







发布于IEEE Transactions on Information Forensics and Security
原文链接:https://ieeexplore.ieee.org/document/8737949
摘要
人脸欺骗攻击仍然是现代人脸识别系统的一个威胁。尽管已经提出了许多有效的反欺骗方法,但许多现有方法的性能会因光照而下降。
本文提出了一个双流卷积神经网络(TSCNN),它在RGB空间(原始成像空间)和多尺度Retinex(MSR)空间工作。RGB空间包含详细的面部纹理,但是对光照很敏感;MSR对光照不敏感,但它包含的面部信息不那么详细。此外,MSR图像能有效地捕捉到人脸欺骗的高频信息,对人脸欺骗检测具有较强的鉴别能力。为了有效地融合两个来源(RGB和MSR)的特征,本文提出了一种基于注意力的融合方法,它可以有效地捕捉两个特征的互补性。
在CASIA-FASD、REPLAY-ATTACK和OULU等多种数据集上效果很好,在跨数据集上也十分有效。
引言
背景
随着手机的普及,人脸识别系统的应用越来越普及,其安全性的弱点也越来越突出。 例如,由于社交网络的普及,在互联网上获取一个人的人脸图像来攻击人脸识别系统是非常容易的。 因此,人脸欺骗检测引起了人们的广泛关注,并在过去的几年里引发了大量的研究。
一般来说,人脸欺骗攻击主要有四种类型:照片攻击、掩蔽攻击、视频重放攻击和3D攻击。 由于掩蔽攻击和3D攻击代价较高,因此,照片攻击和视频重放攻击是最常见的两种攻击。 照片和视频重放攻击可以用用户在摄像机前的静态人脸图像和视频发起,这些图像和视频实际上是从真实图像中重新捕获的。 显然,在相同的捕获条件下,重获图像的质量比真实图像的质量要低。 低质量的攻击可能是由于缺乏高频信息、图像条带或云纹效应、视频噪声特征等。显然,这些图像质量下降因素可以作为区分真假人脸的有用线索。
人脸欺骗检测,也称为人脸活性检测,被设计用来对抗不同类型的欺骗攻击。 人脸欺骗检测通常是人脸识别系统的一个预处理步骤,用来判断人脸图像是从真人还是从打印的照片(回放视频)中获取的。 因此,人脸欺骗检测实际上是一个二分类问题。针对人脸欺骗攻击,国内外研究文献主要有四种方法:(1)基于微纹理的方法,(2)基于图像质量的方法,(3)基于运动的方法,(4)基于反射率的方法。
方法的提出
本文提出了一种新的基于深度学习的微纹理(MTB)方法。现有的MTB方法通常是在原始RGB颜色空间中对输入图像进行处理和分析。 然而,RGB图像对光照很敏感。 在光照条件下,基于RGB的MTB方法可能会降低其性能。 这促使我们开发一种光照鲁棒的MTB方法。 因此,我们提出了一种在两个互补空间上训练的双流卷积神经网络(TSCNN):RGB空间(原始空间)和多尺度Retinex(MSR)空间(光照不变空间)。
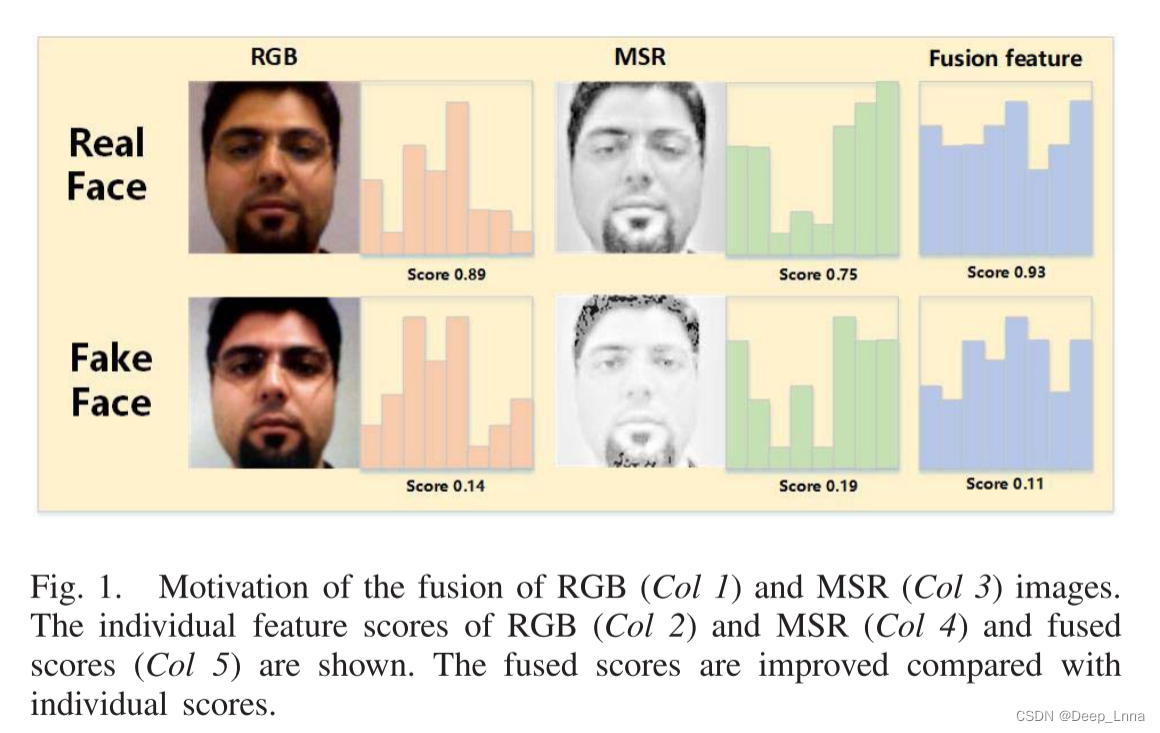
RGB和MSR图像都包含鉴别信息:RGB图像可以用来训练端到端鉴别CNN进行欺骗检测; MSR可以捕获高频信息,并且这些信息对欺骗检测特别有效。 其次,RGB和MSR图像具有互补性:RGB空间包含了人脸的详细信息,但对光照敏感; MSR对光照不敏感,但包含较少的细节面部信息。 在TSCNN框架下,将RGB和MSR图像分别传送到两个CNN(TSCNN的两个分支),生成两个具有鉴别能力的特征,用于反欺骗。 为了有效地融合这两个特征,我们提出了一种基于学习的融合方法,该方法受注意机制的启发。 除了常用的融合方法,如特征平均融合,我们的基于注意力的融合可以自适应地对特征进行加权,以获得良好的融合性能。 图1显示了RGB和MSR的互补性以及特征融合的重要性。图中表示的是RGB(第2栏)和MSR(第4栏)的单独特征得分和融合后的得分(第5栏)。与单个分数相比,融合后的分数有所提高。
主要贡献
- 本文是第一个研究融合RGB和MSR进行人脸反欺骗的;
- 本文提出了基于注意力的融合方法,该方法可以使TSCNN很好地适用于各种光照条件下的图像;
- 本文使用此方法对三个流行的反伪造数据库:CASIA-FASD、REPLAYATTACK和OULU进行评估。结果显示了所提策略的有效性。此外,在跨数据集实验上的效果也非常具有竞争力。
方法
在这一部分中,首先介绍了Retinex的理论,解释了MSR图像具有鉴别性的原因。 然后,分析了RGB和MSR特征的互补性,并详细介绍了所提出的TSCNN。 最后介绍了基于注意力的特征融合方法。
MSR
多尺度视网膜(Multi-Scale Retinex)
本文应用MSR是因为:
- MSR能够将图片的光照成分和反射成分分离,将光照成分去除利用反射信息做活体检测;
- MSR可以作为一个高通滤波,保留 real和fake faces 之间有分辨力的高频信息
假设:Retinex理论是基于这样一个假设,即物体的颜色是由不同波长的光的反射能力决定的。 物体的颜色不受不均匀照明的影响。 该理论将源图像S(x,y)分为反射率R(x,y)和照度L(x,y)两部分。 特别地,R(x,y)和L(x,y)包含频率的不同分量。 R(x,y)侧重于高频分量,而L(x,y)倾向于低频分量。 公式(1)表示Retinex:
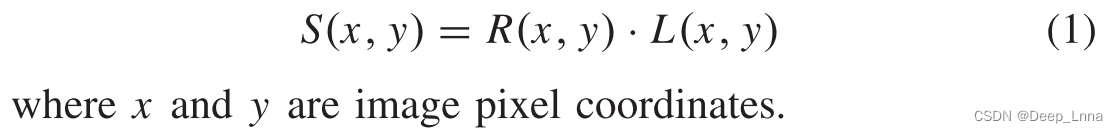
动机:L(x,y) 和 R(x,y) 分别代表光照和反射率(我们任务中的面部皮肤纹理)分量。 L(x,y)是由光源决定的,而R(x,y)是由被捕获物体表面的性质决定的,即我们应用中的脸。 光照与包括人脸欺骗检测在内的大多数分类任务明显无关,因此光照与反射率(纹理)的分离非常重要,因为分离后的反射率只能用于光照不变分类。 由于Retinex理论旨在进行这种分离,因此本文将Retinex用于光照不变人脸欺骗检测。
计算:为方便计算,公式 (1)通常转化为对数域:
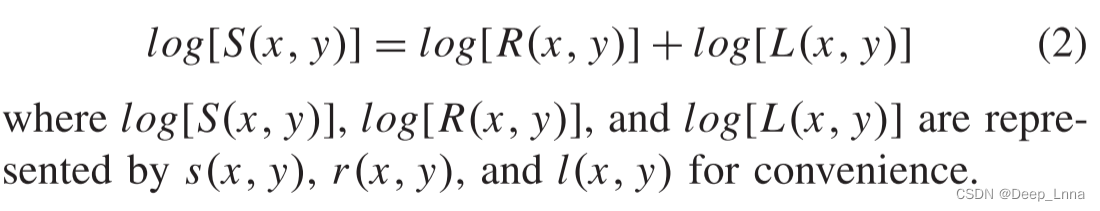
由于s(x,y)是原始图像的对数形式,我们可以通过估计l(x,y)来计算Retinex输出r(x,y)。 因此,Retinex的性能由l(x,y)的估计决定。
下图的每个块代表一个SSR模块。 将所有SSR模块的输出与标度参数加权形成MSR。
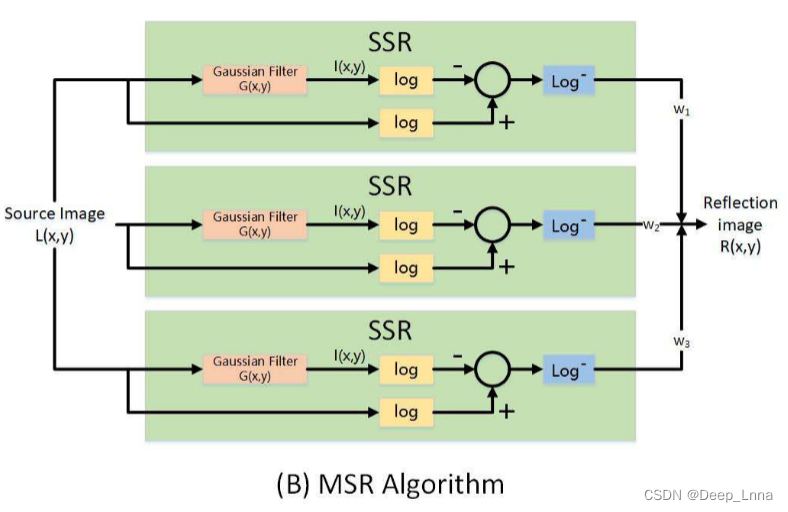
公式如下: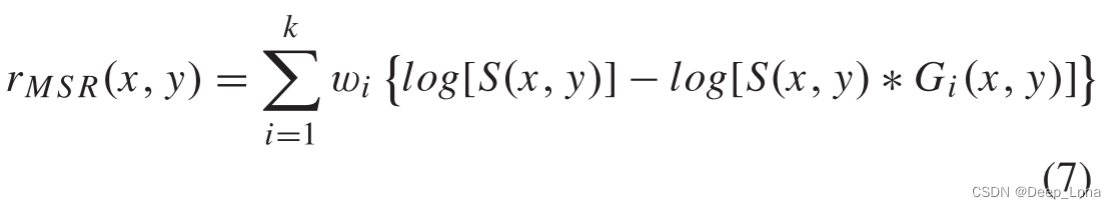
其中,G(x,y)是高斯滤波函数。
总结:MSR的优点:(1)MSR可以分离照度和反射率。(2)保留高频信息,利于检测
双流卷积神经网络(TSCNN)
以离线的方式将原始RGB图像转换为MSR图像。 两个图像源(RGB和MSR)分别馈入两个CNN进行端到端的训练,同时存在交叉熵二值分类损失。 学习到的两个特征(来自RGB和MSR图像)然后学习融合使用注意机制。
RGB和MSR图像的互补性:RGB颜色空间通常用于彩色图像的捕获和显示。 使用RGB图像的优点是:RGB图像能够自然地捕捉到细节的面部纹理,对欺骗检测具有鉴别性。 然而,RGB图像的缺点是对光照变化非常敏感。 其内在原因是RGB空间中三个颜色通道之间具有很高的相关性,使得亮度和色度信息难以分离。 由于现实世界中人脸图像的亮度条件不同,亮度(光照)和色度(肤色)的分离比较困难,从RGB空间学习的特征往往会受到光照的影响。
MSR算法可以实现光照不变的人脸图像。 因此,MSR人脸图像在不受光照影响的情况下,保留了面部皮肤的微观纹理信息。 MSR图像除了具有光照不变的优点外,还可以产生鉴别信息,用于欺骗检测。 具体来说,MSR算法去除原始图像中的低频成分(光照),留下高频成分(纹理细节)。 然而,高频信息对于恶搞检测具有鉴别性,因为真实人脸具有丰富的面部纹理细节,而假人脸,尤其是重新捕获的人脸,丢失了一些此类细节。
双流体系结构:本文提出了一个双流卷积神经网络(TSCNN),如下图所示。
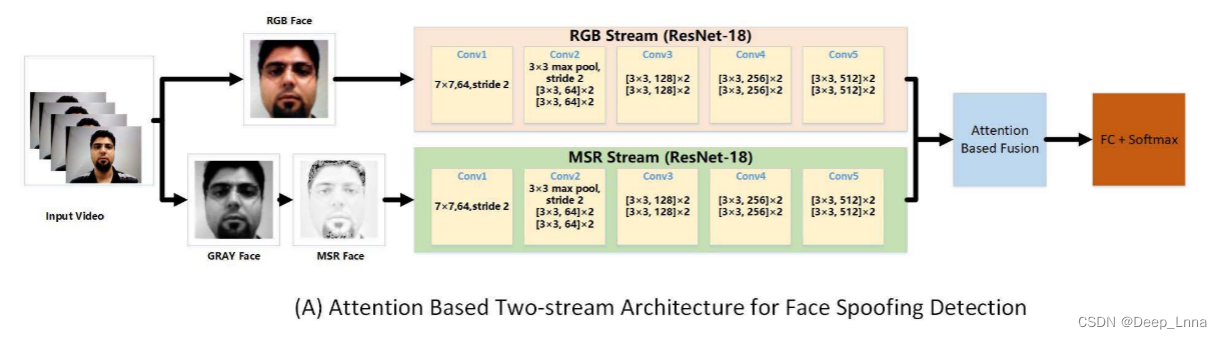
TSCNN由两个输入不同的相同子网络(RGB和MSR图像)组成,在两个子网络的最后一个卷积层提取RGB和MSR图像的学习特征。 给定一幅输入图像/帧,使用MTCNN进行人脸和地标检测。 然后利用仿射变换对检测到的人脸进行对齐。 RGB流对从视频序列中提取的单个RGB帧进行操作。 对于MSR流,单个RGB帧(首先处理到灰度)被转换为MSR图像。 然后MSR图像被馈送到MSR子网络进行训练。 每个流都基于相同的网络,在本工作中,使用了两个成功的网络(MobileNet和Resnet-18)。 为了有效地融合来自两个流的特征,提出了一个基于注意力的融合块。
引入了四元组 M = ( E R G B , E M S R , F , C ) M=(E_{RGB},E_{MSR},F,C) M=(ERGB,E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9099
9099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









