






团队名称:兰大超算课程小分队
问题陈述
随着 CT 和 MRI 技术的提高,医生需要查看的医学影像极大地增加。通过计算机视觉,采用人工智能的诊断成像检测可以提高临床医生的工作效率,增强成像解释,并协助异常检测、鉴别诊断和工作列表优先级排序。
项目简介
参考英特尔提供的药片缺陷检测项目的内容,来进行医学成像诊断检测,数据集来自官方:https://filerepo.idzcn.com/dataset/assignment_2.zip,链接:百度网盘 请输入提取码 提取码:fly8。
使用resnet34模型来进行医学成像诊断检测,给出的数据集图像包含训练集、验证集、测试集,其中比例为:。然后项目通过对比标准版本的 PyTorch 1.8.0 和英特尔® PyTorch* 扩展 (IPEX) 1.8.0在该医学成像数据集上的诊断检测效果来分析、判断、总结出英特尔® PyTorch* 扩展 (IPEX) 的优势。
构建项目时采用的技术栈及主要实现方案
采用的技术栈
1.使用的编程语言:python 2.深度学习框架:pytorch、英特尔® PyTorch* 扩展 (IPEX) 3.模型技术:resnet34 4.任务:医学CT图像分类
主要实现方案
1.数据预处理:使用pytorch官方推荐的resnet模型图像预处理方式:
训练集上随机裁剪成224x224 的图像,这样是为了适配resnet模型框架,然后随机水平翻转图像,通过随机翻转图像,增加了数据的多样性,使得模型更具有泛化性。然后将图像转换为PyTorch 的张量格式,便于后续操作。最后使用pytorch官方推荐的图像均值( [0.485, 0.456, 0.406] )、标准差( [0.229, 0.224, 0.225])进行归一化处理,这样有助于模型的收敛和训练的稳定性。
验证集上进行类似的处理,先将图像调整为大小为 256x256 像素,确保图像在进行后续处理之前具有相同的大小。然后对图像进行中心裁剪,裁剪后的图像大小为 224x224 像素。然后将图像转换为 PyTorch 的张量格式。最后图像进行标准化处理,处理方法和训练集上处理方法相同。
2.加载数据:使用DataLoader方法加载数据。
3.超参数的设置:batch_size设置为256,lr设置为0.0001,使用Adam优化器来优化模型参数。
4.最优模型的选择:进行一个epoch训练之后,在验证集上测试训练结果,得到一个准确率,如果该准确率大于之前保存的模型准确率(初始为0),那么就将本次训练好的模型保存下来。
5.模型框架介绍:使用resnet34模型。
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如下图所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
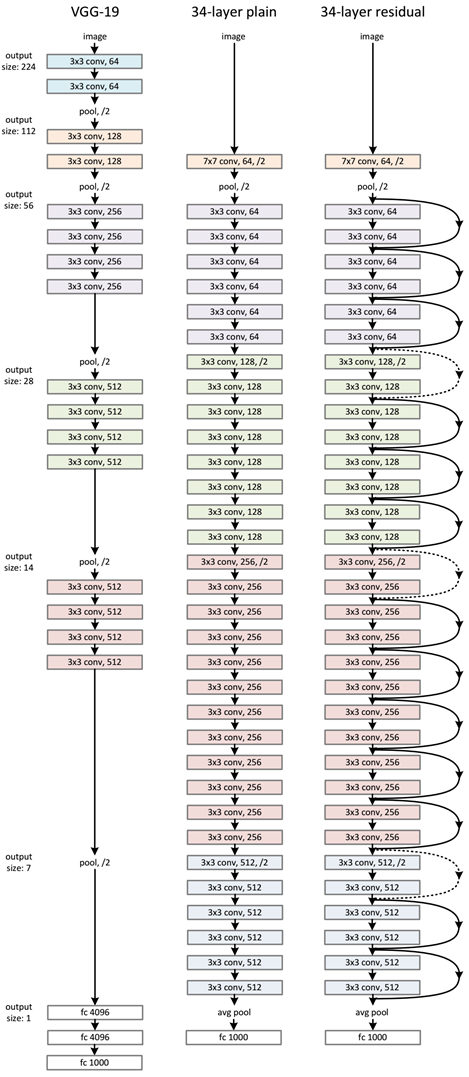
ResNet通过残差学习解决了深度网络的退化问题,使得模型深度可以增加到很深,从而提高模型的能力,获取数据中更深层次的信息。
6.使用的优化技术:训练过程使用英特尔® PyTorch* 扩展 (IPEX)针对在英特尔平台下优化。英特尔® PyTorch*扩展为 PyTorch 提供了额外的优化,旨在提升英特尔硬件上的性能。该优化方案主要特定如下:
-
易于使用的 Python API:
-
提供简单的前端 Python API 和实用程序,使用户能够轻松对代码进行修改,实现图优化和算子优化等性能优化。
-
只需在原始代码中进行少量修改,通常增加 2 到 3 个子句即可利用这些优化。
-
-
Channels Last:
-
相比默认的 NCHW 内存格式,提供了 channels_last (NHWC) 内存格式,以加速卷积神经网络。
-
在英特尔®PyTorch*扩展中启用了 NHWC 内存格式,可以进一步加速大多数关键 CPU 算子。
-
预计会全面部署到 PyTorch 主分支中,但目前尚未全部合并。
-
-
自动混合精度 (AMP):
-
内置 AVX512 指令集的第三代至强可扩展服务器(Cooper Lake)原生支持低精度数据类型 BFloat16。
-
自动混合精度 (AMP) 支持已在英特尔®PyTorch*扩展中大规模启用,包括面向 CPU 的 BFloat16 和算子的 BFloat16 优化。
-
预计大多数优化将很快整合到 PyTorch 主分支中。
-
-
图优化:
-
支持融合常用的算子模式,如 Conv2D+ReLU,线性+ReLU 等,以透明的方式为用户带来融合的优势。
-
引入 oneDNN Graph API,将图优化部署到上游的 PyTorch,进一步优化 torchscript 的性能。
-
-
算子优化:
-
对算子进行优化,实现了多个定制算子,提升了性能。
-
通过 ATen 注册机制,英特尔®PyTorch*扩展中的优化版本替代多个 ATen 算子。
-
优化了多个主流拓扑的定制算子(例如,在 Mask R-CNN 中定义的 ROIAlign 和 NMS)以提升拓扑的性能。
-
收获
在本次的项目实践当中,我们团队学会了如何使用英特尔的英特尔® PyTorch* 扩展 (IPEX)来进行针对英特尔平台下的模型训练优化,该扩展使用起来非常方便、简单,只需要在训练之前加入特定的优化函数即可,但是效果是非常明显的,速度大概提高了18%,准确率大概提高了3%左右,未来如果需要在英特尔平台下训练模型,使用oneAPI提供的优化方法将会有巨大的帮助。

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









