








 本文提出了一种迁移学习方法,将大量训练过的血腥麻将模型迁移到大众麻将领域,构建出适应大众麻将规则的弃牌决策模型。通过数据扩充和自博弈优化,模型在数据稀缺下表现出良好性能,助力作者团队在2021年大学生游戏大赛中取得二等奖。
本文提出了一种迁移学习方法,将大量训练过的血腥麻将模型迁移到大众麻将领域,构建出适应大众麻将规则的弃牌决策模型。通过数据扩充和自博弈优化,模型在数据稀缺下表现出良好性能,助力作者团队在2021年大学生游戏大赛中取得二等奖。

摘要:
本文提出了一种迁移学习来解决数据缺乏和模型构建困难的问题,典型代表是不完全信息领域中的大规模麻将。基于迁移学习的大众麻将弃牌模型的设计与实现。先前在大数据集上训练好的血麻将丢弃模型被迁移到相似域中的大规模麻将丢弃模型。在随后的模型优化中,使用了一种基于自玩的方法来改进大规模麻将丢弃模型。实验结果表明,基于迁移学习的大众麻将弃牌模型在数据较少的情况下表现良好,符合大众麻将弃牌规律。并在2021年全国大学生电脑游戏大赛大众麻将项目中获得二等奖。
keywords: ArtificialIntelligence Transfer learning Mahjong, Machine learning
关键词: 人工智能 ;迁移学习; 麻将; 机器学习; 大众麻将规则
1 INTRODUCTION
本文以大众麻将为典型代表,在只有少量数据的情况下,尝试通过转移学习将数据量大、训练良好的血腥麻将模型[6]转移到大众麻将领域,构建适用于大众麻将的丢弃模型。同时,为了继续提高该模型的准确性,使用自博弈方法对模型进行了优化。
2 大众麻将规则简介
大众麻将游戏由四名玩家组成,麻将分为三种花色:饼、条、万,共 108 张牌 [7]。其中,大众麻将常用术语解释如下。
- 墙:在游戏开始时抽出第一手牌后,剩余的牌就是牌墙。
- 抽牌:玩家从墙上抽一张牌。
- 弃牌:玩家从手中选择一张牌并弃牌。
- 吃:当你最后一个玩家丢弃的一张牌和你手中的两张牌组成三个连续的相同花色的牌时,你可以采取吃行动。
- 碰:如果另一个玩家丢弃了与你手中的两张牌相同的牌,你可以碰。
- 杠:有3种形式的金刚,分为明杠、暗杠和补杠。明杠是指另一位玩家丢弃的牌与您手中的三张牌相同。当你抽到与你手上三张牌相同的牌时,你可以采取暗杠动作。如果你画的牌与你已经有的牌相同,你可以补杠。
- 听:当手牌还差一格时,玩家可以选择是否听牌。听完后,虽然可以直接获得分数奖励,但是之后不能换手,即以后抽到的牌都被弃掉,直到游戏中的获胜牌出现,才可以取胜。
- Meld:在游戏中,吃、碰、杠和补杠动作的牌组合。
3 大众麻将决策系统的总体设计
由于大众麻将的规则,吃、碰、孔、听操作可以直接获得奖励。因此,这部分可以基于知识规则来实现。而弃牌的好坏决定了后续的胜负。因此本文的研究重点是麻将弃牌决策。在之前的工作 [6] 中,麻将丢弃决策模型经过训练并表现良好。因此,本文使用血腥麻将决策模型进行迁移学习。
3.1 大众麻将和血腥麻将规则的异同
大众麻将和血腥麻将相似,总体规则相似但也有一些不同,两者的主要异同如下。
相似之处:都是108张牌,只有饼条万三种花色。碰杠的规则是一样的。获胜的规则也是相似的,只要特定的牌符合获胜规则。
区别:大众麻将没有换三张牌的规则,也没有缺一套就赢的要求。不过大众麻将增加了两个动作:吃和听。大众麻将的吃、碰、杠、听动作都是直接奖励。游戏在一个玩家赢的时候就结束了,不存在一个玩家赢了其他人继续玩的情况。
总之,与血腥麻将相比,大众麻将的规则更简单,可以看作是血腥麻将中的一个阶段,从而为使用迁移学习提供了良好的条件。
3.2 大众麻将决策系统的总体设计理念
迁移学习大众麻将弃牌模型设计的整体概念如图1所示。它由以下四个主要部分组成。
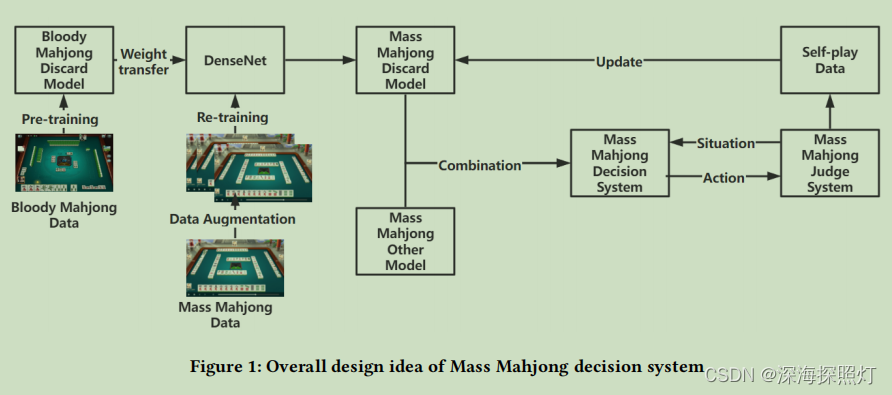
1.预训练。一般选择在类似任务上能得到较好训练的模型进行预训练。根据大众麻将的特点,选取与大众麻将相似的血腥麻将弃牌模型作为源模型,并在血腥麻将数据集上对其进行预训练。
- 权重转移。这一步主要使用训练好的模型权重,然后在一个新的任务中使用这些权重作为初始权重,简单来说就是将训练好的模型的参数转移到新的模型中,帮助训练新的模型。本文对预先训练好的血腥麻将弃牌模型进行权值转移。
- 重新训练。根据当前任务的特点,原始模型的某些结构被固定或改变,以使模型适应新的任务。在本文中,我们首先从模型输入中去除血腥麻将的一些独特特征,如换三张牌和丢失花色,并改变模型的输入结构,然后使用数据扩充,在扩充较少的大规模麻将数据后,使用转移权重重新训练大规模麻将,以建立基于转移学习的大规模麻将丢弃模型。
- 模型优化。在对大众麻将弃牌模型进行训练后,通过微调对模型进行优化。本文将其他麻将决策模型与麻将弃牌模型相结合,形成麻将决策系统。根据大众麻将的规则,建立大众麻将裁判系统,与大众麻将决策系统进行自我博弈,利用自我博弈产生的数据更新大众麻将弃牌模型,达到模型微调优化的效果。
4大众麻将决策系统的设计与实现
4.1大众麻将弃牌模型的设计与实现
在以前的工作中,由于大量的血腥麻将弃牌数据,构建了一个血腥麻将弃牌模型用于预训练,作为迁移学习的源模型。对于参考文献[8-10]中提出的方法的模型输入数据表示,考虑数据之间的完整性和相关性来分割游戏场景,并且使用基于人类经验的知识来提取当前情形中的已知信息。因为在大规模麻将中没有诸如改变三张牌的特征,所以当构建大规模麻将丢弃模型时,这些特征被消除。在本文中,我们选择3*9的特征平面来表示这种情况,其中3行表示瓷砖的花色,9列表示序列1到9的9个类别。对于其他已知信息,包括:上一个、下一个、相对的玩家已经丢弃了牌,并且其他特征由该特征平面表示。具体的数据表示如表1所示。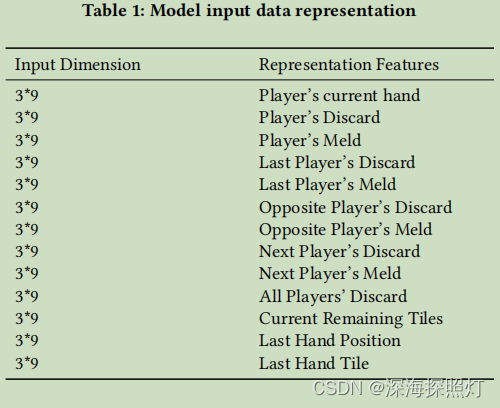
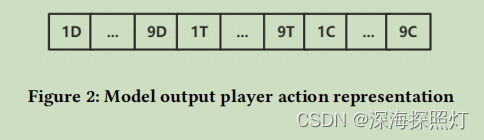
迁移学习模型的输出将动作视为多分类,即27种图块动作,如下图2所示。
在之前的工作中,血色麻将在弃牌时不仅考虑了当前的情况信息,还考虑了过去的牌信息。而DenseNet [11]网络建立了不同层之间的连接关系,所以选择DenseNet网络用于麻将弃牌决策。由于是迁移学习且大众麻将和血腥麻将牌类型相同,弃牌时需要考虑之前的信息,只需要修改模型的输入层。模型输出是27种瓷砖类型的概率分布。
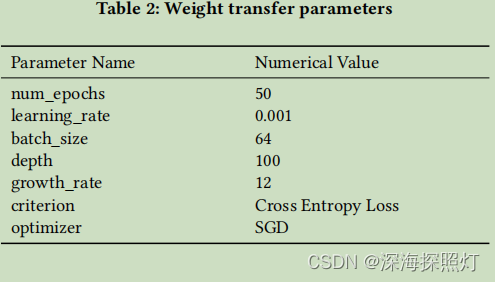
本文利用血腥麻将数据集进行预训练来训练血腥麻将弃牌模型,经过一系列的参数化工作,最终血腥麻将弃牌模型在测试集上的准确率可以达到91.6%。接下来,进行权重传递,将血腥麻将弃牌模型的参数传递给大众麻将弃牌模型,具体参数如下表2所示。
损失函数被选择为交叉熵损失,其由下面的等式1)表示。
c
=
−
Σ
x
[
y
ln
a
+
(
1
−
y
)
ln
a
]
n
\frac{c=-\Sigma_{x}[y \ln a+(1-y) \ln a]}{n}
nc=−Σx[ylna+(1−y)lna]
在等式1)中,y表示期望输出,即标签中对应于分类的位置,a表示神经元的实际输出,即神经网络预测的多分类标签的位置,x表示样本,n表示样本总数。优化目标是最小化损失,当模型的实际输出接近真实结果时,c的值逐渐减小。
通过使用数据扩充后的大规模麻将弃牌数据和权重转移后的参数进行再训练,获得大规模麻将弃牌模型。具体算法如下面算法1所示。

4.2大众麻将其他行动决策模型的设计与实现
大众麻将有吃、弃、碰、杠、听等动作,这些动作组合在一起形成一个完整的大众麻将决策系统。丢弃模型是通过迁移学习训练的模型,而其他四个模型是基于规则的模型,这是由于采取行动时的某些限制以及可以收集的少量数据。本文中列出了一些规则,算法如下面的表3所示。以上吃、弃、碰、杠、听的模型组合成一个完整的大众麻将决策系统。

4.3大众麻将模型的优化设计与实现
在构建大众麻将决策系统后,通过自对弈产生数据来优化弃牌模型,使大众麻将弃牌模型能够更好地适应大众麻将的规则。自对弈模型优化算法的训练过程如算法2所示。

5结果和分析
5.1数据处理
由于原始数据量较小,本文在数据处理中没有进行进一步的数据清洗。数据处理主要是对原始数据进行游戏情境的语义分割和特征提取。本文使用的大众麻将数据来源于2020年全国大学生电脑游戏大众麻将大赛的比赛记录。原始数据是json格式的日志,信息包括:一个人的手牌,一个人的meld,一个人的座位号,以及到目前为止的弃牌记录。原始数据格式如下图3所示。

为了提高模型的泛化能力,对处理后的数据进行数据扩充。点、竹、字这三套牌的等级相同,数字一到九在结构上是对称的。参考AlphaZero的数据扩充方法,可以旋转三套瓷砖,对数字一到九进行对称处理,共有48种情况,即一种情况下有47个其他位置与当前位置相当。
5.2迁移学习模型实验
经过数据处理后,将这些标定数据进行分割,共得到90万个标定数据。随机选择80%的数据作为训练集,20%作为测试集。该模型由pytorch编写,使用权重转移后的参数,并在GEFORCE RTX 2080型的单个GPU上进行训练。随着训练次数的增加,获得的测试集如图4所示。
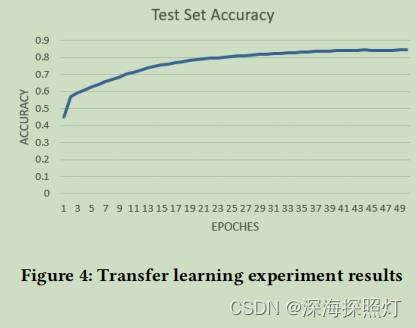
虽然在测试集上达到了84%的准确率。但由于数据质量不高,模型还需要后续的自玩游戏进行优化和完善。
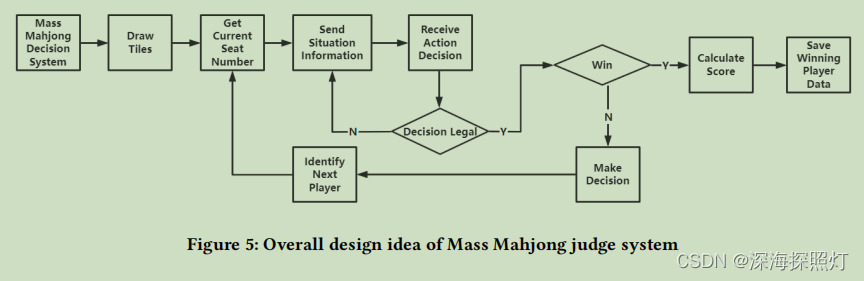
为了给后续的自博弈提供条件,本文构建了大众麻将裁判系统。大众麻将裁判系统可以模拟大众麻将游戏的环境,并负责与大众麻将决策系统进行交互,共同构成一个完整的大众麻将游戏。大众麻将裁判系统主要包括抽牌、判赢、计算分数、判断下一个决定是否合法等功能。总体设计如下图5所示。
在本文中,我们使用自玩游戏来产生数据,然后使用获胜玩家的数据来训练模型进行优化。用十个过程进行训练,一个训练环节每局250次,每局40回合,学习率0.001。在使用JJWorld的测试软件(官方支持的全国比赛的测试软件)时,游戏被测试了30轮,随机安排了4名玩家。未优化的AI是名为TEST 2和TEST 4的玩家,优化的AI是TEST 1和TEST 3。测试3的训练时间比测试1长,最终结果如表4所示。
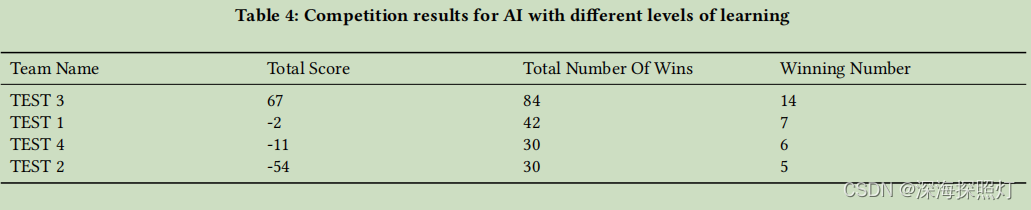
从表4中可以看出,与优化模型相比,未优化模型获胜次数更少,得分更低。而优化后的模型,赢的次数更多,得分更高,而模型训练的时间越长,模型优化的越好,模型越能学习到大众麻将的规则。
5.3实际比赛结果
本文设计的大众麻将决策系统参加了2021年全国大学生电脑游戏大赛。本文设计的大众麻将代理在比赛中获得了二等奖。当彼此对战时,一些结果显示在下面的表5中。
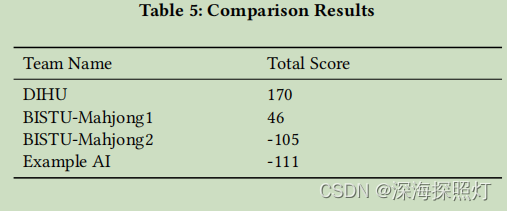
其中,基于深度学习模型的BISTU-Mahjong1是去年的亚军团队,基于规则的BISTU-Mahjong2是去年的参赛团队,去年获得了第5名。本文提出的基于迁移学习的大众麻将决策系统的表现优于以上两者,表明本文提出的算法具有一定的效果。
在与其他玩家的AI对战时,模型表现一般,对此的原因分析如下:一方面,模型训练时间不够;另一方面,Eat、Pong和Kong模型是基于规则实现的,它们与Discard模型没有很好的协调。最后,本文提出的基于迁移学习的大众麻将决策系统获得了二等奖。
6 结论
为了解决相邻麻将域规则差异和数据同时缺失的问题,利用迁移学习去除迁移源模型特有的特征,然后将模型迁移到新的麻将中,最后通过构建自玩系统进一步优化模型。本文将热血麻将模式转入大众麻将模式,最终获得2021年全国大学生电脑游戏大众麻将大赛二等奖。由于本文使用的部分模型是基于规则的模型,在以后的工作中,有可能对于Eat、Pong、Kong和Listen模型,可以训练深度学习模型来代替目前基于规则的模型,使各个模型能够有很好的协调效果,提高模型的整体决策能力。
参考文献
[1] Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. nature, 2016, 529(7587): 484-489.
[2] Zha D, Xie J, Ma W, et al. DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning[J]. arXiv preprint arXiv:2106.06135, 2021.
[3] Silver D, Hubert T, Schrittwieser J, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm[J]. arXiv preprint arXiv:1712.01815, 2017.
[4] Van der Kleij A A J. Monte Carlo tree search and opponent modeling through player clustering in no-limit Texas hold’em poker[J]. University of Groningen, The Netherlands, 2010.
[5] Li J, Koyamada S, Ye Q, et al. Suphx: Mastering Mahjong with Deep Reinforcement Learning[J]. arXiv preprint arXiv:2003.13590, 2020.
[6] Gao S, Li S. Bloody Mahjong playing strategy based on the integration of deep learning and XGBoost[J]. CAAI Transactions on Intelligence Technology, 2021.
[7] Qingyue Wang. Game of Mahjong [M]. Chengdu: Shurong Chess Publishing House.2003.
[8] Gao S, Okuya F, Kawahara Y, et al. Supervised Learning of Imperfect Information Data in the Game of Mahjong via Deep Convolutional Neural Networks[J]. Information Processing Society of Japan, 2018.[9] Gao S, Okuya F, Kawahara Y, et al. Building a Computer Mahjong Player via Deep Convolutional Neural Networks[J]. arXiv preprint arXiv:1906.02146, 2019.
[10] Wang M, Yan T, Luo M, et al. A novel deep residual network-based incomplete information competition strategy for four-players Mahjong games[J]. Multimedia Tools and Applications, 2019: 1-25.
[11] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4700-4708
![[Mass Mahjong Decision System Based on Transfer Learning.pdf]]

















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









