






计算机视觉一般三大任务,分别对应于:分类,检测,分割。检测的要求是需要算法告知我们图片中有哪些类别,分别对应于哪些位置,YOLO就是一种非常先进的目标检测算法,能解决上述问题。YOLO全称为You only look once。YOLO是进行如下操作的:
1)将图片构造成如下所示向量:


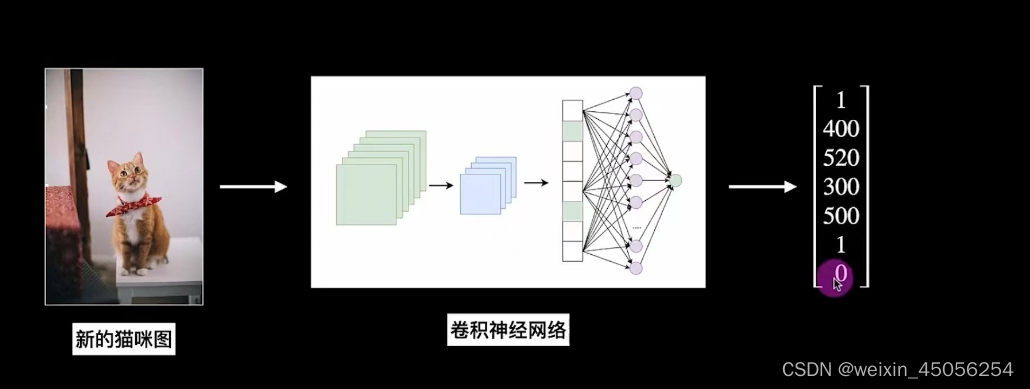
2)因为是有监督学习,所以图中7X1的列向量的所有参数是需要我们去补充的,具体操作是可以用Label软件给图片标数据——哪些是猫,哪些是狗给他用方框框起来加上猫狗备注标签,最后用于训练。最终你给一张图片,模型就能给你一组列向量,列向量会告诉你是猫还是狗等各种信息,如下图:
3)但对于一张图片中有多个猫狗怎么办呢,YOLO采用的方法是对图片进行分割,其中每一小块图片都要归一化,如下图所示:
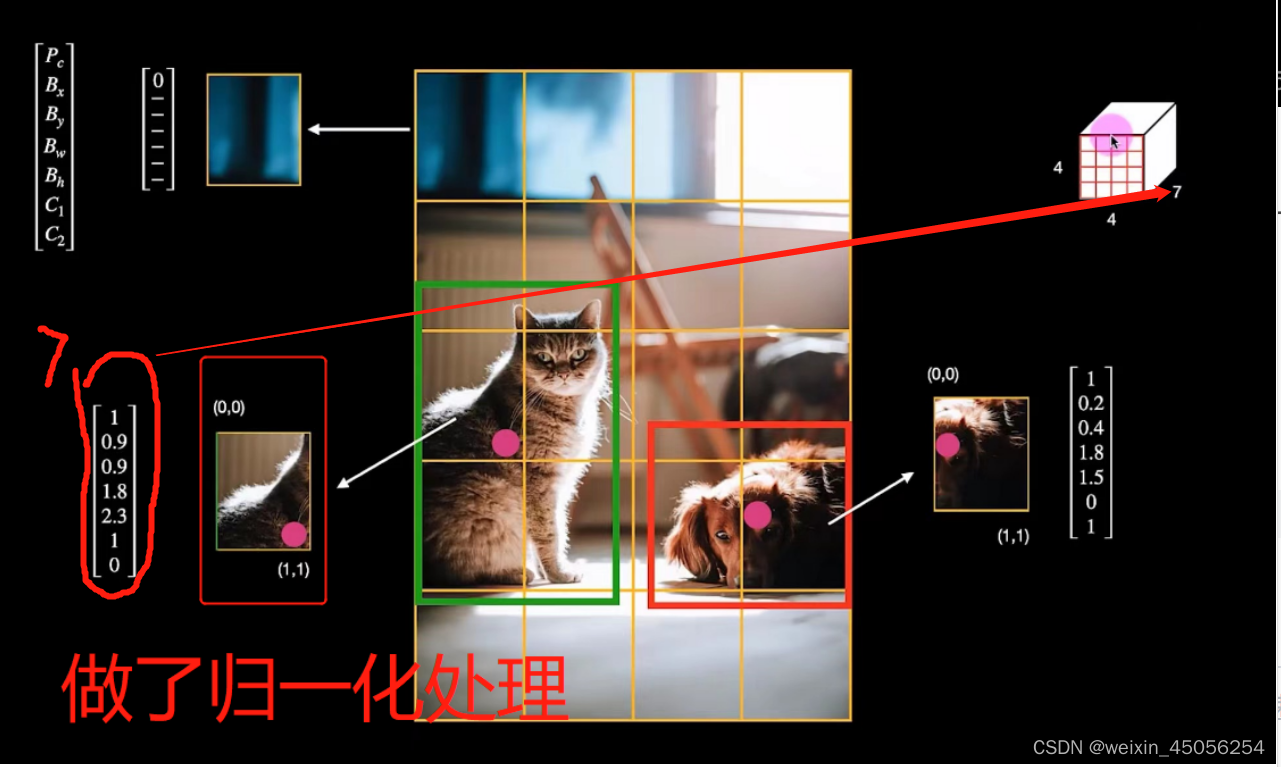

最终效果为:

4)一般情况下,为了得到较精确的效果,YOLO会对一个物体预测出多个边界框,这就需要选择最合适的边界框,如下图所示图片该如何做呢?
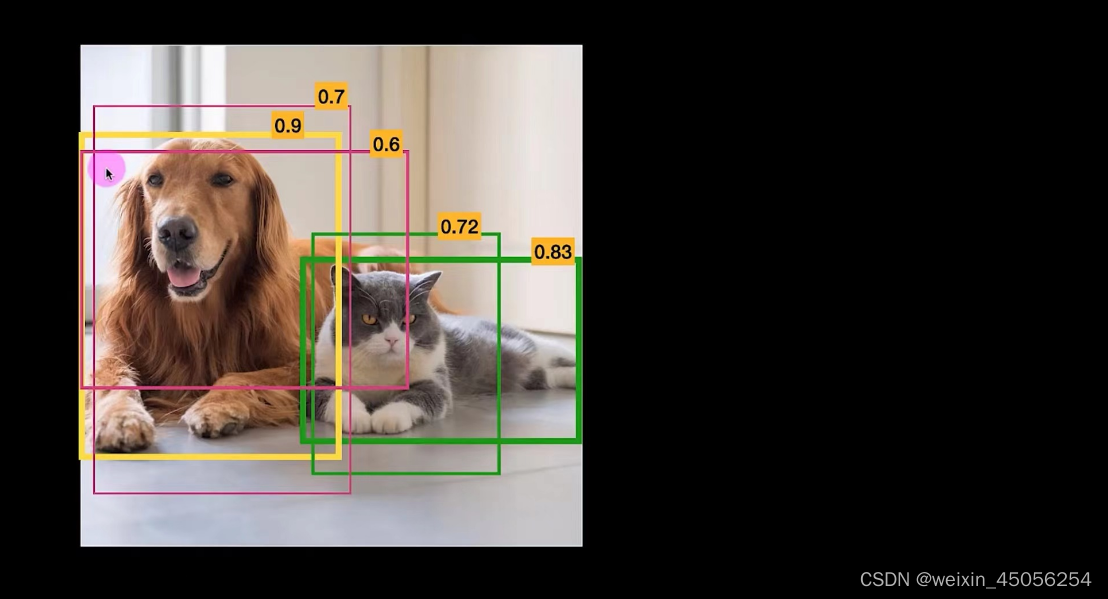
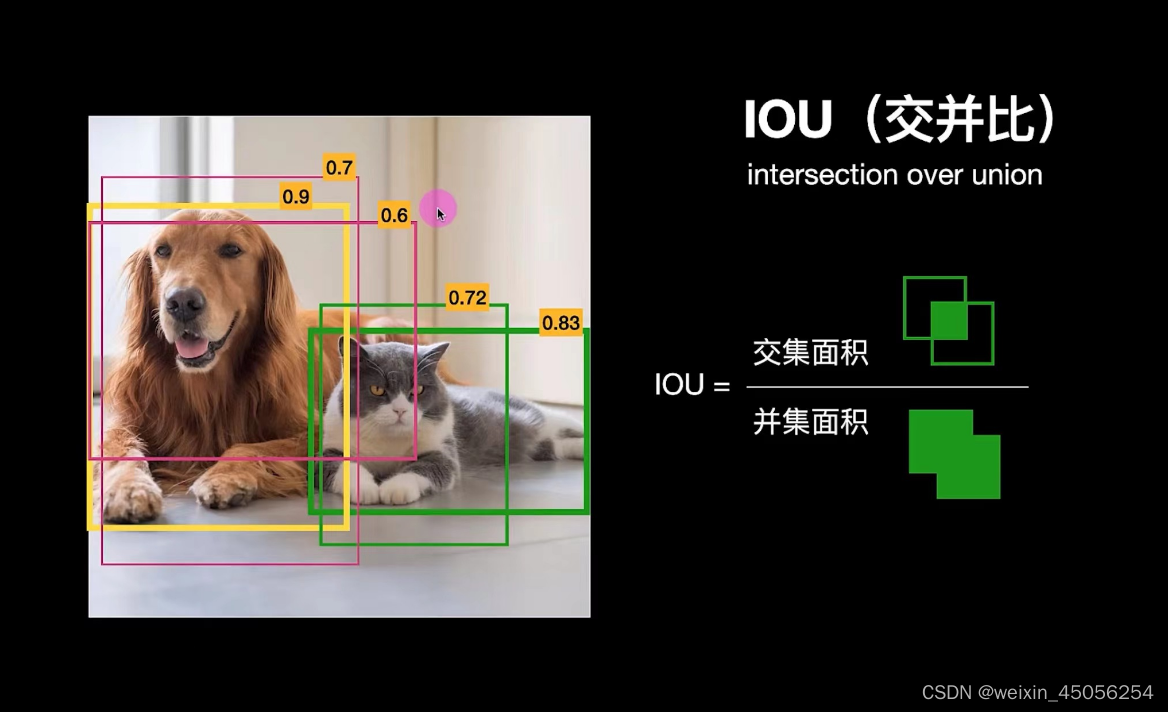
YOLO使用的是IOU交并比,如下图所示,IOU会有一个参考标准,IOU大于某个标准则这个边界框保留,否则丢弃,最终选择IOU最大的,这种方法称为NMS,即非极大值抑制。
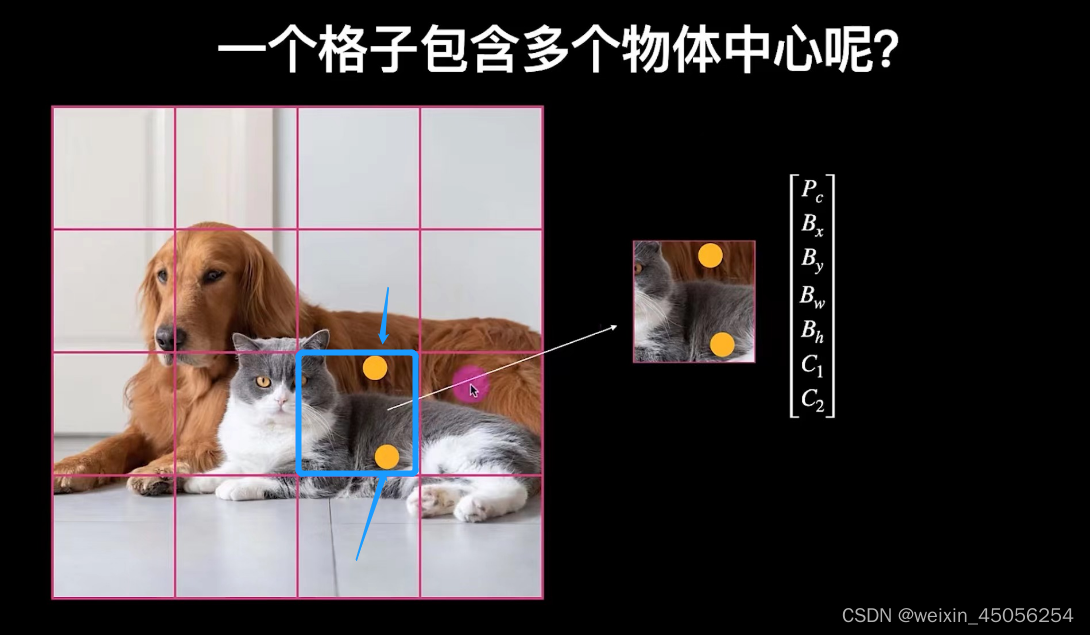
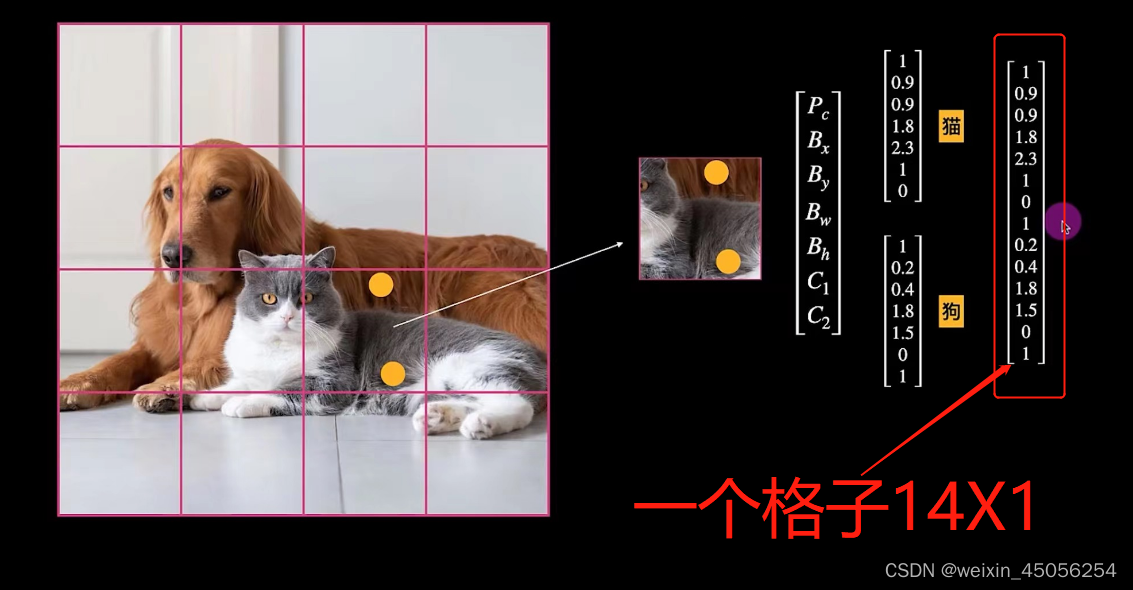
5)还有一种情况,当猫与狗的物体中心都落在一个格子里怎么办呢,如下图所示,做法是再增加一个向量,最终一个格子向量由7X1变为14X1,如下第二张图所示,实际上当格子分割很小时是很难遇到这种情况的。















 5430
5430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









