






 本文介绍了神经元参数初始化的重要性和不同方法,如正态分布(解决对称现象)、均匀分布、Xavier初始化(适合tanh)和Kaiming初始化(针对ReLU),这些方法旨在控制梯度,提高神经网络训练稳定性。
本文介绍了神经元参数初始化的重要性和不同方法,如正态分布(解决对称现象)、均匀分布、Xavier初始化(适合tanh)和Kaiming初始化(针对ReLU),这些方法旨在控制梯度,提高神经网络训练稳定性。
1.引言
给定一个神经元,假设输入有三个,为了方便讨论,我们忽略截距b。

参数w的值如何选择?
都等于0?将会导致对称现象。
怎么解决:需要在参数初始化的时候增加一些随机性。
二、正态分布初始化
例如在均值为0,方差为1的正态分布随机采样。Var为求方差。
为了简化后面的理解:假设x1,x2,x3等于1。此时:y=w1+w2+w3
Var(y)=Var(w1)+Var(w2)+Var(w3)=3
意味着输入经过神经元之后输出的离散程度为根号下3倍。如果神经元不只三个输入,n个输入离散程度将会为根号n倍。
在不使用激活函数的情况下,放大的y值就会被累积在反向传播的过程里,造成梯度爆炸。如果使用tanh函数作为激活函数,可能会因为y值过大或过小造成梯度消失。
为了让神经网络训练过程稳定下来,我们需要让y的方差落在一个可控的范围内,例如让他等于1。
Var(y)=nVar(wi)=1
Var(wi)=1/n
同时考虑输入的维度加上下一层的神经元的数量,平均之后则有方差:
![]()
则有正态分布初始化
![]()
三、均匀分布初始化
概念:

为了保证采样的均值为0,我们改写成-a到a的均匀分布
![]()
将目标方差代入公式得出:
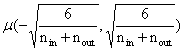
上述两个初始化是2010年提出的Xavier初始化方法,在缓解爆炸和梯度消失都有不错的效果。这种方法对于双曲正切函数效果很好。但对于Relu函数来说不尽人意。
四、kaiming初始化(2015)
应对Relu函数的初始化方法。
正态分布初始化:
![]()
均值分布初始化:

五、总结
参数初始化方法可以减缓梯度爆炸和梯度消失问题,可以让我们训练层数更多的神经网络。
tanh一般使用Xavier初始化方法
ReLU及其变种一般使用Kaiming初始化方法。















 5336
5336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









