









论文标题:
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
作者单位:
中国科学技术大学,上海算法创新研究院,新华社融媒国重
论文地址:
https://arxiv.org/abs/2401.17043
数据&代码地址:
https://github.com/IAAR-Shanghai/CRUD_RAG

介绍
检索增强生成(RAG)是一项利用外部知识源提升大型语言模型(LLMs)的文本生成能力的技术。基于输入检索语料库中的相关段落,并将其与输入一同提供给大模型。在外部知识的辅助下,大模型能够生成更准确可信的回应,有效解决知识过期、幻觉和领域专业知识不足等挑战。因此,RAG 技术在大模型时代备受瞩目。
检索增强策略(RAG)已经在广泛的实践中证明了其有效性,但是在实际场景中应用和部署 RAG 系统仍然面临着挑战。RAG 系统的性能取决于系统中的各种参数,如检索模型、外部知识库的构建和语言模型。因此,为了指导 RAG 系统的部署,对 RAG 系统进行自动评估至关重要。
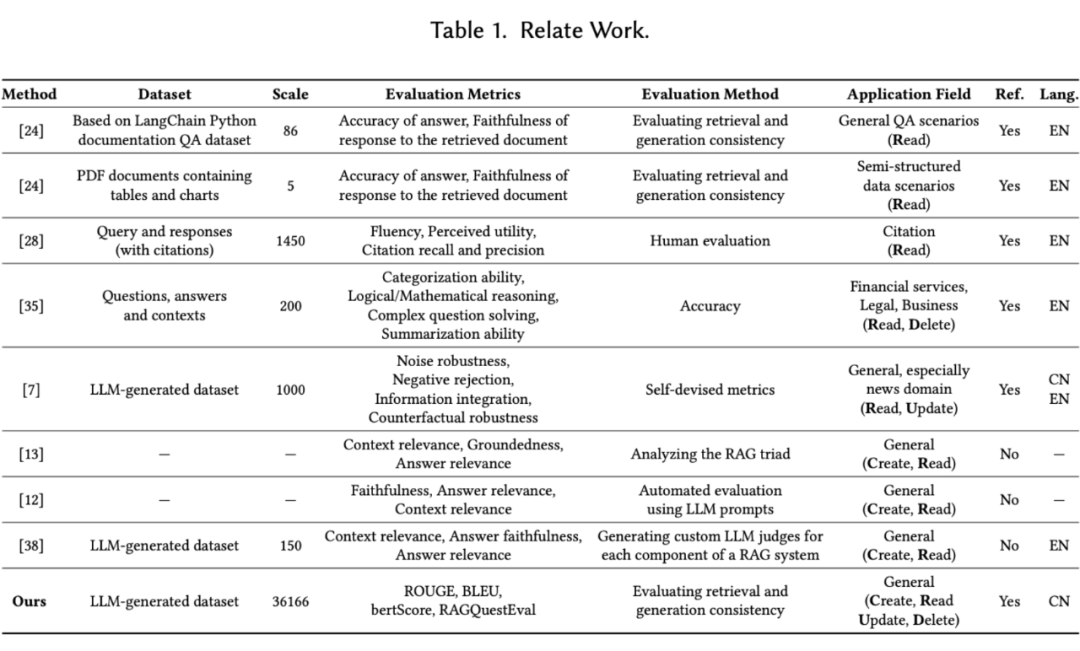
目前用于评估 RAG 系统性能的基准可以分为两类:需要参考答案的和不需要参考答案的。无参考评估框架,如 RAGAS 和 ARES,使用大模型自动评估 RAG 系统生成内容的上下文相关性、忠实度和信息量。这些框架不依赖于真实参考答案,而只评估生成文本与检索上下文的一致性。如果检索的外部信息质量低,这种方法可能不够可靠。
因此,依赖参考答案的评估方式仍然是评估 RAG 系统的主要方法。目前,有参考答案的评估基准只有少数几个小规模的,因为创建高质量的数据集并对其进行实验涉及到相当大的成本。而且,这些评估 RAG 的基准都依赖于问答任务来衡量 RAG 系统的性能。
然而,问答并非是唯一的 RAG 应用场景,适用于问答的优化策略未必能推广到其他场景。因此,这些基准可能无法充分评估 RAG 系统在不同应用场景下的表现。
此外,在实验中,当前的评估通常集中于评估 RAG 链路中的大模型部分,而忽略了检索模型和外部知识库构建。这些组件对于 RAG 系统同样至关重要。
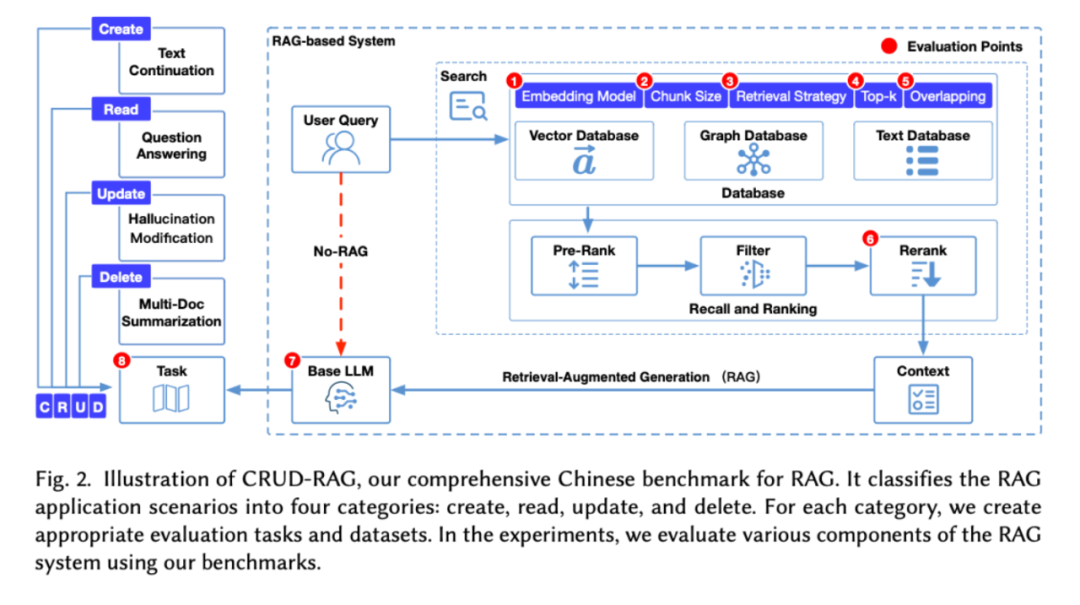
为了克服以上缺陷,研究者们急需一个全面的、更大规模的 RAG 评估基准,不仅仅涵盖问答任务。事实上,任何涉及知识库和用户交互的操作,都可以被分为增、删、改、查四类,也被称为 CRUD 操作。而 RAG 系统的本质是大模型和外部知识库的交互。因此,同样可以将 RAG 系统的应用场景分为增、删、改、查四类。
如下图所示,CRUD 的每个类别分别代表了 RAG 系统的不同应用场景。
在“增”场景下,系统通过参考知识库中的信息,丰富输入文本,生成创意输出,如诗歌、故事或代码。
在“删”场景下,系统简化检索到的信息,删除无关的不重要内容,呈现给用户更精炼的摘要。
在“查”场景下,系统检索外部知识,推理并回答用户的问题。
在“改”场景下,系统使用检索到的内容纠正输入文本中的错误,纠正拼写、语法或事实错误。
为了在这四个场景下评估 RAG 系统的性能,作者构建了 CRUD-RAG,一个全面的、大规模的中文 RAG 评估基准。CRUD-RAG 包括四个评估任务:文本续写、问答(包括单文档问答和多文档问答)、幻觉纠正和多文档摘要,分别对应于 RAG 应用场景的 CRUD 分类。
在实验中,作者系统地评估了 RAG 系统在 CRUD-RAG 基准上的性能。评估了可能会影响 RAG 系统性能的各种因素,如上下文长度、块大小、嵌入模型、检索算法和大模型。根据实验结果,作者还为构建有效的 RAG 系统提供了一些建议。
主要贡献点:
提出了一个更为全面的 RAG 评估基准:CRUD-RAG 评估基准不再局限于使用问答任务评估 RAG 系统,而是涵盖 RAG 应用的增删改查(CRUD)四种不同场景。
构建高质量的评估数据集:作者基于 RAG 的应用场景&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









