







本来觉得是一个简单的用LLM来生成评分的工作,但细看一下还是蛮有意思的。写了一些初级的内容,适合想要了解这一工作思想的朋友们。
官方网站:https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/context_precision/
1. 忠实性
定义:如果答案中的主张可以从上下文c(q)中推断出来,那么答案as(q)就忠实于上下文c(q)。
为了估计忠实度,首先使用LLM提取一组语句S(as(q)),这一步的目的是将较长的句子分解成较短且重点更突出的断言。
通过下面的两个prompt得出。


然后,再将检索到的上下文context,和statement一起给出,让模型来判断有多少statement是可以从context中得出的,来计算忠诚度。
最终忠实度得分 F F F的计算公式为 F = ∣ V ∣ / ∣ S ∣ F=|V|/|S| F=∣V∣/∣S∣,其中 ∣ V ∣ |V| ∣V∣是根据LLM得到支持的语句数,而 ∣ S ∣ |S| ∣S∣是语句总数。
2. 答案相关性
定义:如果答案as(q)以适当的方式直接回答了问题,就认为答案as(q)是相关的。
为了估算答案相关性,对于给定的答案as(q),促使LLM根据as(q)生成n个潜在问题qi,如下所示:
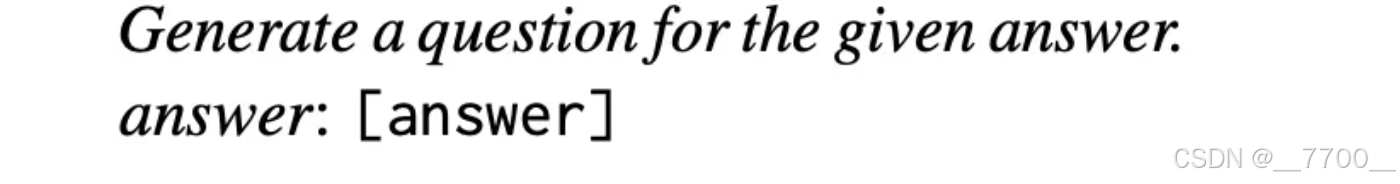
利用OpenAI API提供的文本嵌入ada-002模型获取所有问题的嵌入。对于每个qi,计算与原始问题q的相似度(q,qi),即相应嵌入之间的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









