







总目录:
1. 数据预处理
2. limma包进行差异分析
3. edgeR包进行差异分析
4. DESeq2包进行差异分析
5. 三大R包比较
1.输入数据比较
- edgeR: 原始的count矩阵,支持单个样品和重复样品
- DESeq2: 原始的count矩阵(htseq-count),只支持重复样品
- limma: 原始的count矩阵(需自己标准化,一定要log化)、经过标准化的矩阵或芯片数据,只支持重复样品
注: 无重复RNAseq样本推荐使用Gfold软件进行分析
2.性能比较
- 导入数据
load('edgeR_diff.Rdata')
edgeR<-diff_signif
load('limma_diff.Rdata')
limma<-diff_signif
oad('deseq2_diff.Rdata')
deseq2<-diff_signif
- 差异基因数目比较
dim(deseq2)
dim(limma)
dim(edgeR)

edgeR: 得到基因数目最多
DESeq2: 得到基因数目适中
limma: 得到基因数目最少
- 差异基因一致性比较
library('VennDiagram')
data=list(DEseq2=rownames(deseq2),edgeR=rownames(edgeR),limma=rownames(limma))
ve<-venn.diagram(data,filename = NULL,fill=c('red','yellow','blue'))
grid.draw(ve)
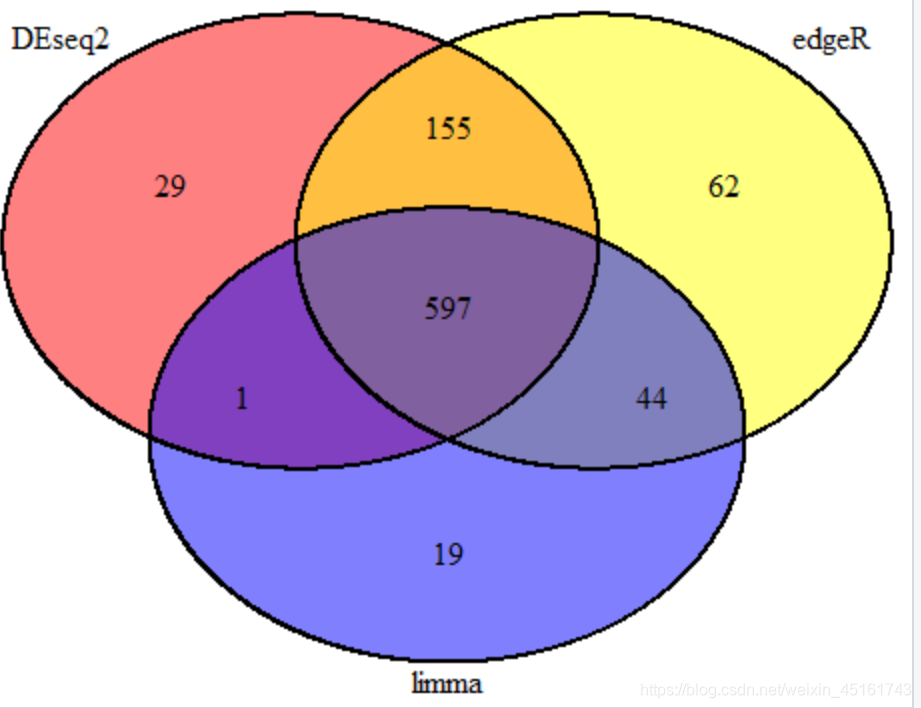
结论:
- 三个R包得到的差异基因数目差别不是很大
- edgeR包和DEseq2包得到的差异基因更加相似
- limma包得到的差异基因准确率最高(其他两个R包不能得到的差异基因数量最少,只占总数的2%),但假阴性高(实际差异结果不差异)
- edgeR包能得到更多的差异基因,但假阳性高(实际不差异结果差异)
- 运行速度比较
计算从导入数据(16610基因,8样本)到差异分析结束所需要的时间
- limma: 3.944069 secs
- edgeR: 5.882637 secs
- DEseq2: 10.55145 secs
由此可见limma分析速度最快,DEseq2分析速度最慢



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









