







考完研了,好久没有接触过视觉相关的东西了,参加了datawhale的组队学习,也顺便给毕设开个头,这个系列写一下自己的心得和学到的东西。
注:本流程只包含理论知识,后面返校拿到设备会出一个实战代码系列
数据规范
机器学习很基础的东西就是数据集,数据集非常影响后续的准确度、泛化性等指标,因此我们在创建一个数据集的时候一定要注意同一物体的不同角度、环境、形态;同一群体的不同种类以及数据格式的统一与规范等。考虑的情况越多,训练集与实际环境的图像分布越相似,后面训练出的模型越优秀,也就能更好地避免OOD问题。
数据可视化
数据可视化一般是用来项目汇报、论文展示中使用,比如展示数据集图像尺寸、比例分布;拍摄场地统计;数据集中随机样本抽取展示分布情况;各类别的图像数量等,做好这些会让数据集的泛化性等指标得到很好的展示。
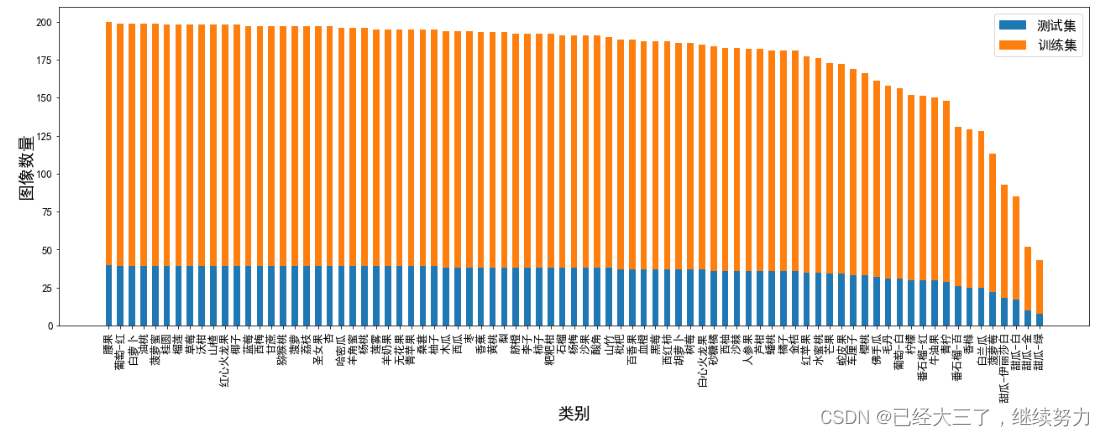
训练集和测试集的划分
一般我们都是设定一个测试集的比例,在数据集中随机划分出相应比例的图片当作测试集,剩余的大部分数据用来训练使用,在划分的同时也可以导出csv文件记录数量统计表格,在后期可以进行引用。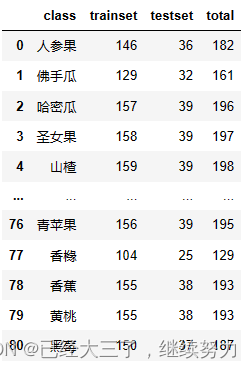















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









