为PNG图片和CSV表格,可以直接拿去用。



包含完整word版本说明文档,里面基本为项目的核心内容,可用于写论文、项目代码说明书、课设报告等参考。

项目文件夹内容:

资源获取:
可提供整套代码、训练好的权重,还有测试视频和详细说明文档。代码有详细注释,包全程指导,任何问题都可以随时问我。不过有的时候我太忙,可能不会及时回复消息,看到了肯定回你哈
见下方官方推广途径。




















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











