







 超级会员免费看
超级会员免费看
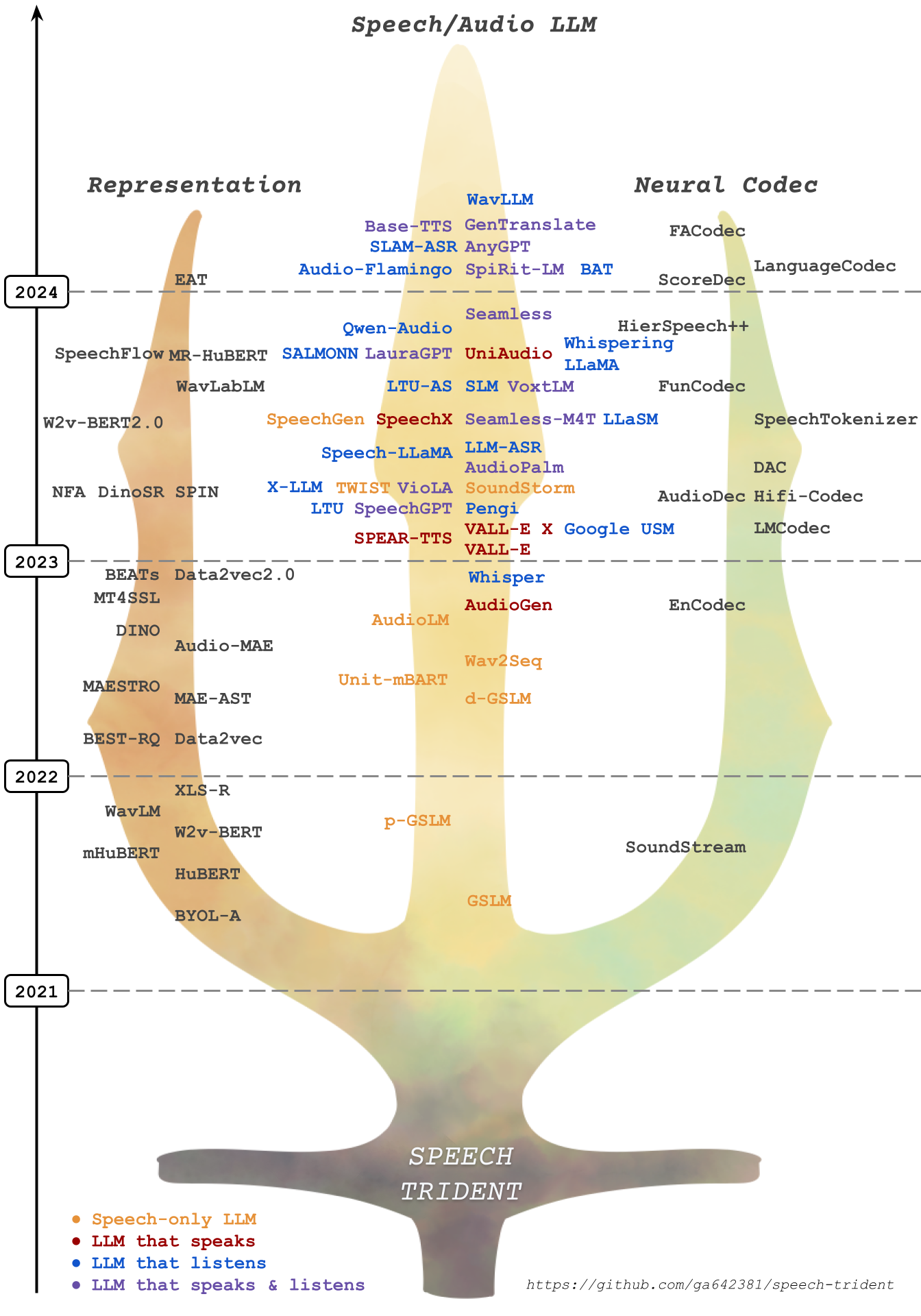
In this repository, we survey three crucial areas: (1) representation learning, (2) neural codec, and (3) language models that contribute to speech/audio large language models.
1.⚡ Speech Representation Models: These models focus on learning structural speech representations, which can then be quantized into discrete speech tokens, often refer to semantic tokens.
2.⚡ Speech Neural Codec Models: These models are designed to learn speech and audio discrete tokens, often referred to as acoustic tokens, while maintaining reconstruction ability and low bitrate.
3.⚡ Speech Large Language Models: These models are trained on top of speech and acoustic tokens in a language modeling approach. They demonstrate proficiency in tasks on

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 2969
2969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









