




 HuBERT模型提出了一种解决语音表示学习中挑战的新方法,通过聚类为BERT损失提供标签,并利用mask预测学习声学和语言模型。模型在多个基准上展现出与Wav2vec2.0相当甚至更优的效果。通过K-Means等聚类方法生成目标,使用BERT架构进行mask预测,并通过多聚类和迭代细化提升目标质量。预训练后,模型使用CTC loss进行ASR微调。
HuBERT模型提出了一种解决语音表示学习中挑战的新方法,通过聚类为BERT损失提供标签,并利用mask预测学习声学和语言模型。模型在多个基准上展现出与Wav2vec2.0相当甚至更优的效果。通过K-Means等聚类方法生成目标,使用BERT架构进行mask预测,并通过多聚类和迭代细化提升目标质量。预训练后,模型使用CTC loss进行ASR微调。
摘要
语言表示学习的自监督方法受到三个独特问题的挑战:
- 每个输入话语中都有多个声音单元
- 在预训练阶段,没有输入声音单元的词典(没有单独的字符或离散的单词输入)
- 声音单元具有可变长度,没有明确的分段
为了解决这些问题,提出了hidden-unit BERT(HuBERT)。
HuBERT使用聚类的方式为BERT中使用的loss提供标签,然后再通过类似BERT的mask式loss让模型在连续的语音数据中学习到数据中的声学和语言模型。实验证明HuBERT在各种benchmark上都取得了和目前最好的Wav2vec 2.0类似或是更好的效果。
具体而言,BERT模型消耗masked的连续语音特征,以预测预定的集群分配。预测损失仅应用于masked的区域,迫使模型学习未masked的输入的高水平表示,以正确地推断masked的目标。从直觉上讲,HuBERT模型被迫从连续的输入中学习声学和语言模型。首先,该模型需要将未masked的输入建模为有意义的连续潜在表示,该代表映射到经典的声学建模问题。其次,为了减少预测错误,该模型需要捕获学习表示之间的远程时间关系。激发这项工作的一个关键见解是目标一致性的重要性,而不仅仅是其正确性,这使模型能够专注于建模输入数据的顺序结构。
model
A.学习HuBERT的隐藏单元
通过文本和语音对训练的声学模型通过半监督学习中的强制对齐为每个框架提供伪形式标签。相反,自监督的表示学习设置可以访问仅语音数据。然而,简单的离散可变量模型,例如K-均值和高斯混合模型(GMMs)推断隐藏的单元与基础声学单元表现出非平凡相关性。
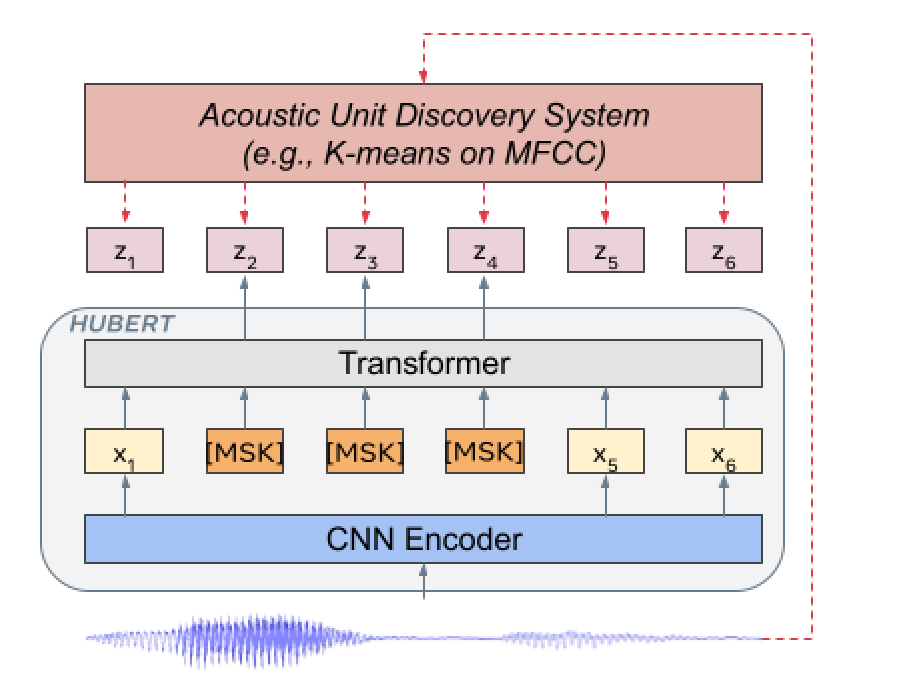
HuBERT方法预测了由K-Means群集的一个或多个迭代生成的masked的帧(y2,y3,y4)的隐藏群集分配。
受此启发,我们建议使用声学单元发现模型提供框架级目标。
令X表示T帧的语音话语X=[x1,...,xT]X = [x_{1},...,x_{T}]X=[x1,...,xT]
隐藏单元用h(X)=Z=[z1,...,zT]h(X)=Z=[z_{1},...,z_{T}]h(X)=Z=[z1,...,zT],其中zt∈[C]z_{t}∈[C]zt∈[C]是一个C分类变量,hhh是一个聚类模型,例如K-means。
B.通过masked预测来表示学习
令M⊂[T]M⊂[T]M⊂[T]表示X中被mask的索引
X~=r(X,M)\tilde{X}=r(X,M)X~=r(X,M)表示X被mask后的序列,其中xt,t∈Mx_{t},t∈Mxt,t∈M被mask embedding x~\tilde{x}x~代替。
掩码预测模型fff把X~\tilde{X}X~作为输入,预测每个时间段pf(⋅∣X~,t)p_{f}(·|\tilde{X},t)pf(⋅∣X~,t)的目标上的分布。
掩码预测有两个问题:如何掩盖和在哪里应用预测损失。
关于第一个问题,采用SpanBERT和wav2vec 2.0相同的策略用于掩码:p%的时间步被随机选择作为开始序号,从各个序号后面数lll个steps被mask。
为了解决第二个问题,分别在masked和unmasked的时间步计算交叉损失Lm,LuL_{m},L_{u}Lm,Lu
LmL_{m}Lm定义如下:
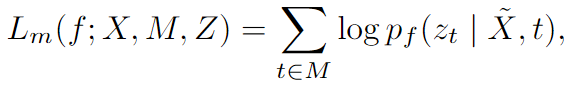
LuL_{u}Lu形式和LmL_{m}Lm相同,只是t∉Mt\notin Mt∈/M。最后的损失是两个损失的带权和:L=αLm+(1−α)LuL=\alpha L_{m}+(1-\alpha)L_{u}L=αLm+(1−α)Lu。
在极端情况当α=0\alpha=0α=0,损失是根据未掩码的时间步计算的,这类似于混合语音识别系统中的声学建模。在我们的设置,这限制了学习过程以模仿聚类模型。
当α=1\alpha=1α=1,损失仅在模型必须预测对应于从上下文的看不见的框架的目标的掩蔽时间步中计算出来,类似于语言模型。它迫使模型学习未掩盖段的声学表示和语音数据的远程时间结构。我们假设具有α= 1的设置对群集目标的质量更具弹性,这在我们的实验中得到了证明。
C.通过多个聚类学习
提高目标质量的一个简单想法是使用多个聚类模型。虽然单独的聚类模型可能表现的糟糕,但多个聚类可以提供综合信息以促进表示学习。例如,具有不同尺寸的码本的K-均值模型的多个聚类模型可以创建(从元音/辅音到子音素)不同粒度的目标。
为了扩展提出的框架,让Z(k)Z^{(k)}Z(k)为第k个聚类模型生成的目标序列。现在可以重写LmL_{m}Lm如下:
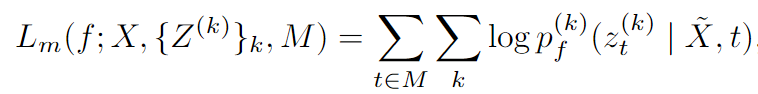
未掩码的损失LuL_{u}Lu与上式相似。这类似于多任务学习,但是任务是无监督聚类创建的。
另外,ensembling是有趣的,因为它可以与量化(一个特征空间被划分为多个子空间,每个子空间分别量化)一块使用。PQ允许有效的欧几里得距离量化,例如高维特征的K均值和异质特征,它们的比例在子空间之间显着差异。在这种情况下,目标空间的理论尺寸是所有码本尺寸的量化。
D.集群分配的迭代精炼
除了使用多个聚类外,改进表示的另一个方向是完善整个学习过程中的聚类分配。由于我们期望与原始声学特征(如MFCC)相比,预训练的模型可以提供更好的表示形式,因此我们可以通过训练学到的潜在表示的离散潜在模型来创建新一代的集群。然后,学习过程与新的发现单元进行。
E.执行
卷积波形编码器以20ms的帧率生成特征序列,以在16kHz处采样音频(CNN编码器下采样系数为320x)。
然后如B节所说,随机掩盖编码了的音频特征。
BERT编码器输入掩码序列,输出特征序列[o1,...,oT][o_{1},...,o_{T}][o1,...,oT]。
码词的分布式参数化为:
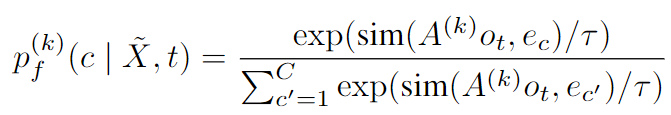
AAA是预测矩阵,ece_{c}ec是码词ccc的embedding,sim(⋅,⋅)sim(·,·)sim(⋅,⋅)计算两个向量之间的余弦相似性,τττ将logit缩放为0.1。当使用群集集合时,为每个聚类模型kkk应用一个预测矩阵A(k)A^{(k)}A(k)。
在HuBERT预训练之后,我们使用CTC loss对整个模型权重的ASR微调,卷积音频编码器除外,卷积音频编码器保持不变。预测层被移除,用随机初始化的softmax层代替。CTC目标词汇包括26个英语字符,一个空格token,逗号和特殊的CTC空白符号。

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









