









大家好,我是皮先生!!
本文将深入剖析DeepSeek模型核心技术-多头潜在注意力(MLA)的工作原理、技术创新,希望对大家的理解有帮助。
目录
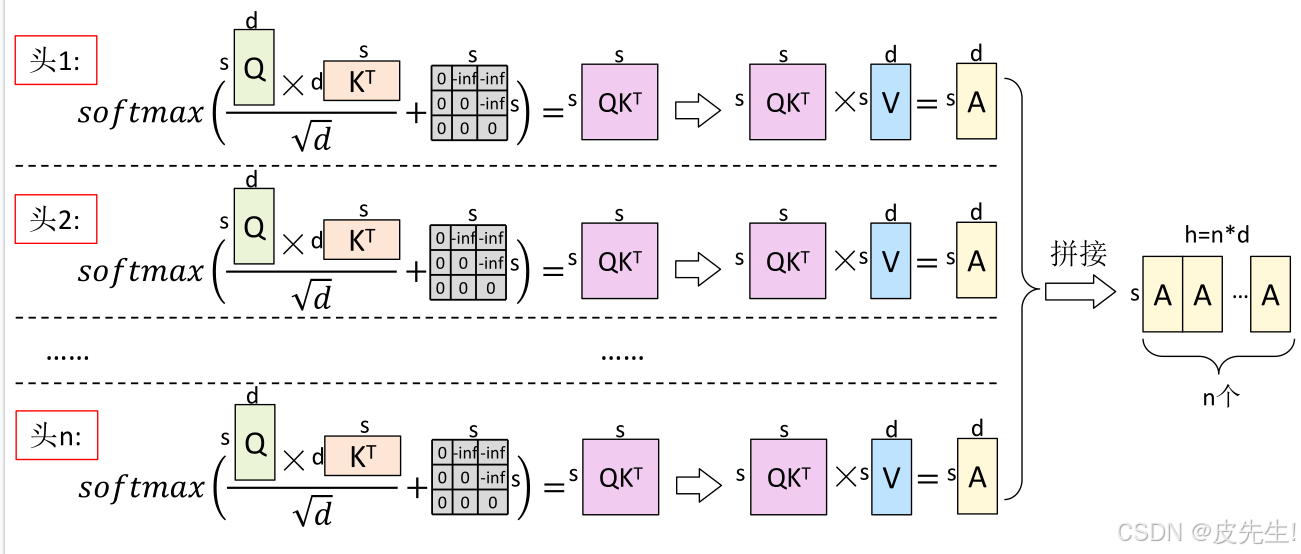
多头注意力机制(MHA)
传统的Transformer模型通常采用多头注意力机制(MHA) ,它通过将输入分割成多个头(heads)来并行计算注意力,每个头学习输入的不同部分,最终将结果合并,以捕获序列的不同方面信息 。但是,在自回归生成过程中,为了避免重复计算,其繁重的KV缓存将成为限制推理效率的瓶颈。
在MHA中,每个头有自己单独的 key-value 对。
(1)MHA的优点:多头注意力使用多个维度较低的子空间分别进行学习。一般来说,相比单头的情况,多个头能够分别关注到不同的特征,增强了表达能力。
(2)MHA的缺点:训练过程中,不会显著影响训练过程,训练速度不变,会引起非常细微的模型效果损失;推理过程中,反复加载巨大的KV cache,导致内存开销大。
 KV缓存带来的内存挑战:
KV缓存带来的内存挑战:
- 内存占用巨大:KV缓存大小与序列长度、批次大小、隐藏层维度以及注意力头的数量成正比。
- 线性扩展问题:随着处理序列长度的增加,内存需求呈线性增长。
- 实际应用限制:对于处理长文档或冗长对话的应用场景,内存瓶颈严重制约了模型的性能。
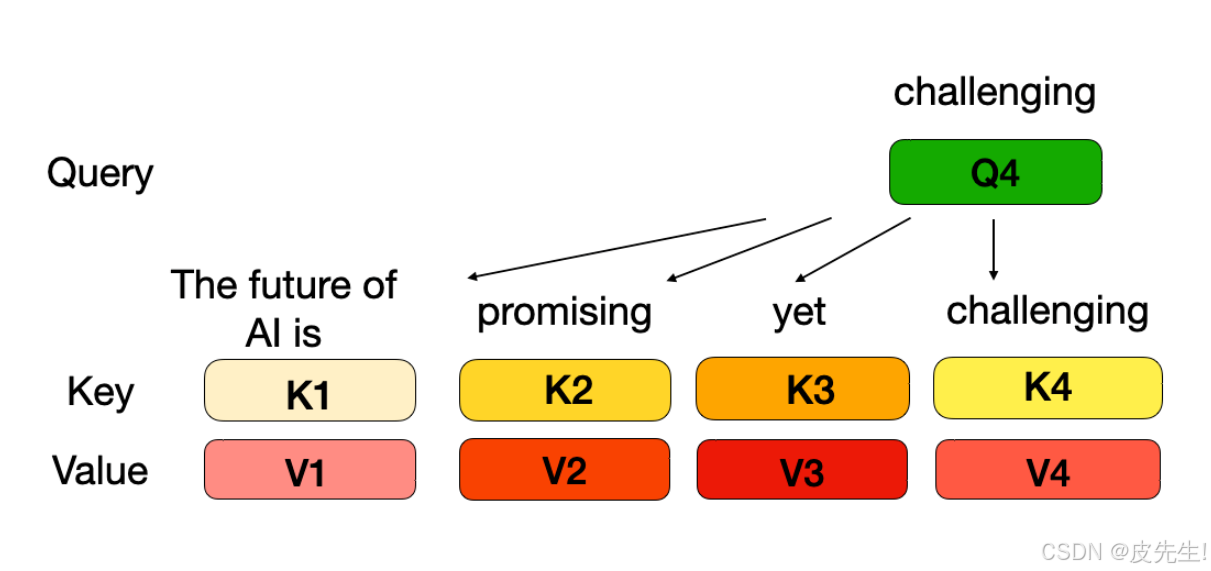
KV Cache
KV Cache的本质是以空间换时间,它将历史输入token的KV缓存下来,避免每步生成都重新计算历史的KV值。在每个解码步骤中,只计算新的查询 Q,而缓存中存储的 K 和 V 将被重复使用,因此将使用新的 Q 和重复使用的 K、V 来计算注意力。
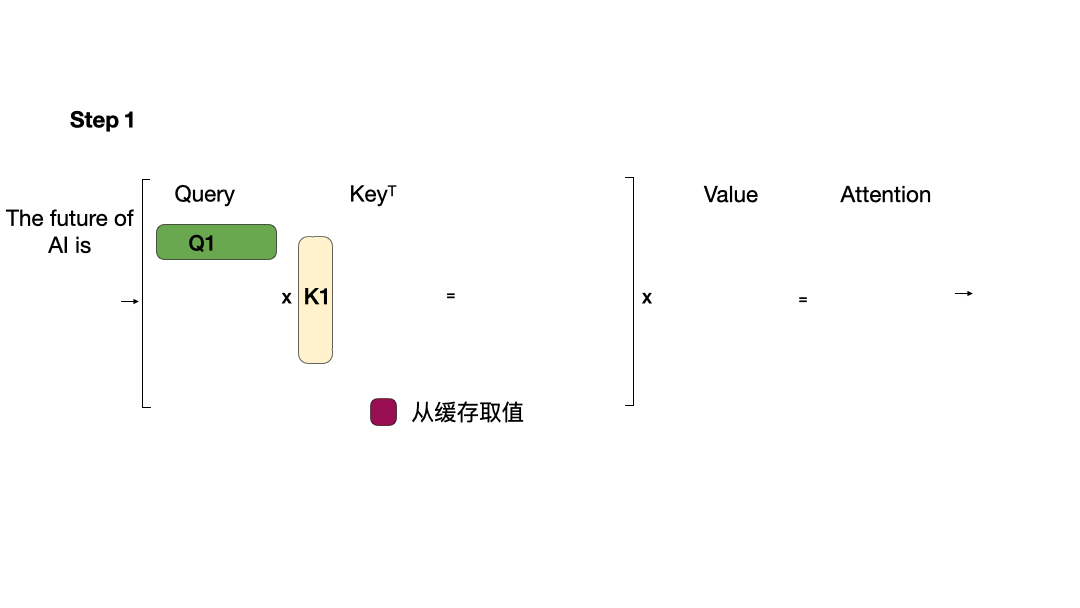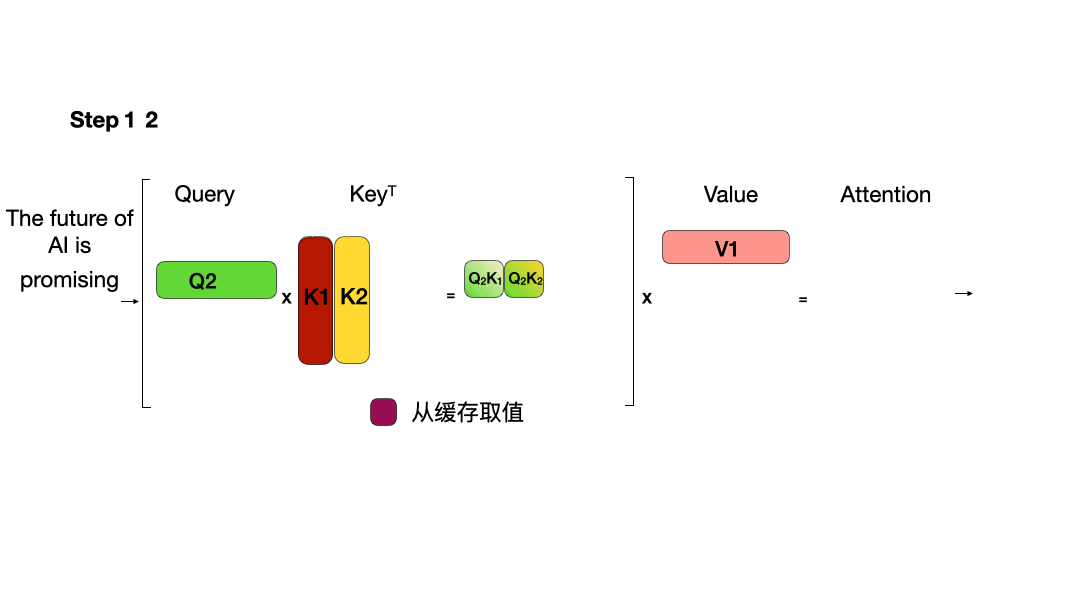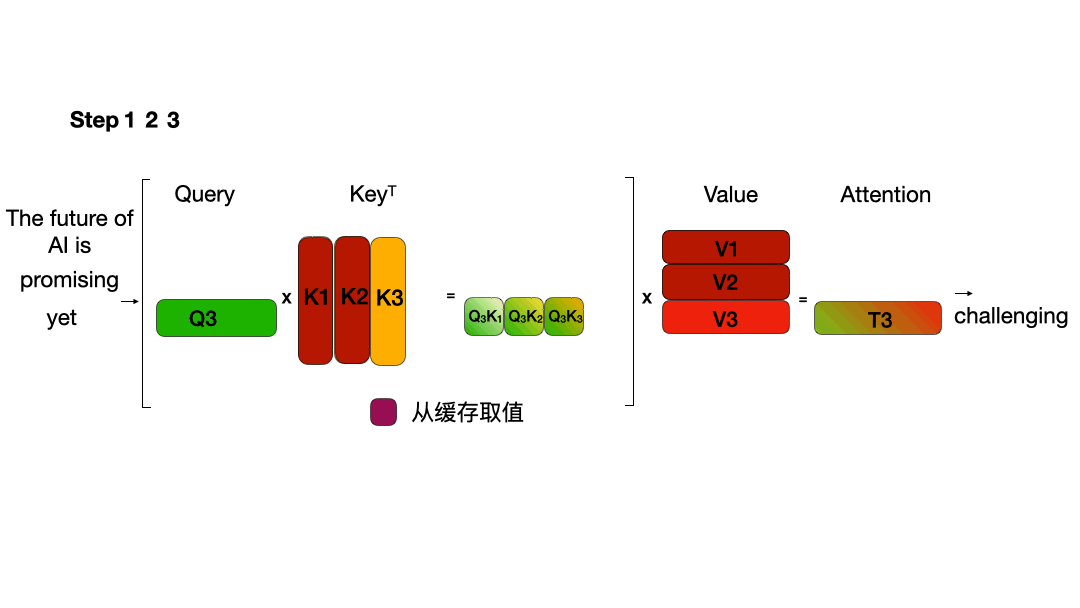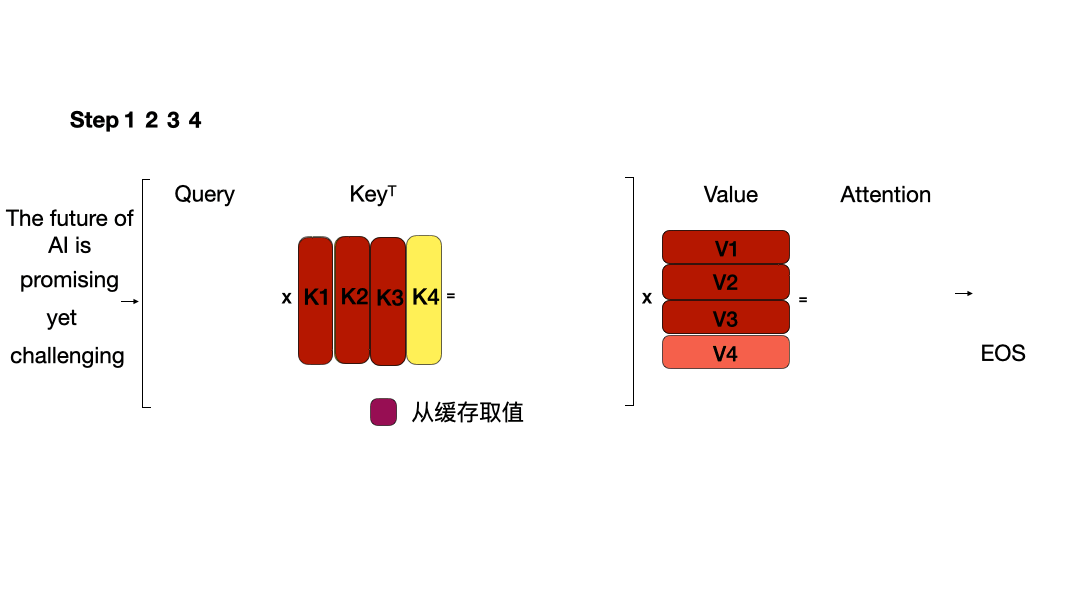
多查询注意力机制(MQA) 和分组查询注意力机制(GQA)
为了减少KV缓存,提出了共享KV优化显存方法:多查询注意力机制(MQA) 和分组查询注意力机制(GQA) 。
- MQA是一种MHA变体,它通过让所有的头之间共享同一份 key-value 对,从而大大减少 Key 和 Value 矩阵的参数量。虽然可以提升推理的速度,但是会带来精度上的损失。
- GQA是一种MHA和MQA的折中方案,它将查询头(query heads)分组,每组共享一个键和值,而不是所有头都共享。这样,GQA能够在减少计算量的同时,保持更多的多样性,从而在推理速度和模型精度之间取得平衡 ,精度比 Multi-query 好,同时速度比 Multi-head 快。
MQA和GQA的确可以减少KV缓存规模,但是性能却不及多头注意力机制(MHA) 。
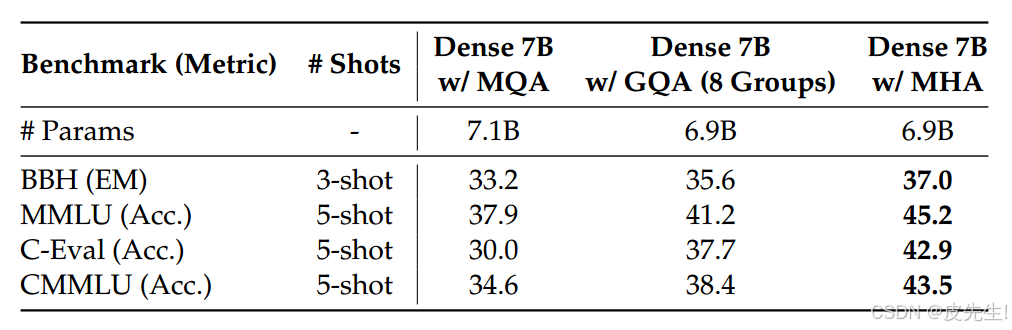
DeepSeek提出的多头潜在注意力(MLA)则是一种更为创新的解决方案,旨在在保持或提升性能的同时,显著降低内存和计算开销。MLA配备了压缩功能,其性能优于多头注意力(MHA),但所需的KV缓存(KV Cache)量显著减少。
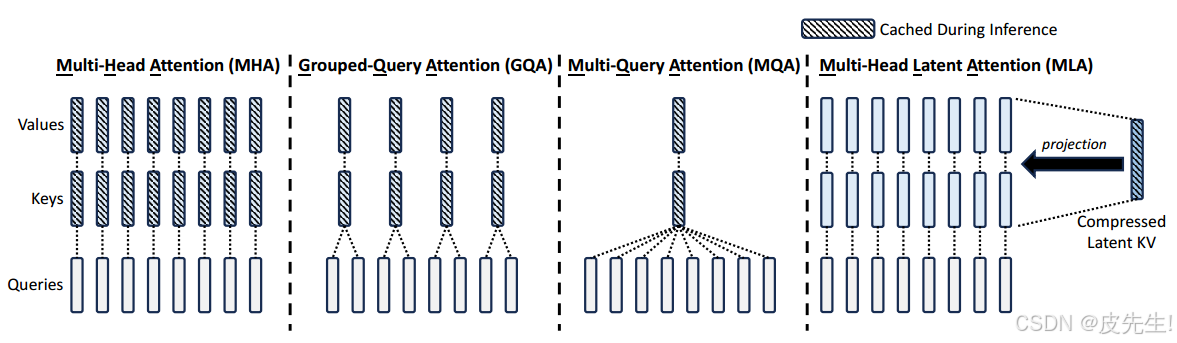
多头潜在注意力(MLA)
采用低秩键值联合压缩技术来显著减少KV缓存的内存占用,保持甚至提升性能。MLA 将多头注意力机制与潜在表示学习相结合,解决MHA在高计算成本和KV缓存方面的局限性。它通过将高维输入映射到低维潜在空间,然后在这个低维空间中执行多头注意力计算,从而减少计算量和内存占用。
MLA的工作流程:
- 输入映射到潜在空间:将输入数据通过一个映射函数投影到低维潜在空间。这一步骤类似于提取输入数据的核心特征,丢弃一些不重要的细节。
- 潜在空间中的多头注意力计算:在低维潜在空间中,执行多头注意力计算。将所有注意力头的输出拼接。
- 映射回原始空间:将多头注意力的结果从潜在空间映射回原始空间,得到最终的输出。
MLA 的优势
- 计算效率提升:通过在低维潜在空间中执行注意力计算,复杂度由 0(n^2*d)降至O(n^2k)。
- 语义表达增强:潜在空间提取输入数据的抽象语义特征,提升模型对全局依赖的捕捉能力。
- 模块化设计:MLA可与卷积网络、循环网络等深度学习模块无缝结合,适用于自然语言处理、计算机视觉等多种任务。
DeepSeek-V2的技术报告显示,MLA使KV缓存减少了93.3%,训练成本节省了42.5%,生成吞吐量提高了5.76倍。在8个H800 GPU上实际部署时,实现了超过50,000令牌每秒的生成速度,这一数据充分证明了MLA的高效性。
MLA的工作原理
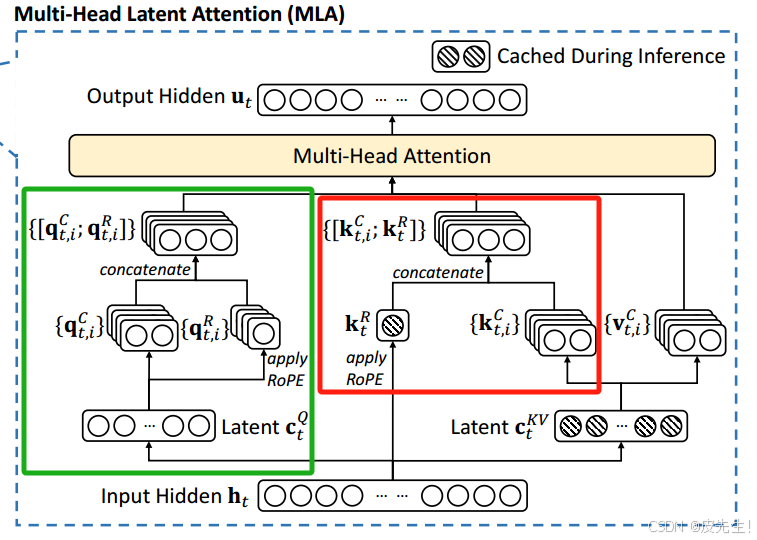
MLA的工作机制涉及以下几个关键步骤:
1. 低秩KV联合压缩
低秩分解:将一个矩阵(a,b)分解为两个矩阵(a,r)和(r,b),其中r<<a,b。在MLA中,通过将一个矩阵(Q和KV矩阵)分解为多个低秩矩阵(下投影矩阵和上投影矩阵)的乘积,显著减小了存储KV的维度,从而降低了内存占用。
- 在推理过程中,经过两个独立的下投影矩阵压缩后的低维K和V输出会进行缓存,从而大大减少 KV 缓存的内存占用。
- 在进行注意力计算时,MLA通过两个独立的上投影矩阵 W_UK和W_UV 将缓存中的潜在向量 {c_t}^KV 解压缩,重构出K、V矩阵。
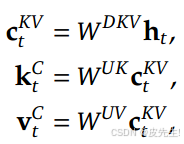
此外,为了减少训练期间的激活内存,还对查询也执行了低秩压缩,即使它不能减少KV缓存。
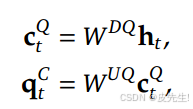
2. 解耦旋转位置嵌入(Decoupled RoPE)
为了整合相对位置信息,DeepSeek-V2(以及随后的 DeepSeek-V3 和 DeepSeek-R1)采用了解耦的旋转位置嵌入(RoPE)方法。该方法用额外Query和共享Key专门处理相对位置信息(RoPE),避免RoPE与压缩矩阵冲突,同时保留位置敏感性。具体而言,RoPE 被应用于新生成的 Query 嵌入和 Key 嵌入。随后,这些经过 RoPE 处理的 Query 和 Key 嵌入与经过向上投影矩阵还原回高维特征空间的 Q 和 K 进行了 Concat 连接。
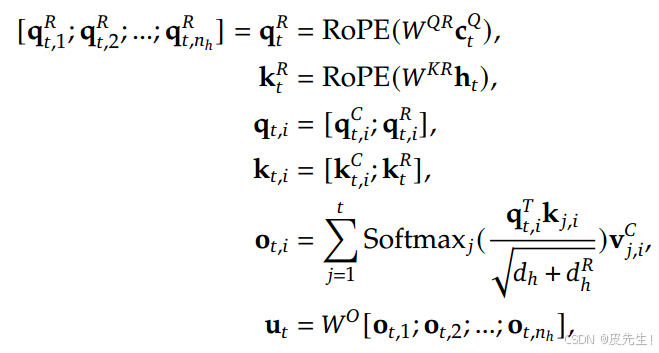
3. 权重矩阵吸收技巧
MLA还使用"权重矩阵吸收技巧",允许直接在压缩的KV缓存上进行计算,而无需显式地展开它,进一步提高了推理过程中的计算效率。
MLA性能比较
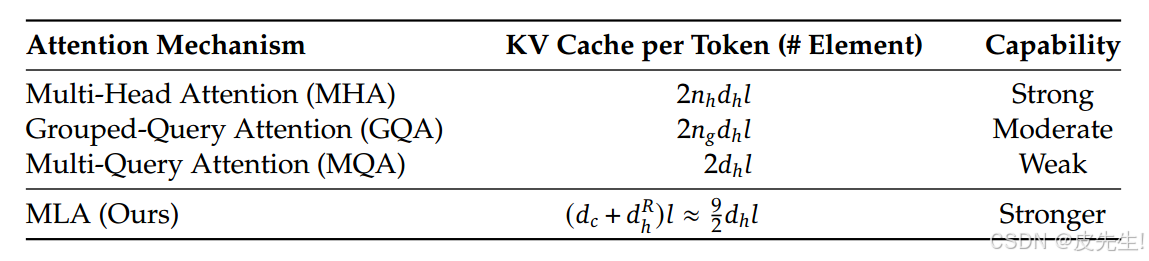
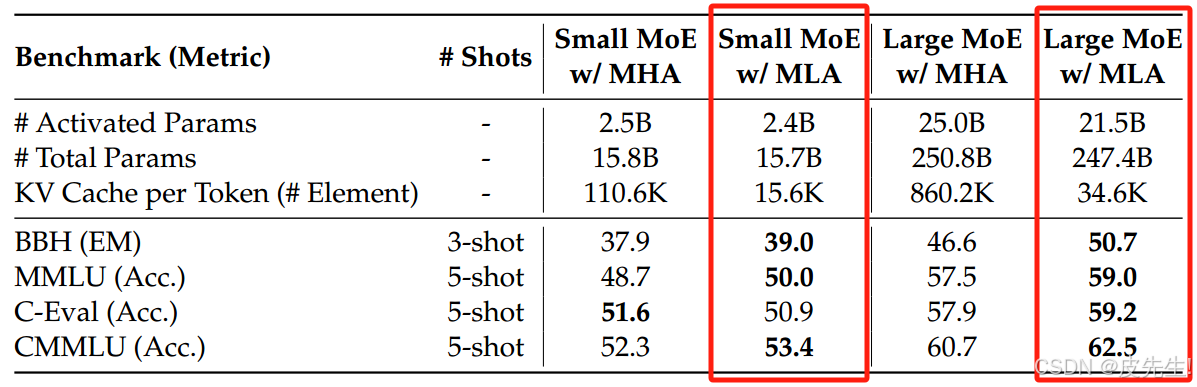
结论
DeepSeek的多头潜在注意力(MLA)机制是解决传统Transformer模型中KV缓存内存瓶颈的一项重要创新。通过在低维潜在空间中压缩键和值矩阵,MLA显著减少了内存占用,提高了推理速度和吞吐量,同时保持或甚至提升了模型性能。
参考文献
deepseek-v1:https://arxiv.org/pdf/2401.02954
deepseek-v2:https://arxiv.org/pdf/2405.04434
deepseek-v3:https://arxiv.org/pdf/2412.19437

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









