









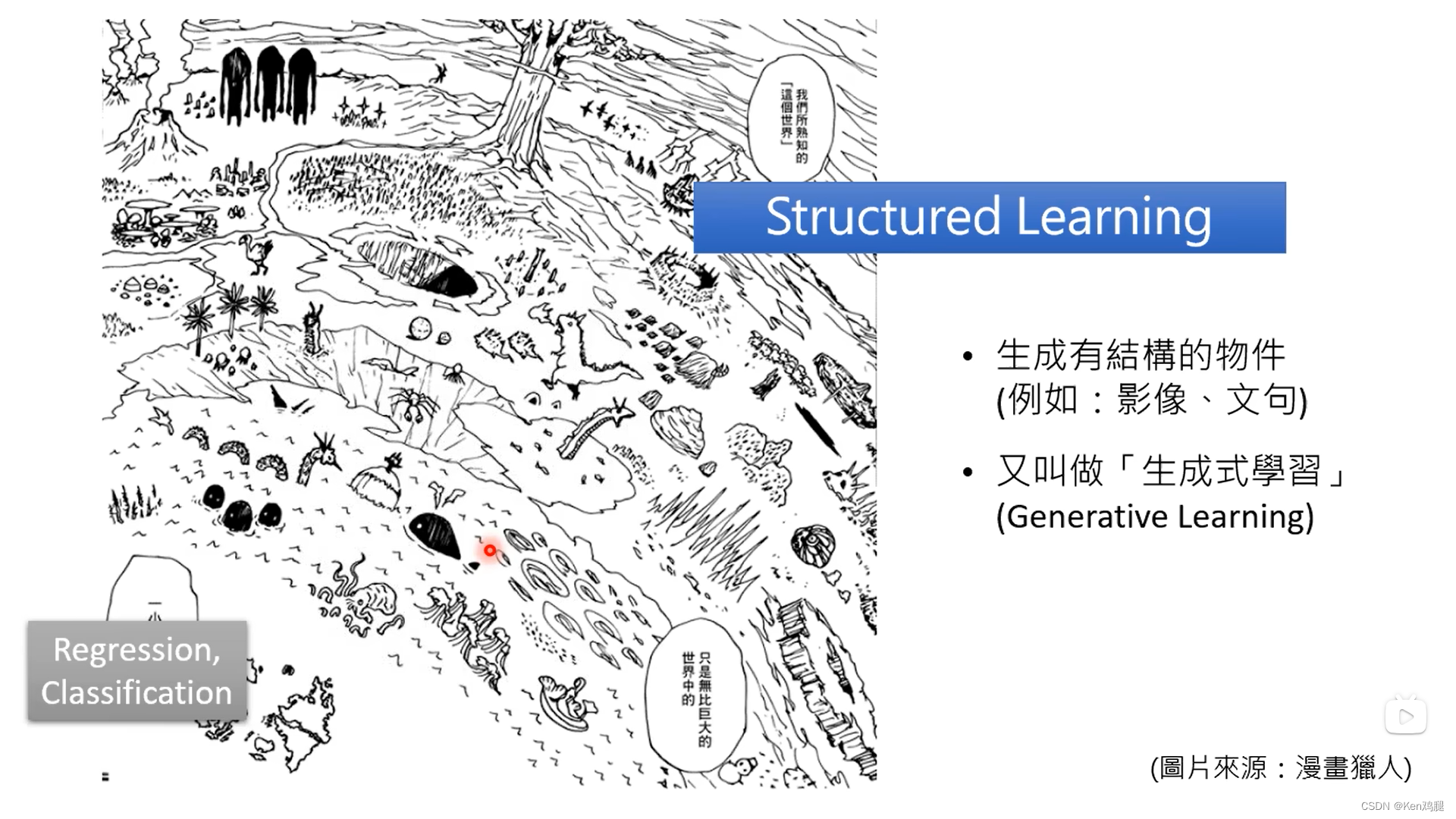
机器学习实际就是找出一个函数,我们输入内容,通过该函数可以有损失最小的输出,通常我们认为的分类只有两种,回归算出一个值或者是分类。但实际上还有一个类型叫generative learning也叫Structured Learning
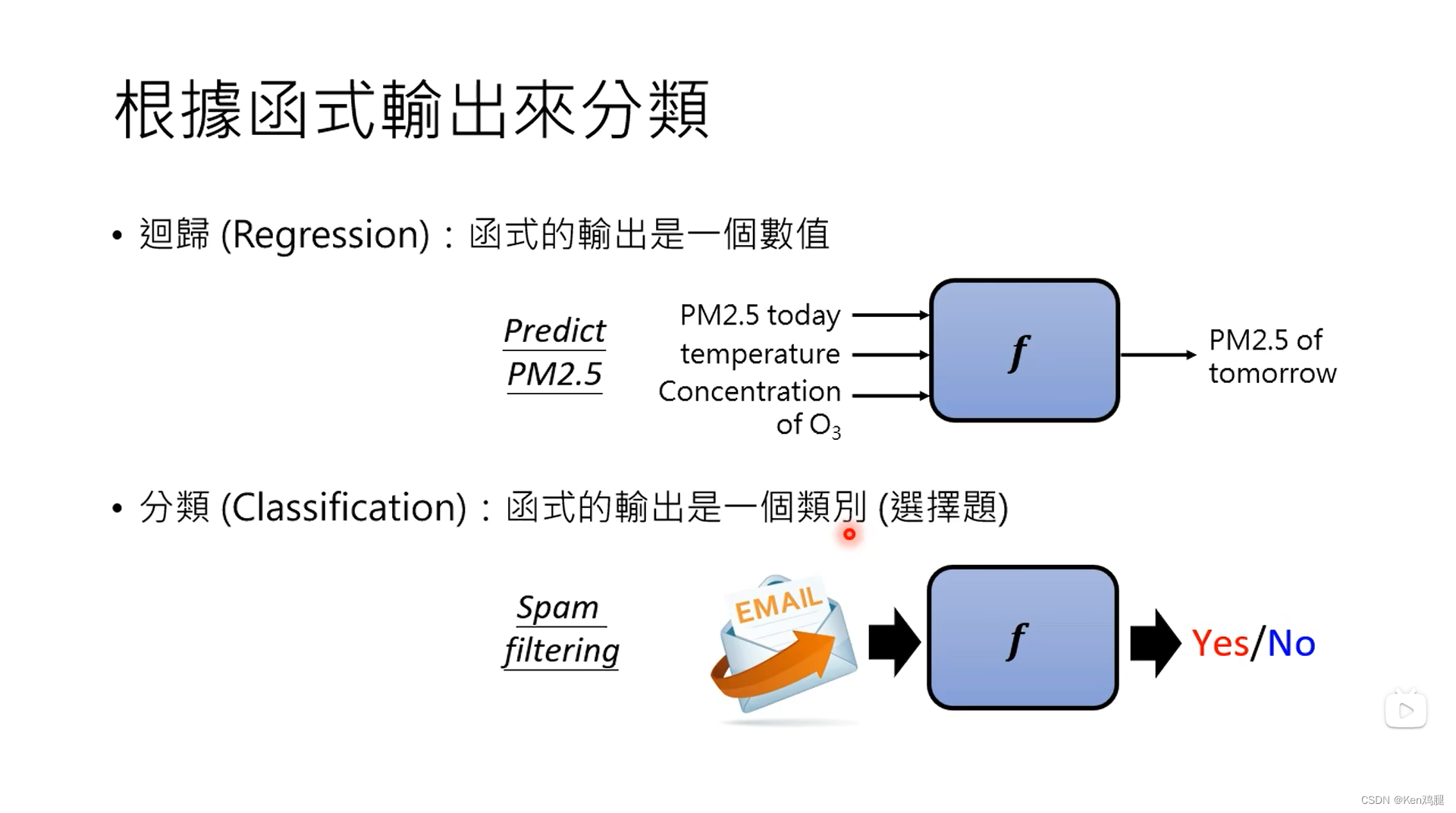
1.找出函数的三个步骤是设定范围,设定目标,达成目标。这里CNN,RNN,Transformer都是属于Deep Learning的范畴,也是候选式的集合。
2.设定目标可以分为有监督的学习和部分监督的学习,有监督的学习可以直接算出loss值,部分监督学习则需要去设定标准来算出loss值
3.达成目标就需要用到类似梯度算法等算法内容了。
生成式学习的两种策略:1.逐个击破2.一次到位
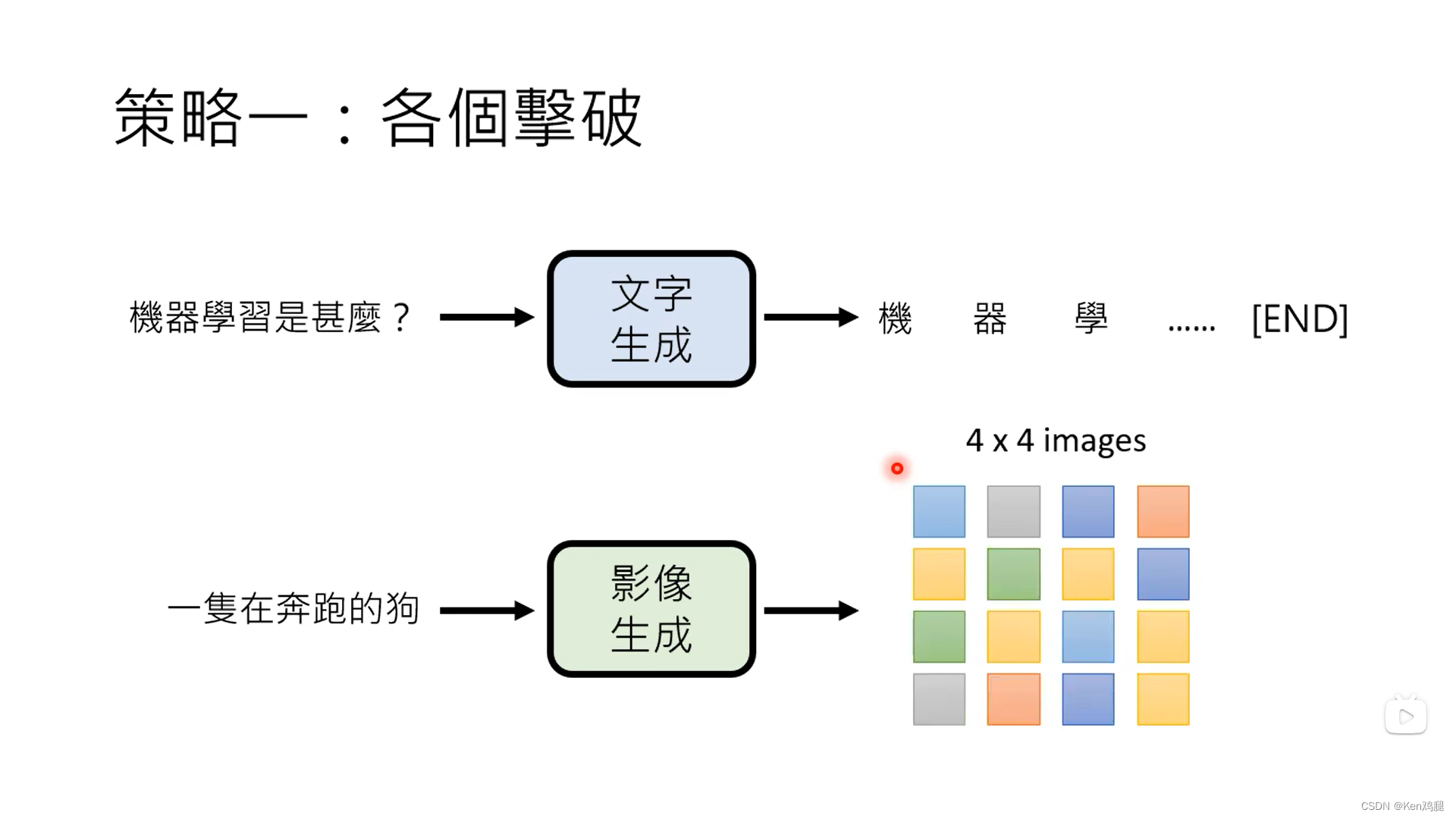
逐个击破:
这里举了三个生活中常见的物件,句子,图像,语音,分别由token,像素,和取样点构成中文的token就是字,英文则是word piece
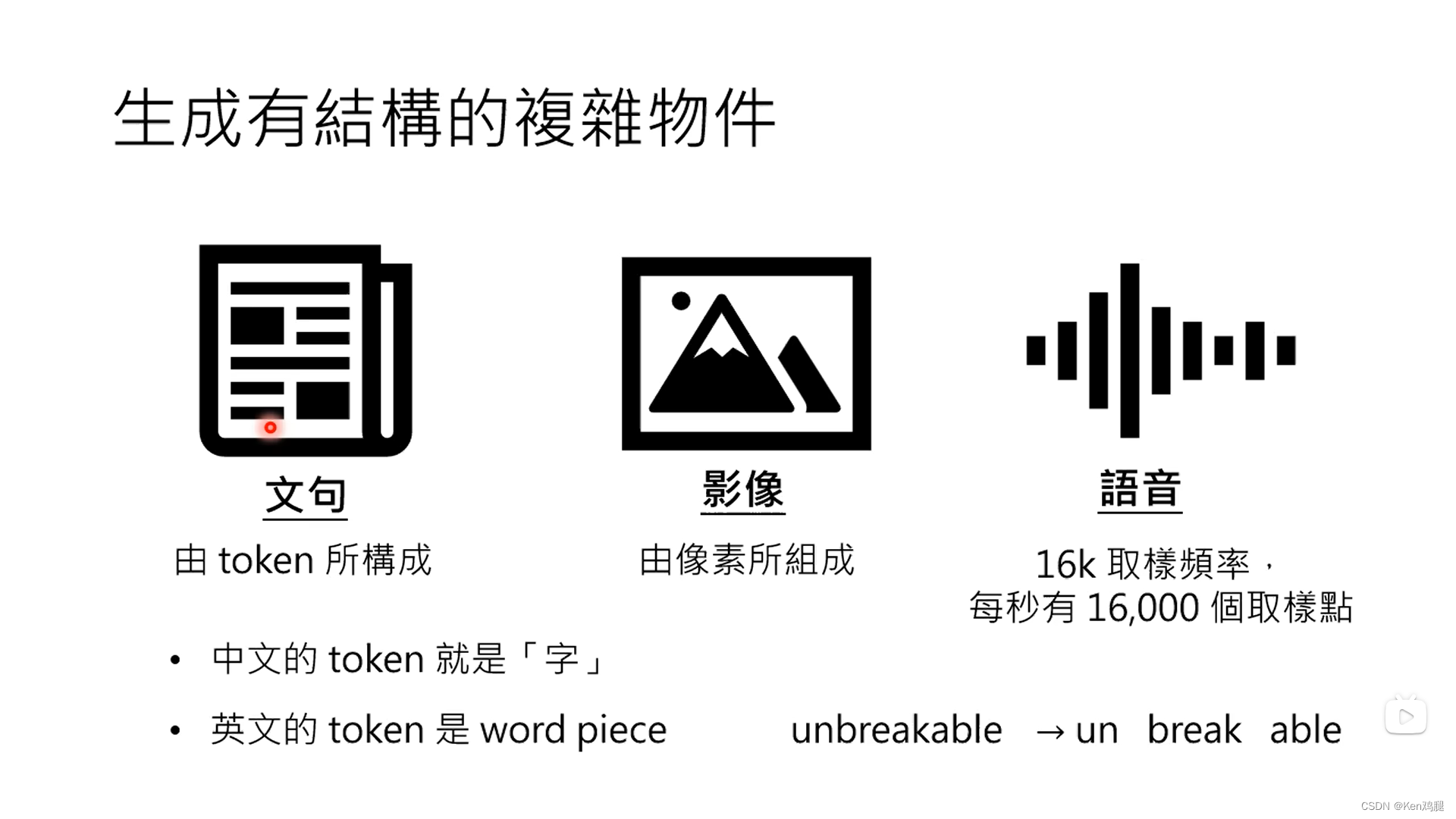
逐个击破对于文字而言是根据前面的内容一个一个去生成,不会出现太大的语义问题,缺点是比较慢。但是对于图像而言,这样的速度慢的可恶,选用一次到位会更好一些
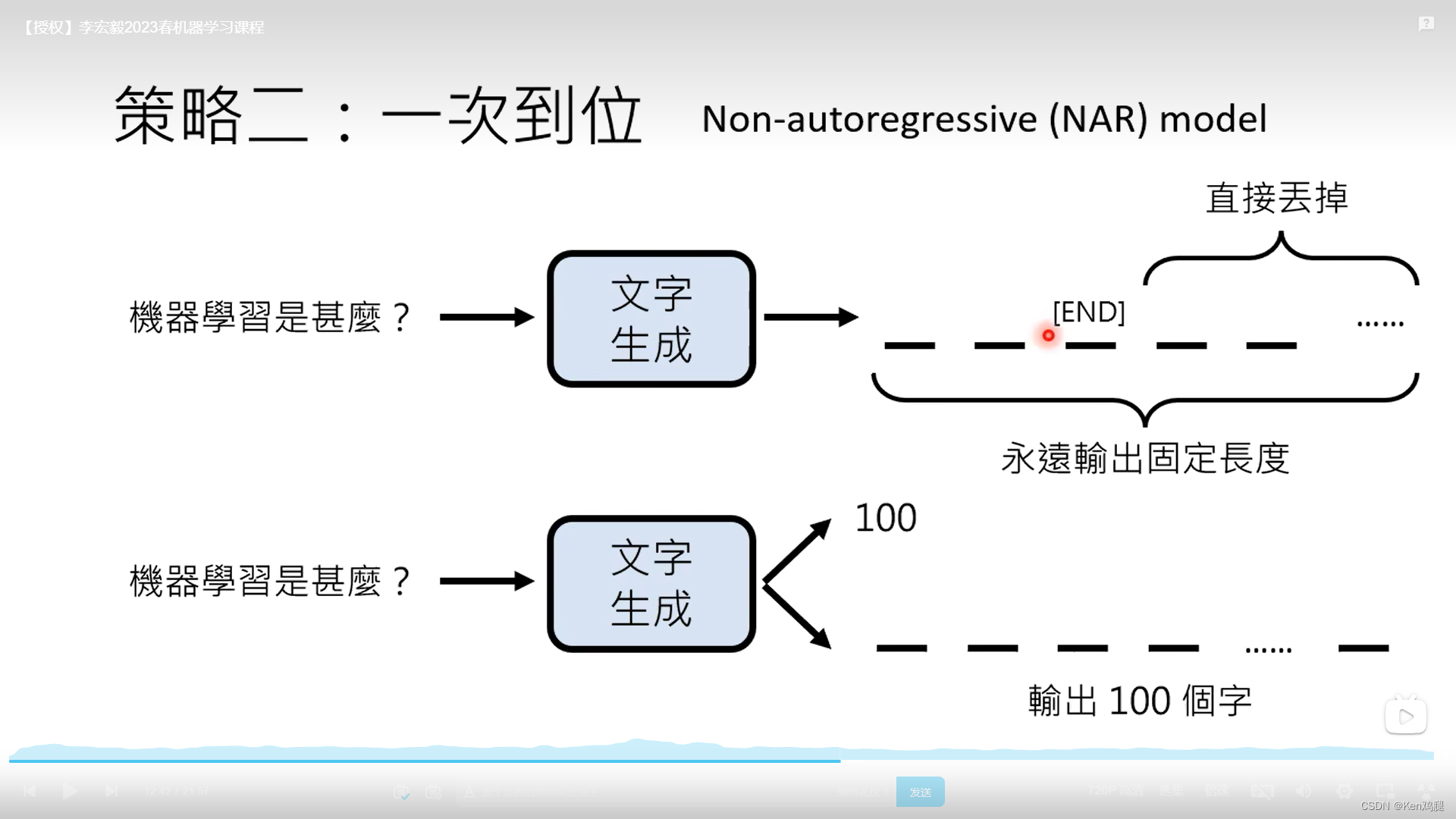
一次到位:
1.永远输出固定的长度,内容输出完后end后的内容就会被丢掉
2.每次先输出字数,根据这个字数做输出
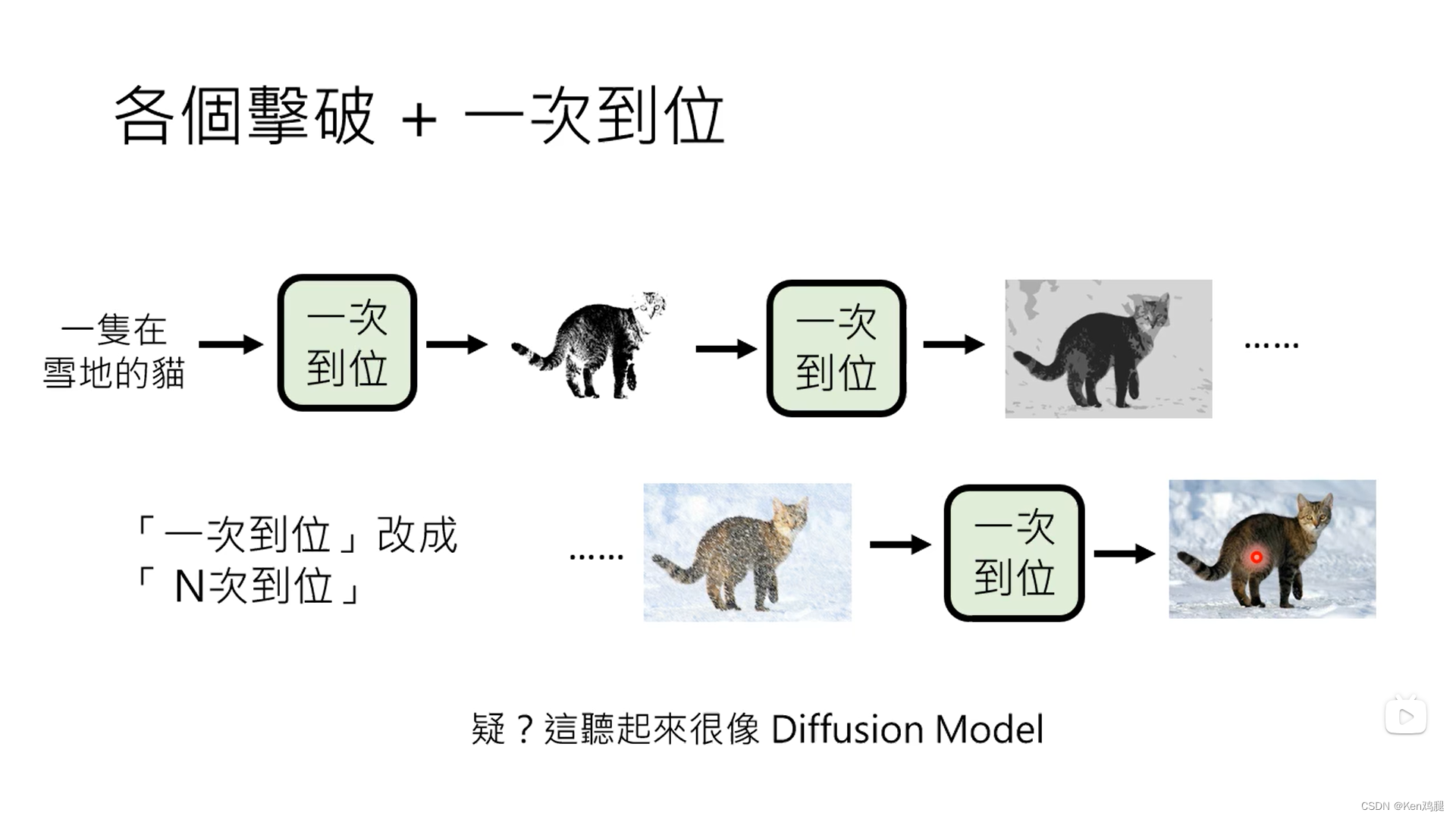
但是对于图片而言,逐个击破速度太慢了,有没有综合一次到位和逐个击破的优势的方式呢,当然是有的
1.比如声音,就可以通过逐个击破的方式获取向量,决定大的方向,再通过一次到位来生成取样点

2.通过N次到位的方式来逐步的达到最终的效果,这也是Stable diffusion model所用的方法
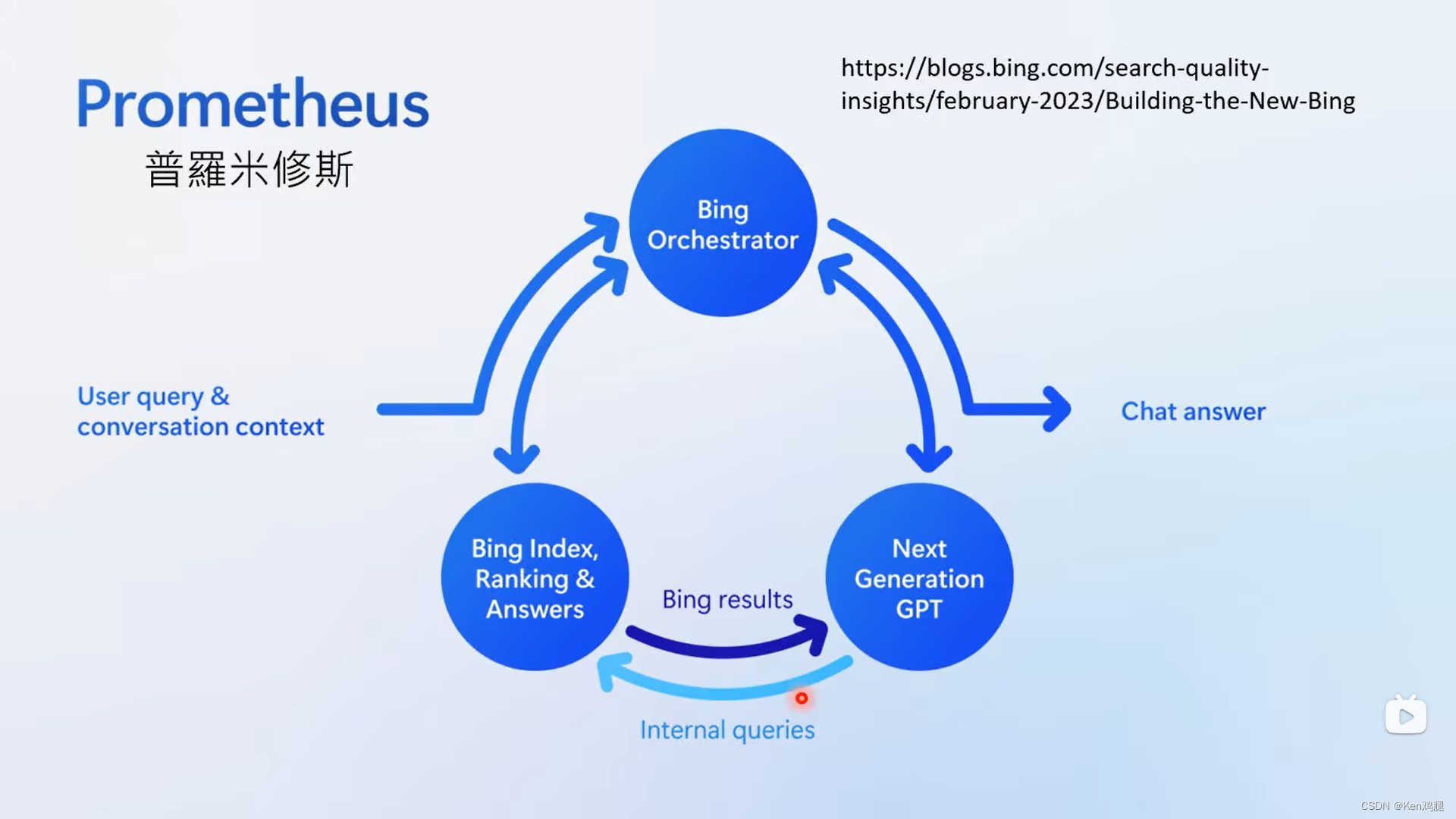
能够使用工具的AI
1.new bing的介绍
和new bing比较相似的是WebGPT
搜索引擎其实用到的方式也是文字接龙的方式,通过搜索网上的内容,截取其中的一部分内容收藏,再继续搜寻下一段内容,收藏,当它收藏到足够数量的内容后,就可以回答人们提出的问题了。

WebGPT和ChatGPT还是比较类似的,首先是预训练,然后人类老师会告诉它人类的思考方式是怎样的,按照人类的方式进行下一步。接下来就是打分,给到WebGPT进行强化学习。

Toolformer对应了很多工具,字文字接龙的时候也可以用到工具帮助生成内容。

1.是通过few shot的方式来让机器产生大量的资料来训练文字接龙。

2.进行验证两个模型生成的结果,首先看看第一次调用模型生成正确答案的几率,在验证要使用模型生成的效果不错,就把这个调用指令留下来。
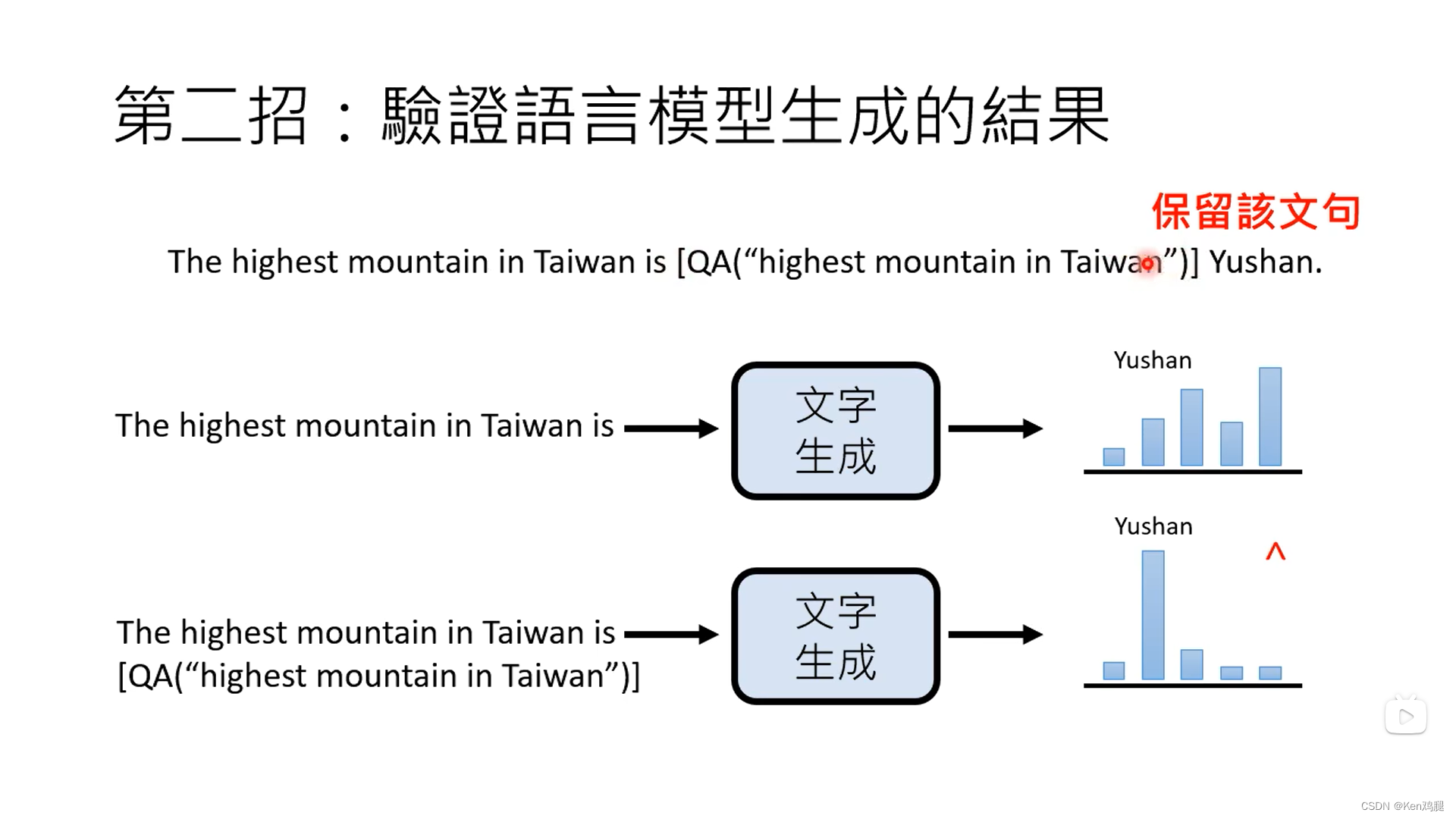
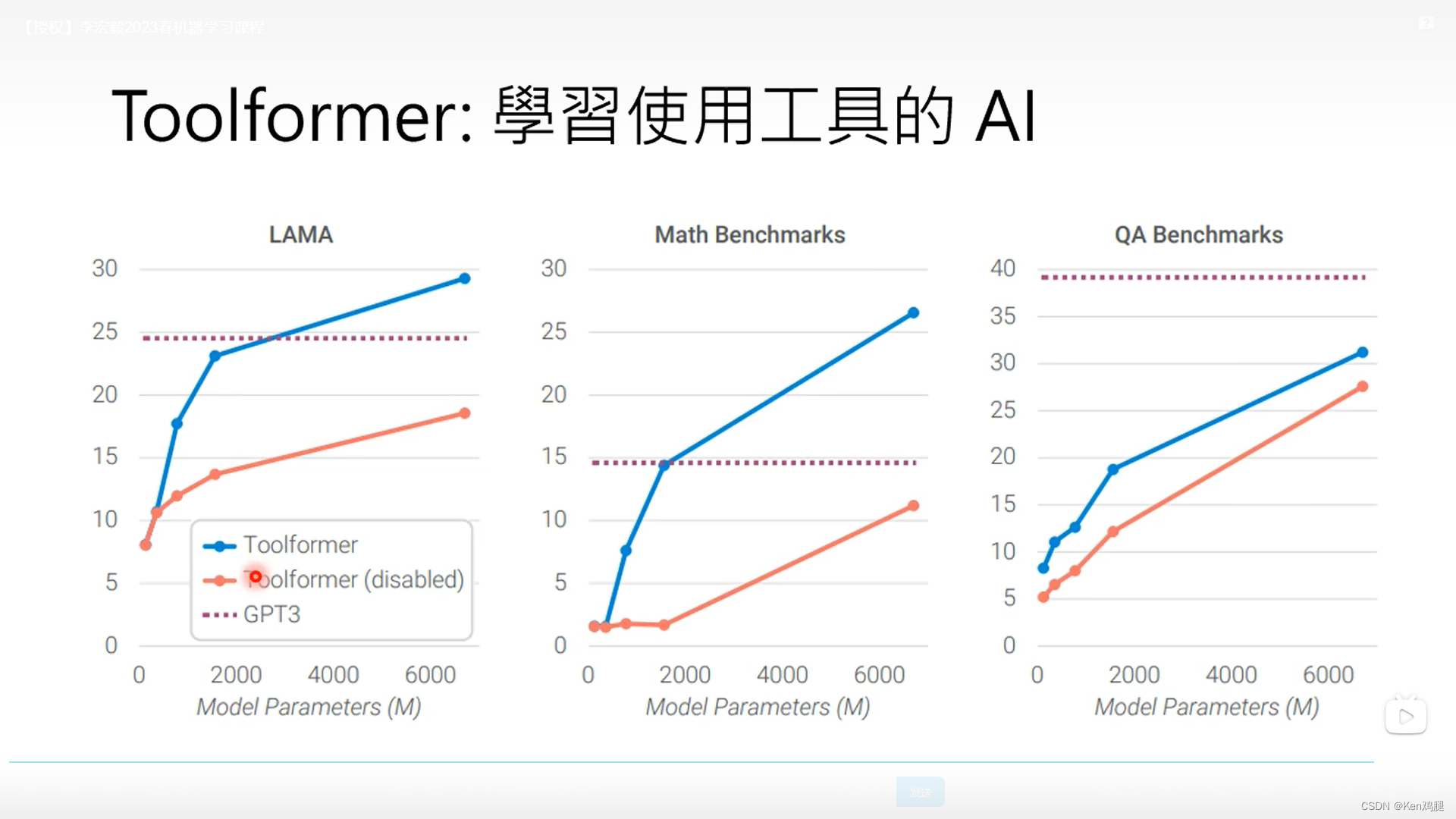
3.这里有测试数据,使用了toolformer和没有用toolformer以及gpt3的效果,在小模型中,模型不能理解这种调用方式,效果获取不太好。在使用成功了toolformer的效果显然会比没有使用上toolformer的效果好。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









