






源码:
# 初始化序列
sequence = [(torch.zeros(1, 1, 256, 256).float()/255.0) for _ in range(5)]
for i in range(num_sample):
dict_sample_data = dataset_test[i]
filename_sample = dict_sample_data["meta_info"]["filename"]
input_tsr = torch.unsqueeze(dict_sample_data['input'], dim=0).to(device)
sequence_tensor = torch.stack(sequence, dim=1).to(device) # 1,5,256,256
# sequence_tensor = model_lstm(sequence_tensor) # 1,5,1,256,256
sequence_tensor = sequence_tensor[:, 4, :, :, :] # 1,1,256,256
pred_tsr = model(input_tsr, sequence_tensor) # 1,1,256,256
# 更新序列块
pred_tsr = pred_tsr.to('cpu')
sequence.pop(0)
sequence.append(pred_tsr)
# sequence.append((torch.zeros(1, 1, 256, 256).float()/255.0))目的是建立一个长度为5的缓冲区,推理出来的结果加入到缓冲区里面,并把最缓冲区里面的第一个删除。于是用以下三行关键代码来完成:
# 初始化序列
sequence = [(torch.zeros(1, 1, 256, 256).float()/255.0) for _ in range(5)]
...
...
# 更新序列块
sequence.pop(0)
sequence.append(pred_tsr) # pred_tsr是(1,1,256,256)的torch.tensor但是遇到问题:
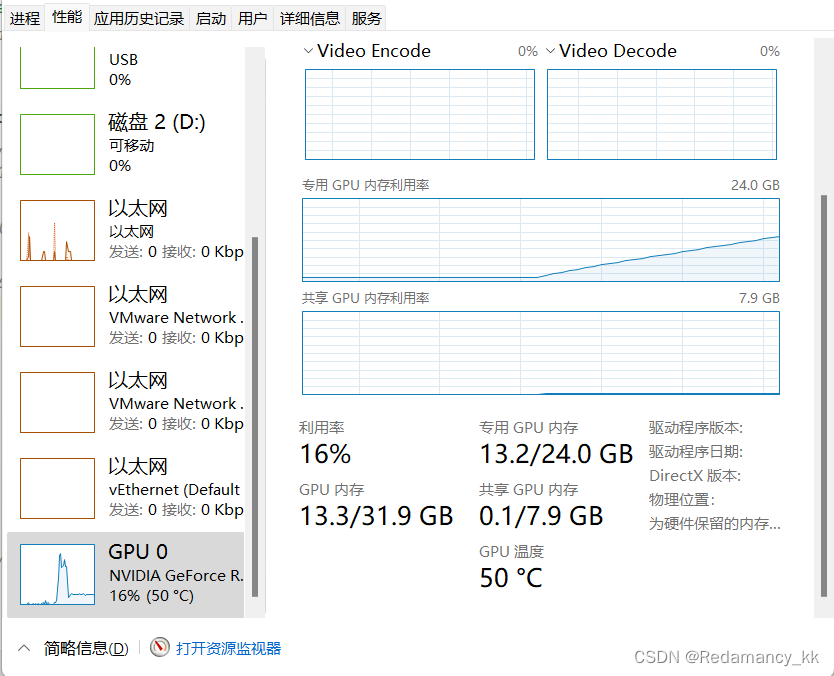
在推理过程中(对每张图片进行推理),显存呈现线性上升,说明有资源没有被合理释放,反复debug发现问题出现在了这句代码: sequence.append(pred_tsr)
我把pred_tsr换成其他的相同shape的tensor完全没问题,说明把pred_tsr加入sequence中有问题,就算每个循环加入:torch.cuda.empty_cache(),问题依然存在。
说明此时的pred_tsr还在被使用。
又想到,可能是把pred_tsr加入列表中,并不是拷贝了一份副本,而是把pred_tsr原数据加入了列表,而列表又是在循环外定义,因此出现了泄露。
因此代码改为:
sequence.pop(0)
pred_squence = pred_tsr.detach().clone() # 手动拷贝一份加入列表,便于原pred_tsr的释放
sequence.append(pred_squence)以下的正常运行的显存情况
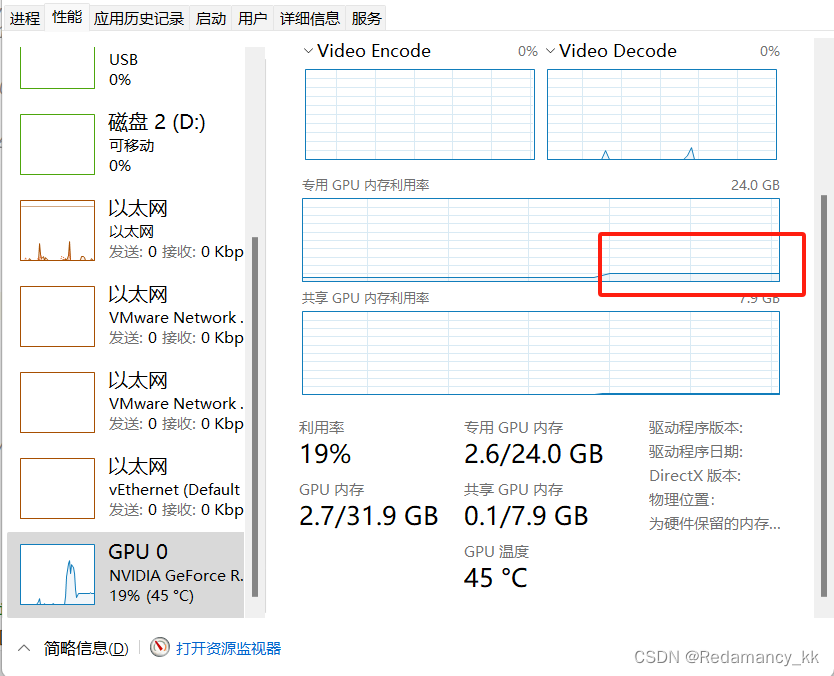
可是,我明明把pred_tsr放到cpu上了,怎么是显存泄露呢















 1588
1588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









