






1 简介
商品级深度相机通常无法感知有光泽、明亮、透明和遥远的表面的深度。为了解决这个问题,我们训练了一个以RGB图像为输入的深度网络,并预测了致密的表面法线和遮挡边界。然后将这些预测与RGB-D相机提供的原始深度观测相结合,以解决所有像素的深度,包括原始观测中缺失的深度。
对于损失的像素点,传统的方法是手工调整和马尔可夫图像填孔。利用深度学习的方法从rgb图像提取深度网络面临许多困难:
一、训练数据的缺少,目前存在的rgbd数据是使用商业深度相机拍摄的,这些数据本身不是完整的深度数据。故本文提出新的数据集。
二、训练网络只预测深度的局部微分性质(表面法线和遮挡边界),这更容易估计。然后,我们用一个全局优化来求解绝对深度。
网络使用rgb图像作为输入,训练他预测局部表面和物体的边缘。然后把这些预测和深度图结合进行全局优化。
2.1 数据集
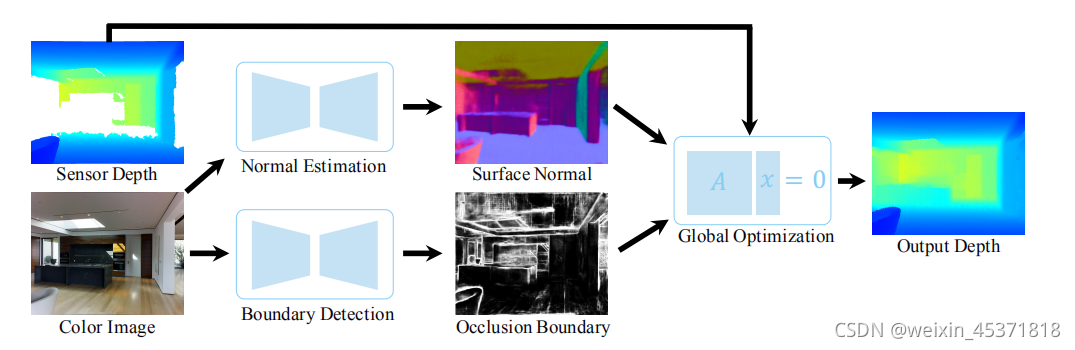
网络结构
这项任务的一种直接方法是用低成本的RGB-D相机捕获图像,并将它们与成本更高的深度传感器同时捕获的图像对齐。这种方法代价昂贵且耗时。

使用多个相机共同构建一副深度图像,相机之间互补。即使这样,原始深度图像中缺失的64.6%的像素是由我们的重建过程填充。这样可以有效去噪声,对于>4m的观测非常重要。
2.2 Depth Representation
我们训练网络来预测每个像素的可见表面的局部性质,然后从这些预测中求解深度。
3.3 Network Architecture and Training
与之前表面的深度估计不同,我们只预测特定空洞内的像素点深度。

上图为仅为深度数据、仅为RGB图输入、深度图和RGB图同时输入对应的预测深度图。可以看出,仅为RGB图输入得到的深度图的背景表现最好。
3 实验
我们的评估只测量在测试深度图像中未观察到的测试图像像素的深度预测的误差。这与之前在深度估计方面的工作相反,后者的误差只对深度摄像机观察到的像素测量。

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









