







在上一篇博客最后,我们说到了
θ
\theta
θ和
θ
′
\theta'
θ′是不能差太多的,不然结果会不好,那么怎么避免它们差太多呢?
这就是这一篇要介绍的PPO所在做的事情。
摘要:
PPO在原目标函数的基础上添加了KL divergence 部分,用来表示两个分布之前的差别,差别越大则该值越大。那么施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较大的目标函数。
TRPO 与 PPO 之间的差别在于它使用了 KL divergence(KL散度) 作为约束,即没有放到式子里,而是当做了一个额外的约束式子,这就使得TRPO的计算非常困难,因此较少使用。

这里要注意这个 KL divergence并不是参数之间的距离,而是actions之间的距离。
一、PPO算法原理
1、算法步骤
大概可分为以下三步:
1、初始化policy的参数
θ
0
\theta^0
θ0
2、在每一次迭代中,使用
θ
k
\theta^k
θk来和环境互动,收集状态和行动并计算对应的advantage function
3、不断更新参数,找到目标函数最优值对应的参数
θ
\theta
θ

2、适应性的KL惩罚因子
在训练的过程中采用适应性的KL惩罚因子:
当KL过大时,增大beta值来加大惩罚力度
当KL过小时,减小beta值来降低惩罚力度
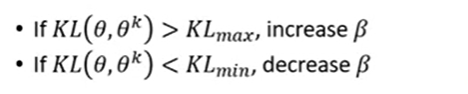
二、PPO2算法思想
PPO2不使用KL散度,而是利用一个clip函数来保证
θ
\theta
θ和
θ
k
\theta^k
θk的差异不大。
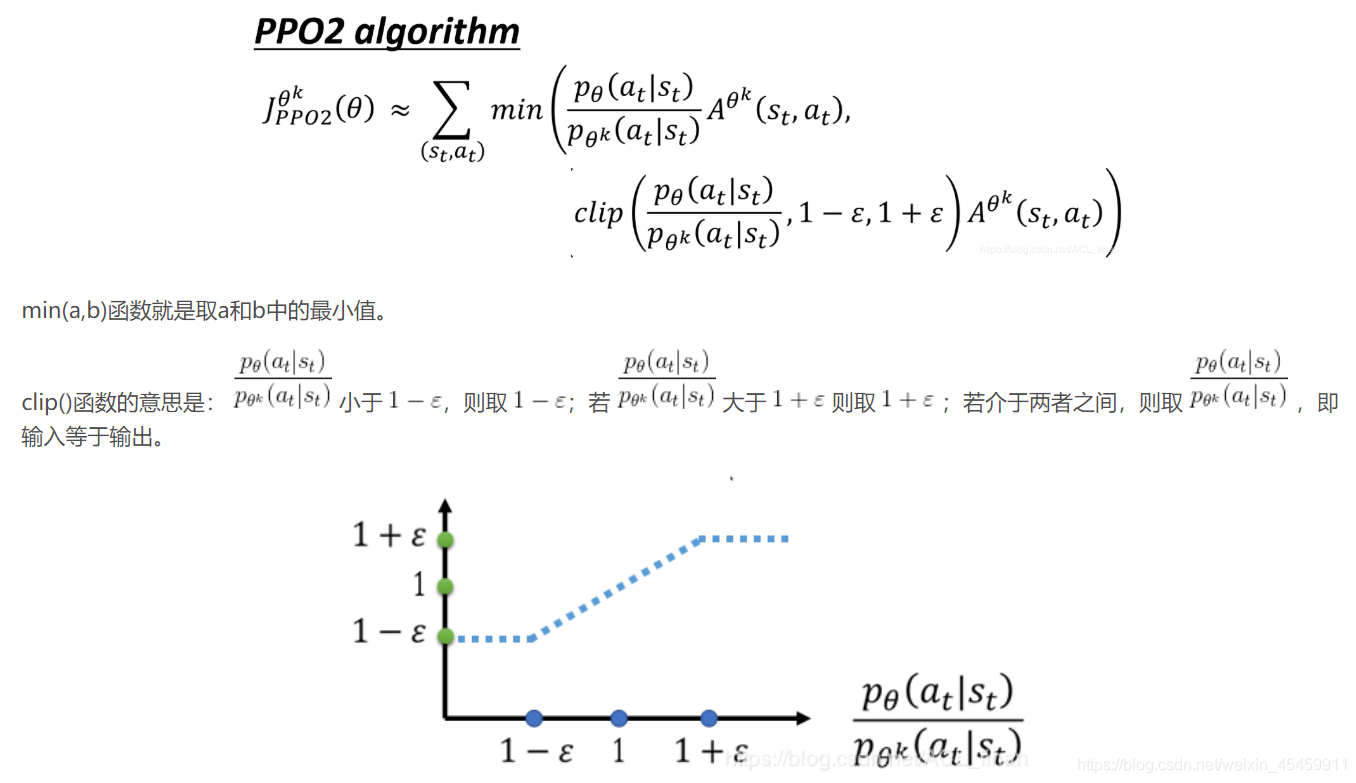
PPO2通过引入了Clip函数,使第二项,即蓝色的虚线必须在 1-
ϵ
\epsilon
ϵ 和1+
ϵ
\epsilon
ϵ之间。
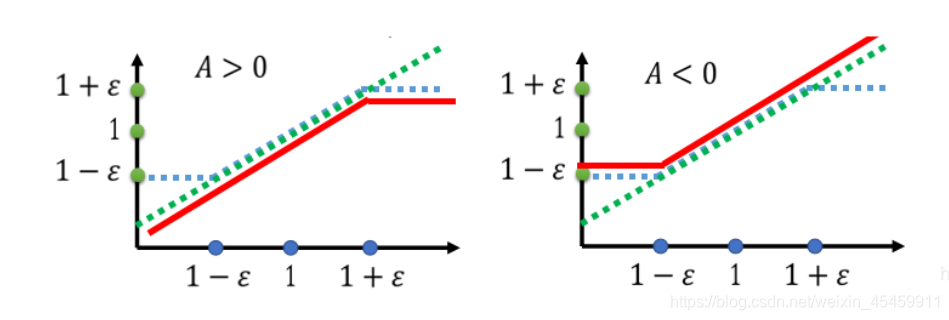
分析一下上面的图片:
红色的线表示取最小值之后整个函数值分布情况。
当A>0时,鼓励其多做这个动作,即增大
P
θ
(
a
t
∣
s
t
)
P_\theta(a_t|s_t)
Pθ(at∣st),横轴向右移动,红色的线会慢慢上升,但是最大不能让其超过1+
ϵ
\epsilon
ϵ,这就保证了
θ
\theta
θ和
θ
k
\theta^k
θk不会相差太大。
当A<0时,惩罚其少做这个动作,即减小
P
θ
(
a
t
∣
s
t
)
P_\theta(a_t|s_t)
Pθ(at∣st),横轴向左移动,红色的线会慢慢下降,但是最小不能让其小于1-
ϵ
\epsilon
ϵ,这就保证了
θ
\theta
θ和
θ
k
\theta^k
θk不会相差太大。
参考:
https://blog.csdn.net/cindy_1102/article/details/87905272
https://blog.csdn.net/ACL_lihan/article/details/103989581

















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









