










一、论文信息
1 论文标题
LoRAHub:Efficient Cross-Task Generalization via Dynamic LoRA Composition
2 发表刊物
NIPS2023_WorkShop
3 作者团队
Sea AI Lab, Singapore
4 关键词
LLMs、LoRA
二、文章结构
1 引言
1.1 研究动机
Investigation into the inherent modularity and composability of LoRA modules. To verify is it feasbile to compose LoRA modules for efficiently generalizing towards unseen tasks?
1.2 任务背景
Intro-P1:
LLM->issues->LoRA->efficiency->inherent modularity and composability
Intro-P2:
generalization of LoRA->automatic assembling without human design->few-shot->auto orchestrate->LoRAHub、LoRAHub Learning
Intro-P3:
Experiments:Flan-T5->BBH benchmark->与few-shot ICL相比效果相当->减少了推理时间->gradient free减少计算开销
Intro-P4:
can work on CPU-only machine->LoRA modules can share, access, apply and reuse
1.3 问题陈述
LLM
- pre-trained Transformer / have been fine-tuned with instruction-following datasets
- encoder-decoder / decoder-only
Cross-Task Generalization
- zero-shot learing
- few-shot learing
当新任务的含标签数据太少时,直接fine-tune效率和效果都不能保证。理想的方式是直接让模型能够基于这少部分数据直接适应新任务场景。
LoRA Tuning
traditional LoRA methods primarily concentrate on training and testing within the same tasks, rather than venturing into few-shot cross-task generalization.
2 创新方法
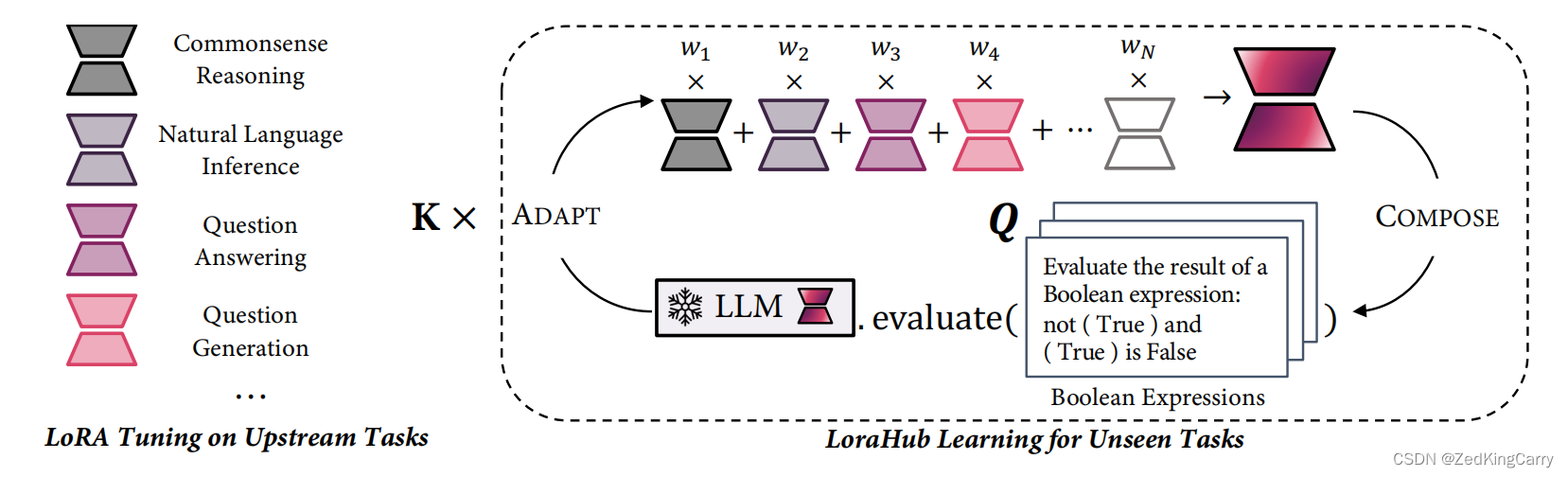
LoraHub learning
- Compose Stage:
existing LoRA modules are integrated into one unified module, employing a set of weights, denoted as w w w, as coefficients. 【加权合并】 - Adapt Stage:
the amalgamated (合并的) LoRA module is evaluated on a few examples from the unseen task.
Subsequently, a gradient-free algorithm is applied to refine w. After executing K iterations, a highly adapted LoRA module is produced, which can be incorporated with the LLM to perform the intended task.
Gradient-free methodology
- Shiwa:CMA-ES (Covariance Matrix Adaptive Evolution Strategies)
- For our case, we deploy this algorithm to shape the search space of w, and eventually select the best weights based on their performance on the few-shot examples from the unseen task.
其它
无














 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









