






【机器学习算法模型推导】1. SVR算法介绍与推导
文章目录
一、SVR算法
SVR做为SVM的分支从而被提出。SVM一般用于二分类问题,而SVR一般应用于数据的拟合。
1.SVR简介
无论SVM还是SVR,都需要建立一个超平面。SVM的目标是令超平面与最近的样本点的距离最大,实现通过超平面分类的目的;而SVR的目标是要使得超平面与最远的样本点的距离最小,从而可以通过利用超平面对数据进行拟合。
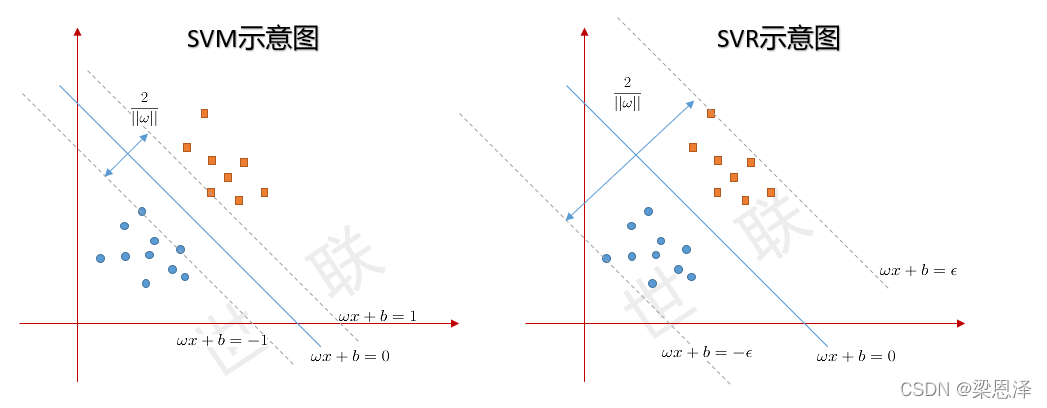
2.SVR数学模型
SVR在线性函数两侧制造了一个“间隔带”,对于所有落入到间隔带内的样本,都不计算损失;只有间隔带之外的,才计入损失函数。之后再通过最小化间隔带的宽度与总损失来最优化模型。
由于模型需要放弃一些边缘的点,用于最小化间隔带,
所以引入了松弛变量
ξ
i
\xi_i
ξi和
ξ
i
∗
\xi_i^*
ξi∗(松弛变量有两个符号,SVM只有1个符号), 代表上图上边缘点和下边缘点与中间实线的距离(y轴投影距离而不是欧式距离,直接计算点与点在实线上的投影的y轴上的差即可。):
2.1 SVR目标函数
m i n ω , b 1 2 ∥ ω ∥ 2 + C ∑ i = 1 l ( ξ i + ξ i ∗ ) \mathop{min}\limits_{\omega, b}\frac{1}{2}\parallel\omega\parallel^2 + C\sum_{i=1}^{l}(\xi_i + \xi_i^*) ω,bmin21∥ω∥2+Ci=1∑l(ξi+ξi∗)
s . t . { y i − ω x − b ≤ ϵ + ξ i ω x + b − y i ≤ ϵ + ξ i ∗ ξ i , ξ i ∗ ≥ 0 s.t.\left\{ \begin{array}{l} y_i-\omega x-b \le \epsilon + \xi_i \\ \omega x + b - y_i \le \epsilon + \xi_i^* \\ \xi_i,\xi_i^* \qquad \quad \ge 0 \end{array} \right. s.t.⎩⎨⎧yi−ωx−b≤ϵ+ξiωx+b−yi≤ϵ+ξi∗ξi,ξi∗≥0
其中, ξ i \xi_i ξi和 ξ i ∗ \xi_i^* ξi∗的取值为:
{ ξ i = y i − ( ω x + b + ϵ ) , y i > ω x + b + ϵ ξ i = 0 , o t h e r w i s e \left\{ \begin{array}{l} \xi_i=y_i-(\omega x + b +\epsilon), y_i > \omega x + b + \epsilon\\ \xi_i=0, \qquad \qquad \qquad \quad otherwise \end{array} \right. {ξi=yi−(ωx+b+ϵ),yi>ωx+b+ϵξi=0,otherwise
{ ξ i ∗ = ( ω x + b − ϵ ) − y i , y i < ω x + b − ϵ ξ i ∗ = 0 , o t h e r w i s e \left\{ \begin{array}{l} \xi_i^*=(\omega x + b -\epsilon)-y_i, y_i < \omega x + b - \epsilon\\ \xi_i^*=0, \qquad \qquad \qquad \quad otherwise \end{array} \right. {ξi∗=(ωx+b−ϵ)−yi,yi<ωx+b−ϵξi∗=0,otherwise
2.2 为了最小化目标函数,根据约束条件,构造拉格朗日函数
L = 1 2 ∥ ω ∥ 2 + C ∑ i = 1 l ( ξ i + ξ i ∗ ) − ∑ i = 1 l α i ( ϵ + ξ i − y i + ω x + b ) − ∑ i = 1 l α i ∗ ( ϵ + ξ i ∗ + y i − ω x − b ) − ∑ i = 1 l ( η i ξ i + η i ∗ ξ i ∗ ) s . t . α i , α i ∗ , η i , η i ∗ ≥ 0 \begin{array}{l} L=\frac{1}{2}\parallel\omega\parallel^2 + C\sum_{i=1}^{l}(\xi_i + \xi_i^*) \\ \qquad - \sum\limits_{i=1}^l \alpha_i(\epsilon + \xi_i - y_i + \omega x + b) \\ \qquad - \sum\limits_{i=1}^l \alpha_i^*(\epsilon + \xi_i^* + y_i - \omega x - b) \\ \qquad - \sum\limits_{i=1}^l(\eta_i\xi_i + \eta_i^*\xi_i^*)\\ s.t. \quad\alpha_i, \alpha_i^*, \eta_i, \eta_i^* \ge 0 \end{array} L=21∥ω∥2+C∑i=1l(ξi+ξi∗)−i=1∑lαi(ϵ+ξi−yi+ωx+b)−i=1∑lαi∗(ϵ+ξi∗+yi−ωx−b)−i=1∑l(ηiξi+ηi∗ξi∗)s.t.αi,αi∗,ηi,ηi∗≥0
原问题可以化为:
m
i
n
ω
,
b
m
a
x
α
i
(
∗
)
,
η
i
(
∗
)
L
(
ω
,
b
,
ξ
i
,
ξ
i
∗
,
α
i
,
α
i
∗
,
η
i
,
η
i
∗
)
\mathop{min}\limits_{\omega, b}\mathop{max}\limits_{\alpha_i^{(*)}, \eta_i^{(*)}}L(\omega, b, \xi_i,\xi_i^*, \alpha_i, \alpha_i^*, \eta_i, \eta_i^*)
ω,bminαi(∗),ηi(∗)maxL(ω,b,ξi,ξi∗,αi,αi∗,ηi,ηi∗)
2.3 原问题的对偶问题
m a x α i ( ∗ ) , η i ( ∗ ) m i n ω , b L ( ω , b , ξ i , ξ i ∗ , α i , α i ∗ , η i , η i ∗ ) \mathop{max}\limits_{\alpha_i^{(*)}, \eta_i^{(*)}}\mathop{min}\limits_{\omega, b}L(\omega, b, \xi_i,\xi_i^*, \alpha_i, \alpha_i^*,\eta_i, \eta_i^*) αi(∗),ηi(∗)maxω,bminL(ω,b,ξi,ξi∗,αi,αi∗,ηi,ηi∗)
2.4 分别对 ω , b , ξ i , ξ i ∗ \omega,b,\xi_i,\xi_i^* ω,b,ξi,ξi∗求偏导,并令偏导为0
{ ∂ L ∂ ω = ω − ∑ i = 1 l ( α i ∗ − α i ) x i = 0 ∂ L ∂ b = ∑ i = 1 l ( α i ∗ − α i ) = 0 ∂ L ∂ ξ i = C − α i − η i ∂ L ∂ ξ i ∗ = C − α i ∗ − η i ∗ \left\{ \begin{array}{l} \frac{\partial L}{\partial \omega} = \omega - \sum\limits_{i=1}^{l}(\alpha_i^* - \alpha_i)x_i = 0\\ \frac{\partial L}{\partial b} =\sum\limits_{i=1}^{l}(\alpha_i^* - \alpha_i) = 0\\ \frac{\partial L}{\partial \xi_i}=C - \alpha_i - \eta_i\\ \\ \frac{\partial L}{\partial \xi_i^*} = C - \alpha_i^* - \eta_i^* \end{array} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂ω∂L=ω−i=1∑l(αi∗−αi)xi=0∂b∂L=i=1∑l(αi∗−αi)=0∂ξi∂L=C−αi−ηi∂ξi∗∂L=C−αi∗−ηi∗
2.5 用SMO算法求解SVR
使用SMO算法前,还需将 α i , α i ∗ \alpha_i, \alpha_i^* αi,αi∗转化为一个参数,因为SMO算法针对的是任意样本 x i x_i xi 只对应一个参数 α i \alpha_i αi的情况。
过程采用拉格朗日对偶法,对偶问题有解的充要条件是满足KKT条件,对于SVR的对偶问题,其KKT条件如下:
{
α
i
(
ϵ
+
ξ
i
−
y
i
+
ω
x
+
b
)
=
0
α
i
∗
(
ϵ
+
ξ
i
+
y
i
−
ω
x
−
b
)
=
0
(
C
−
α
i
)
ξ
i
=
0
(
C
−
α
i
∗
)
ξ
i
∗
=
0
α
i
α
i
∗
=
0
ξ
i
ξ
i
∗
=
0
\left\{ \begin{array}{l} \alpha_i(\epsilon + \xi_i - y_i + \omega x + b) = 0\\ \alpha_i^*(\epsilon + \xi_i + y_i - \omega x - b) = 0\\ (C-\alpha_i)\xi_i = 0\\ (C-\alpha_i^*)\xi_i^* = 0\\ \alpha_i\alpha_i^* = 0\\ \xi_i\xi_i^* = 0 \end{array} \right.
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧αi(ϵ+ξi−yi+ωx+b)=0αi∗(ϵ+ξi+yi−ωx−b)=0(C−αi)ξi=0(C−αi∗)ξi∗=0αiαi∗=0ξiξi∗=0
设
λ
i
=
α
i
−
α
i
∗
\lambda_i = \alpha_i - \alpha_i^*
λi=αi−αi∗。由KKT条件,
α
i
,
α
i
∗
\alpha_i,\alpha_i^*
αi,αi∗至少有一个为0。所以
∣
λ
i
∣
=
α
i
+
α
i
∗
|\lambda_i| = \alpha_i + \alpha_i^*
∣λi∣=αi+αi∗。代入对偶问题,则有(先用求导结果替换
ω
\omega
ω):
m
i
n
λ
[
∑
i
=
1
l
y
i
λ
i
+
ϵ
∣
λ
i
∣
+
1
2
∑
i
=
1
l
∑
j
=
1
l
λ
i
λ
j
x
i
T
x
i
]
s
.
t
.
{
∑
i
=
1
l
λ
i
=
0
−
C
≤
λ
i
≤
C
\begin{array}{l} \mathop{min}\limits_{\lambda}[\sum\limits_{i=1}^{l}y_i\lambda_i+ \epsilon|\lambda_i| + \frac{1}{2}\sum\limits_{i=1}^{l}\sum\limits_{j=1}^{l}\lambda_i\lambda_j x_i^Tx_i] \\ s.t.\left\{\begin{array}{l} \sum\limits_{i=1}^{l}\lambda_i = 0\\ -C \le \lambda_i \le C \end{array} \right. \end{array}
λmin[i=1∑lyiλi+ϵ∣λi∣+21i=1∑lj=1∑lλiλjxiTxi]s.t.⎩⎨⎧i=1∑lλi=0−C≤λi≤C
最后再参考SMO算法,求出回归模型系数
ω
,
b
\omega, b
ω,b


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











