







强化微调
RL概念
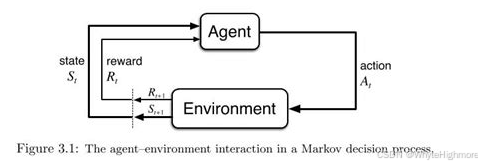
在了解RFT前先了解强化学习,强化学习(RL)是通过智能体(Agent)与环境(Environment)的交互来实现自主学习和决策。在强化学习中,智能体通过执行一系列动作与环境进行互动,环境根据智能体的动作给予奖励或惩罚,智能体的目标是最大化累积奖励 。 强化学习通常基于马尔可夫决策过程(Markov Decision Process, MDP),其中智能体观测到环境状态,根据某种策略选择一个对应的动作,环境执行这个动作后状态发生变化,并给予奖励作为反馈。强化学习的一个重要特征是试错搜索,即智能体需要尝试不同的动作以发现哪些动作可以获得最大的奖励。
RFT概念
强化微调(RFT) 这是一种新的微调方法,它通过少量数据让模型在专业领域达到专家水平。 是一种更进一步模型定制技术,可让开发者使用强化学习针对具体任务对模型进行进一步的微调,并根据提供的参考答案对模型的响应进行评分。
也就是说,强化微调不仅会教模型模仿其输入,更是会让其学会在特定领域以新的方式进行推理。 具体来说,当模型发现问题时,要为它提供思考问题的空间,然后再对模型给出的响应进行打分。之后,利用强化学习的力量,可以强化模型得到正确答案的思维方式并抑制导向错误答案的思维方式。该方法只需几十个例子,模型就能学会在自定义领域以新的有效方式进行推理。来源
其他资料
官方视频概述总结:
- 宣布强化微调 (RFT) 预览版,允许使用强化学习对自定义数据集上的 o1 模型进行微调(明年公开发布)
- RFT 的应用包括为法律、金融、医疗保健和工程等领域创建专家模型(例如,与汤森路透合作寻找法律助理)
- 对于特定任务,o1 Mini + RFT 表现优于完整的 o1 模型,模型更小、更快、更便宜。
OpenAI 仅支持强化微调的 Alpha 测试申请,并且名额有限,「非常适合正在与专家团队一起处理非常复杂任务的组织」,个人用户至少得等到明年了。强化微调将在 2025 年初作为产品发布,对企业、大学和研究院已开放申请测试通道。如果你有需求,可以在这里尝试申请:
相关论文
Vanishing Gradients in Reinforcement Finetuning of Language Models
Apple&Tel Aviv University < 2023.10
问题:在强化微调(Reinforcement Finetuning,RFT)中存在的一个基本优化障碍:当模型下的奖励标准差很小时,输入的期望梯度会消失,即使期望奖励远离最优。
解决方案:通过在RFT基准和受控环境上进行实验,以及理论分析,该论文证明了由于小的奖励标准差导致的梯度消失普遍存在且有害,导致奖励最大化非常缓慢。最后,该论文探索了克服RFT中梯度消失的方法。该论文发现最有希望的候选方法是初始的监督微调(Supervised Finetuning,SFT)阶段,这突显了其在RFT流程中的重要性。此外,该论文还展示了相对较少量的SFT优化步骤,即使在仅对1%的输入样本上进行,也足以满足要求,表明初始SFT阶段在计算和数据标注方面并不昂贵。总的来说,该论文的结果强调了对那些期望梯度消失的输入要谨慎对待,以实现成功的RFT。
Reft: Reasoning with REinforced Fine-Tuning
ByteDance Research < ACL 2024.1 < 论文地址
问题:一种常见的增强大型语言模型(LLMs)推理能力的方法是使用思维链(CoT)标注数据进行有监督微调(SFT)。然而,这种方法并没有表现出足够强的泛化能力,因为训练仅依赖于给定的 CoT 数据。具体地,在数学问题的相关数据集中,训练数据中每个问题通常只有一条标注的推理路径。对于算法来说,如果能针对一个问题学习到多种标注的推理路径,会有更强的泛化能力。
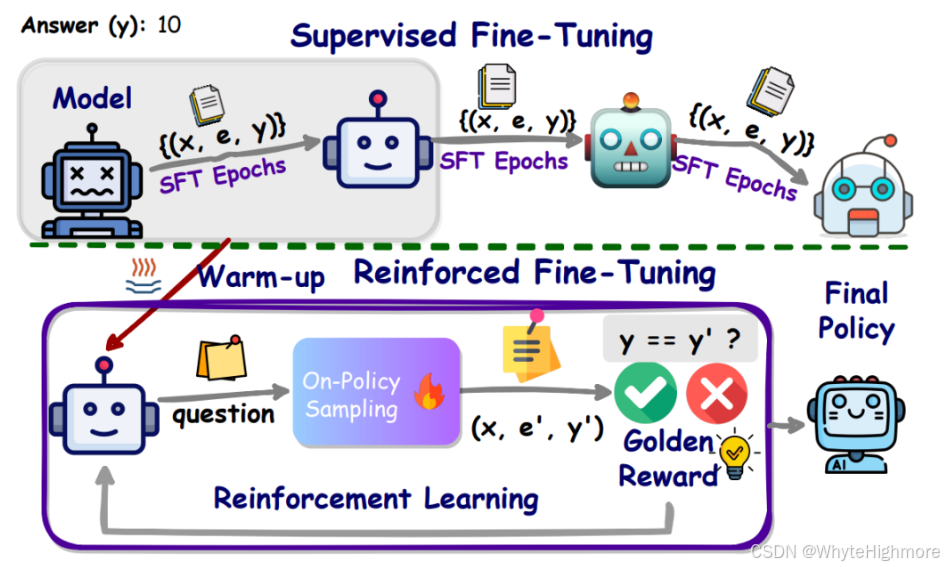
解决方案:为解决这个挑战,以数学问题为例,我们提出了一种简单而有效的方法,称为强化微调,以增强 LLMs 推理时的泛化能力。ReFT 首先使用 SFT 对模型进行预热,然后采用在线强化学习(在该工作中具体是 PPO 算法 Proximal Policy Optimization,近端策略优化算法 )进行优化,即对给定的问题自动采样大量的推理路径,根据真实答案获取奖励,以进一步微调模型。
首先经过监督微调(Supervised Fine-Tuning ),简称SFT,目的就是为了预热RFT,通过Chain of Thought (COT) ,也就是上图中的标记 e,得到很多推理路径样本。RFT预热后,进入第二阶段,使用在线强化学习算法训练,训练完成得到最终Policy. 使用的强化学习算法是OpenAI提出的PPO。
在 GSM8K、MathQA 和 SVAMP 数据集上的大量实验表明,ReFT 显著优于 SFT,并且通过结合多数投票和重新排序等策略,可以进一步提升模型性能。值得注意的是,这里 ReFT 仅依赖与 SFT 相同的训练问题,而不依赖于额外或增强的训练问题。这表明 ReFT 具有优越的泛化能力。
Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning
University of Chinese Academy of Sciences <2024.8<
问题:强化学习(RL)已经成为在特定任务上微调大型语言模型(llm)的关键技术。然而,目前流行的RL调优方法主要依赖于PPO及其变体。虽然这些算法在一般的RL设置中是有效的,但当应用于llm的微调时,它们往往表现出次优的性能和分布崩溃的脆弱性。
解决方案:提出了CORY,将llm的RL微调扩展到一个顺序合作的多智能体强化学习框架,以利用多智能体系统固有的协同进化和紧急能力。
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Google DeepMind < 2024.9
问题:基于llm的个性化代理系统使用大型语言模型(llm)根据用户过去的活动来预测他们的行为。然而,由于这些数据固有的噪声和长度,它们的有效性通常取决于有效利用广泛、长用户历史数据的能力。现有的预训练llm可能生成简洁的摘要,但缺乏下游任务所需的上下文,阻碍了它们在个性化系统中的应用。
解决方案:其引入了基于预测反馈的强化学习(RLPF)。RLPF对llm进行微调,生成简明的、人类可读的用户摘要,这些摘要针对下游任务性能进行了优化。通过最大化生成的摘要的有用性,RLPF有效地提取了大量的用户历史数据,同时为下游任务保留了必要的信息。我们的实证评估表明,在外部下游任务实用性和内在摘要质量上都有显著的改进,在下游任务性能上比基线方法高出22%,在事实性、抽象性和可读性上达到84.59%的胜率。RLPF还显著减少了74%的上下文长度,同时在19个未见过的任务和/或数据集中的16个上提高了性能,展示了其泛化性。这种方法通过有效地将冗长的、嘈杂的用户历史转换为信息丰富的、人类可读的表示,为增强LLM个性化提供了一种很有前途的解决方案。
Training Language Models to Self-Correct via Reinforcement Learning
Google DeepMind < 2024.9
问题:自我纠错是大型语言模型(llm)非常需要的功能,但它一直被发现在现代llm中很大程度上是无效的。目前训练自我纠正的方法通常依赖于多个模型、更高级的模型或其他形式的监督。
解决方案:其开发了一种多回合在线强化学习(RL)方法SCoRe,该方法使用完全自生成的数据显著提高了LLM的自我校正能力。为了构建SCoRe,我们首先表明,在离线模型生成的校正轨迹上,监督微调(SFT)的变体通常不足以灌输自我校正行为。特别是,我们观察到,通过SFT进行的训练要么是数据收集策略和模型自身响应之间的错误分布不匹配的牺牲品,要么是行为崩溃的牺牲品,在这种情况下,学习隐式地只倾向于某种纠正行为模式,而这种行为模式通常在测试问题的自我纠正方面并不有效。SCoRe通过在模型自身的自生成纠正轨迹分布下进行训练,并使用适当的正则化来引导学习过程,以学习在测试时有效的自我纠正行为,而不是针对给定提示拟合高奖励反应,从而解决了这些挑战。这个正则化过程包括在基本模型上进行多回合强化学习的初始阶段,以生成不易崩溃的策略初始化,然后使用奖励奖励来放大自我纠正。使用Gemini 1.0 Pro和1.5 Flash模型,我们发现SCoRe达到了最先进的自校正性能,在MATH和HumanEval上分别提高了基础模型的15.6%和9.1%。

















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









