







Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks
PRE
系统模型
- 由一个Access Point和N个fixed Wireless Devices组成的 MEC network,表示为集合 N = { 1 , 2 , … , N } \mathcal{N}=\{1,2,\dots,N\} N={1,2,…,N}
- 每个设备实现时分复用(Time-division-multiplexing)电路,避免无线电传输和通信之间的干扰
- 系统时间被划分为长度相等的连续时间帧 T T T
- 每个标记时间,无线设备从接入点获取的能量 和 它们之间的通信速度 都与无线信道增益有关
- 在一个时间帧的开始, a T aT aT 的时间量用于无线电传输,这里 a ∈ [ 0 , 1 ] a \in [0,1] a∈[0,1]
- 第
i
i
i 个无线设备收获能量:
E i = μ P h i a T E_i=\mu Ph_iaT Ei=μPhiaT- μ ∈ ( 0 , 1 ) \mu \in (0,1) μ∈(0,1):能量收集效率
- P P P:接入点发射功率
- h i h_i hi:接入点和无线设备 i i i之间的无线信道增益
- 每个无线设备利用获得的能量,需在一个时间帧结束之前完成一个计算任务
- w i w_i wi:分配给无线设备 i i i的权重;它越大,分配给设备 i i i的计算速率就越大
- 本文考虑一个二进制卸载策略,这个任务要么在设备本地计算,要么卸载到Access Point执行计算
-
x
i
=
1
x_i=1
xi=1表示
u
s
e
r
i
user_i
useri将计算任务卸载到Access Point
x i = 0 x_i=0 xi=0表示任务在本地执行计算
本地计算模式
-
本地计算模式下的无线设备可同时获取能量和执行计算任务
-
无线设备处理的比特数: f i t i / ϕ f_it_i/\phi fiti/ϕ
- f i f_i fi:无线设备 i i i CPU计算速度(cycles / 秒)
- t i t_i ti:无线设备 i i i计算时间, 0 ≤ t i ≤ T 0\leq t_i \leq T 0≤ti≤T
- ϕ \phi ϕ:处理1bit任务数据所需的cycles, ϕ > 0 \phi>0 ϕ>0
-
由于计算而产生的能量消耗受 k i f i 3 t i ≤ E i k_if^3_it_i\leq E_i kifi3ti≤Ei的约束
- k i k_i ki:计算能效系数
-
本地计算速率(bits/秒):
r L , a ∗ ( a ) = f i ∗ t i ∗ ϕ T = η ( h i κ i ) 1 3 a 1 3 r^*_{L,a}(a)=\frac{f_i^*t_i^*}{\phi T}=\eta(\frac{h_i}{\kappa_i})^{\frac{1}{3}}a^{\frac{1}{3}} rL,a∗(a)=ϕTfi∗ti∗=η(κihi)31a31
固定参数: η 1 ≜ ( μ P ) 1 3 / ϕ \eta_1 \triangleq(\mu P)^{\frac{1}{3}}/\phi η1≜(μP)31/ϕ
边缘计算模式
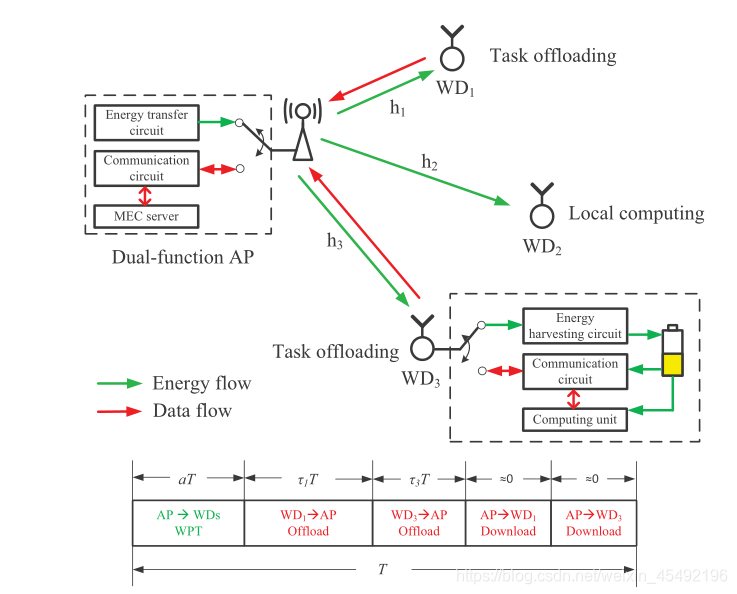
- 由于时分复用的约束,处于卸载模式的无线设备只能在获取能量后将任务卸载到Access Point
- τ i T \tau_iT τiT:设备 i i i 的卸载时间。 τ i ∈ [ 0 , 1 ] \tau_i\in [0,1] τi∈[0,1]
- 本文假定 Access Point的计算速度&传输功率远大于大小及资源受限的无线设备(超过三个数量级)
- 下载到无线设备的结果反馈比数据卸载到边缘服务器的时间要短得多
- 如图所示,我们安全地忽略AP在任务计算和下载上花费的时间,有:
∑ i = 1 N τ i + a ≤ 1 \sum_{i=1}^N\tau_i+a\leq1 i=1∑Nτi+a≤1 - 为了最大化计算速率,设备在任务卸载时耗尽其收获的能量,即 P i ∗ = E i τ i T P^*_i=\frac{E_i}{\tau_iT} Pi∗=τiTEi
- 计算速率:
r
O
,
i
∗
(
a
,
τ
i
)
=
B
τ
i
v
u
l
o
g
2
(
1
+
μ
P
a
h
i
2
τ
i
N
0
)
r^*_{O,i}(a,\tau_i)=\frac{B\tau_i}{v_u}log_2(1+\frac{\mu Pah^2_i}{\tau_iN_0})
rO,i∗(a,τi)=vuBτilog2(1+τiN0μPahi2)
B B B:通信带宽
N 0 N_0 N0:接收器噪声功率
问题建模
- 两种计算模式的所有系统参数中,假定只有无线信道增益 h = { h i ∣ i ∈ N } h=\{h_i|i\in \mathcal{N}\} h={hi∣i∈N}是时变的,其他是固定参数
- 在一个标记时间帧中,无线电MEC网络的加权和计算速率:
Q
(
h
,
x
,
τ
,
a
)
≜
∑
i
=
1
N
ω
i
(
(
1
−
x
i
)
r
L
,
a
∗
(
a
)
+
x
i
r
O
,
i
∗
(
a
,
τ
i
)
)
Q(\mathbf{h},\mathbf{x},\mathbf{\tau},a)\triangleq \sum_{i=1}^N\omega_i((1-x_i)r^*_{L,a}(a)+x_ir^*_{O,i}(a,\tau_i))
Q(h,x,τ,a)≜i=1∑Nωi((1−xi)rL,a∗(a)+xirO,i∗(a,τi))
x = { x i ∣ i ∈ N } \mathbf{x}=\{x_i|i\in \mathcal{N}\} x={xi∣i∈N}
τ = { τ i ∣ i ∈ N } \mathbf{\tau}=\{\tau_i|i\in \mathcal{N}\} τ={τi∣i∈N}

-
如果无线设备 i i i本地计算,即 x i = 0 x_i=0 xi=0,可以推断: τ i = 0 \tau_i=0 τi=0
-
问题P1是一个很难求解的MIP非凸问题,然而一旦给定 x \mathbf{x} x,问题P1就减化为一个如下所示凸问题:
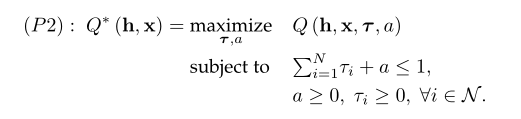
-
因此问题P1可分解为两个子问题,即卸载决策 & 资源分配
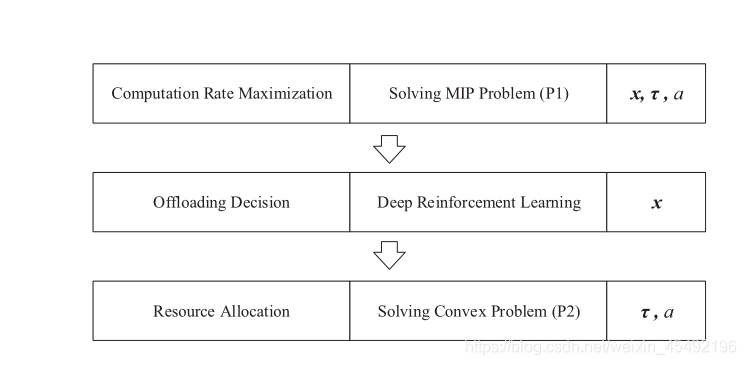
- 卸载决策: 需要在
2
N
2^N
2N个可能的卸载决策中进行搜索,以找到 最优 或 满意的次优 卸载决策
x
\mathbf{x}
x;
例如提出的元启发式搜索算法来优化卸载决策,然而算法收敛时间很长(因为搜索空间是指数级的) - 资源分配: 凸问题P2的最优时间分配 { a ∗ , τ ∗ } \{a^*,\tau^*\} {a∗,τ∗}可有效地解决。例如,使用一维二分搜索(时间复杂度 O ( N ) O(N) O(N))
- 卸载决策: 需要在
2
N
2^N
2N个可能的卸载决策中进行搜索,以找到 最优 或 满意的次优 卸载决策
x
\mathbf{x}
x;
-
当前求解P1的主要困难在于卸载决策问题
-
传统的优化算法需要迭代调整卸载决策,使其趋于最优,这对于快速衰落信道下的实时系统优化是不可行的
-
为了解决复杂度问题,本文提出了一种基于深度强化学习的在线卸载(DROO)算法,该算法可在求解卸载决策问题时达到ms级的计算问题
DROO ALGORITHM
The policy is denoted as:
π
:
h
↦
x
∗
\pi:\mathcal{h}\mapsto x^*
π:h↦x∗
DROO算法从经验中逐渐学习到这样的策略函数
π
\pi
π。
算法概述
- 结构:
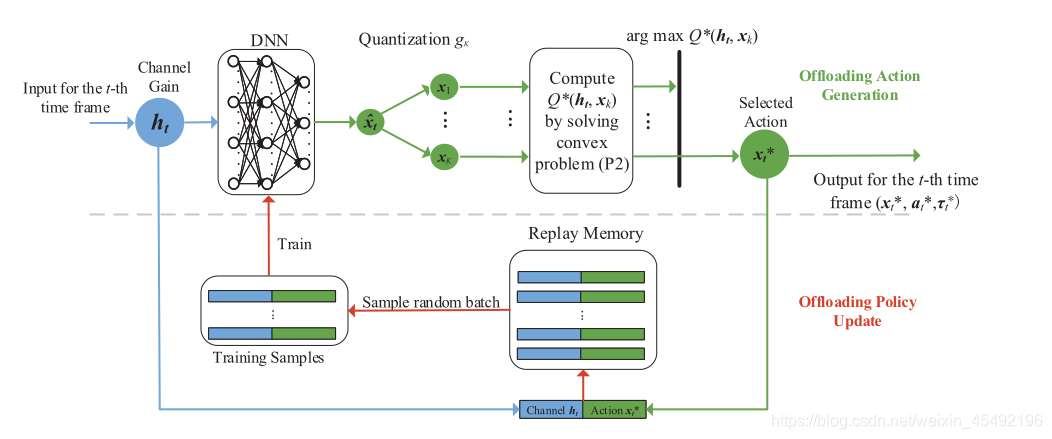
- 由两个交替的阶段组成:卸载动作生成 & 卸载策略更新
- 卸载动作的产生依赖于深度神经网络,深度神经网络的特征在于其嵌入参数 θ \theta θ,例如连接隐藏神经元的权重
- 第 t t t个时间帧,深度神经网络将信道增益 h t h_t ht作为输入,并基于由 θ t \theta_t θt参数化的其当前卸载策略 π θ t \pi_{\theta_t} πθt输出卸载动作 x ^ t \hat{x}_t x^t
- 然后松弛动作量化为K个二进制卸载动作,其中根据问题P2中的可实现计算速率选择一个最佳动作 x t ∗ x_t^* xt∗
- 相应的 { x t ∗ , a t ∗ , τ t ∗ } \{\mathbf{x}^*_t,a^*_t,\tau^*_t\} {xt∗,at∗,τt∗}作为 h t h_t ht的解被输出,这保证了上述的物理约束得到满足
- 网络执行卸载动作 x t ∗ x^*_t xt∗,得到奖励 Q ∗ ( h t , x t ∗ ) Q^*(\mathbf{h}_t,x^*_t) Q∗(ht,xt∗),并将新获得的状态-动作对 ( h t , x t ∗ ) (\mathbf{h}_t,x^*_t) (ht,xt∗)添加到重放存储器(replay memory)
- 随后,在第 t t t时间帧的策略更新阶段,从存储器中提取一批训练样本来训练DNN,DNN相应地更新参数 θ t \theta_t θt to θ t + 1 \theta_{t+1} θt+1 (相当于卸载策略 π θ t + 1 \pi_{\theta_{t+1}} πθt+1)
- 新的卸载策略 π θ t + 1 \pi_{\theta_{t+1}} πθt+1用于下一时间帧中,根据观测到的新信道 h t + 1 h_{t+1} ht+1生成卸载决策 x t + 1 ∗ x^*_{t+1} xt+1∗
- 重复迭代,深度神经网络的策略 π θ t \pi_{\theta_t} πθt 逐渐改进
卸载动作生成
- 假定在 t t t时刻观察信道增益 h t h_t ht,这里 t = 1 , 2 , … t=1,2,\dots t=1,2,…
- t = 1 t=1 t=1时,深度神经网络 θ t \theta_t θt的参数按照零均值正态分布随机初始化
- 深度神经网络首先输出一个松弛计算卸载动作 x ^ t \hat{x}_t x^t,由参数化函数 x ^ t = f θ t ( h t ) \hat{x}_t=f_{\theta_t}(\mathbf{h}_t) x^t=fθt(ht)。这里 x ^ t = { x ^ t , i ∣ x ^ t , i ∈ [ 0 , 1 ] , i = 1 , … , N } \hat{x}_t=\{\hat{x}_{t,i}|\hat{x}_{t,i}\in [0,1],i=1,\dots,N\} x^t={x^t,i∣x^t,i∈[0,1],i=1,…,N}
- 著名的通用逼近定理声明,如果在神经元上应用适当的激活函数,例如sigmoid、ReLu和tanh函数,一个具有足够隐藏神经元的隐藏层足以逼近任何连续映射 f f f
- 这里使用ReLu作为隐藏层的激活函数,其中神经元的输出 y y y和输入 v v v与 y = m a x { v , 0 } y=max\{v,0\} y=max{v,0}相关
- 在输出层使用sigmoid激活函数,即 y = 1 / ( 1 + e − v ) y=1/(1+e^{-v}) y=1/(1+e−v),使得松弛卸载动作满足 x ^ t , i ∈ ( 0 , 1 ) \hat{x}_{t,i}\in(0,1) x^t,i∈(0,1)
- 然后,量化 x ^ t \hat{x}_t x^t以获得 K K K个二进制卸载动作
- 量化函数 g K g_{K} gK: g K : x ^ t ↦ { x k ∣ x k ∈ { 0 , 1 } N , k = 1 , … , K } g_K:\hat{x}_t\mapsto \{\mathbf{x}_k|\mathbf{x}_k\in\{0,1\}^N,k=1,\dots,K\} gK:x^t↦{xk∣xk∈{0,1}N,k=1,…,K}
- K K K可以是 [ 1 , 2 N ] [1,2^N] [1,2N]的任何整数,较大的 K K K导致更好的解质量、更高的计算复杂度,反之亦然
- 为平衡性能和复杂度,提出了一个保序量化方法,这里
K
K
K值设置为1到N+1;基本思想是在量化过程中保持有序性
- 第一个二进制卸载决策
x
1
\mathbf{x}_1
x1
x 1 , i = { 1 x ^ t , i > 0.5 , 0 x ^ t , i ≤ 0.5 , x_{1,i}= \begin{cases} 1 \qquad &\hat{x}_{t,i}\gt0.5,\\ 0 \qquad &\hat{x}_{t,i}\leq0.5, \end{cases} x1,i={10x^t,i>0.5,x^t,i≤0.5,
for i = 1 , … , N . i=1,\dots,N. i=1,…,N. - 为了生成剩余
K
−
1
K-1
K−1个动作,首先对
x
^
t
\hat{x}_t
x^t的条目进行排序,其各自的距离为
0.5
0.5
0.5
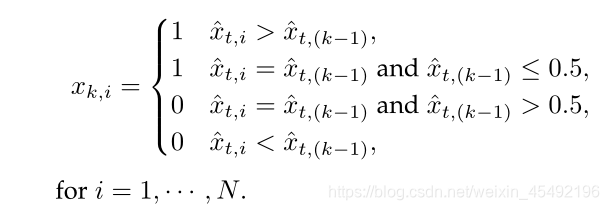
- 第一个二进制卸载决策
x
1
\mathbf{x}_1
x1
- 后面小节会提到在每个时间帧中生成大量量化动作不仅效率低下,而且没有必要;相反,设置一个小 K K K(甚至接近于1)经过足够长的训练周期足以获得良好的计算速率性能和低复杂度
- 每个候选动作 x k \mathbf{x}_k xk通过求解问题P2来实现 Q ∗ ( h t , x k ) Q^*(\mathbf{h}_t,\mathbf{x}_k) Q∗(ht,xk)计算速率;
- 因此,在 t t t时刻,最佳卸载动作 x t ∗ = arg max x i ∈ { x k } Q ∗ ( h t , x k ) \mathbf{x}_t^*=\arg\max_{\mathbf{x}_i\in\{\mathbf{x}_k\}}Q^*(\mathbf{h}_t,\mathbf{x}_k) xt∗=argxi∈{xk}maxQ∗(ht,xk)
卸载策略更新
- 上式得到的卸载方案将用于更新深度神经网络的卸载策略
- 具体来说,我们保持一个最初容量有限的memory,在 t t t时间,将新的训练数据样本 ( h t , x t ∗ ) (\mathbf{h}_t,\mathbf{x}_t^*) (ht,xt∗)添加到memory。当memory已满时,新生成的数据样本替换最旧的数据样本
- 使用经验回放技术,


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









