







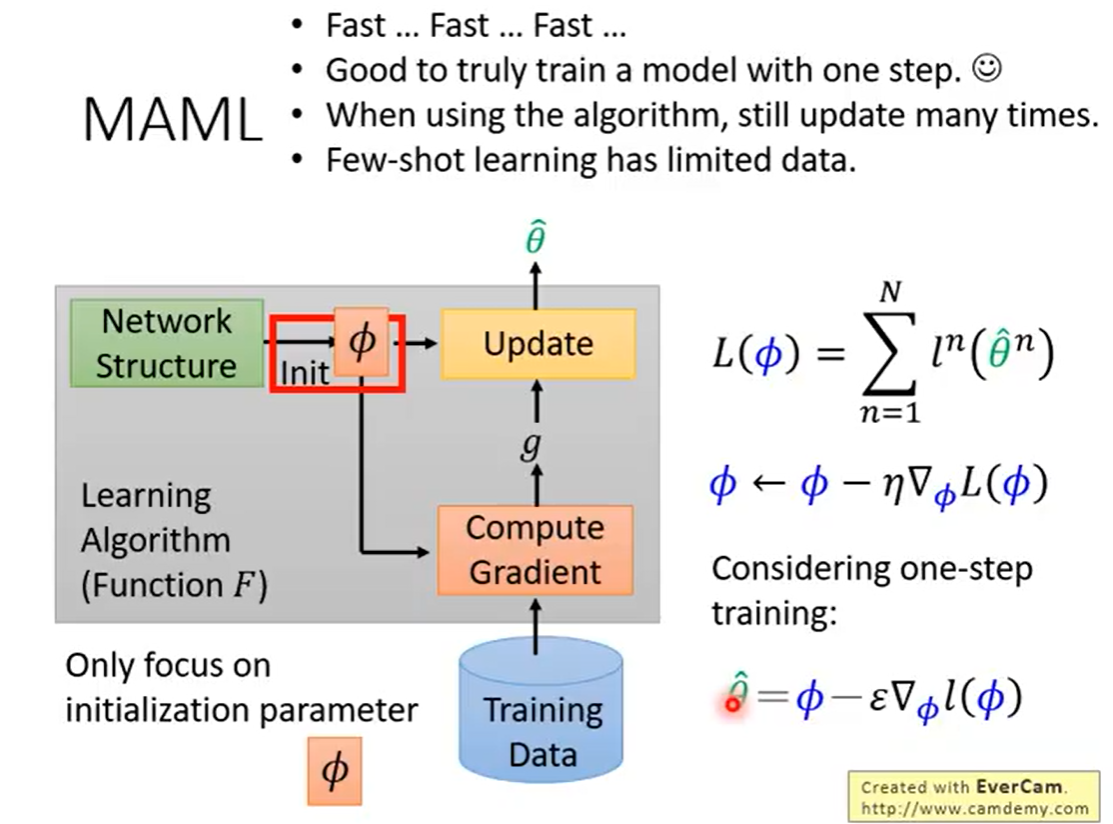
Meta learning
Meta learning 基本定义
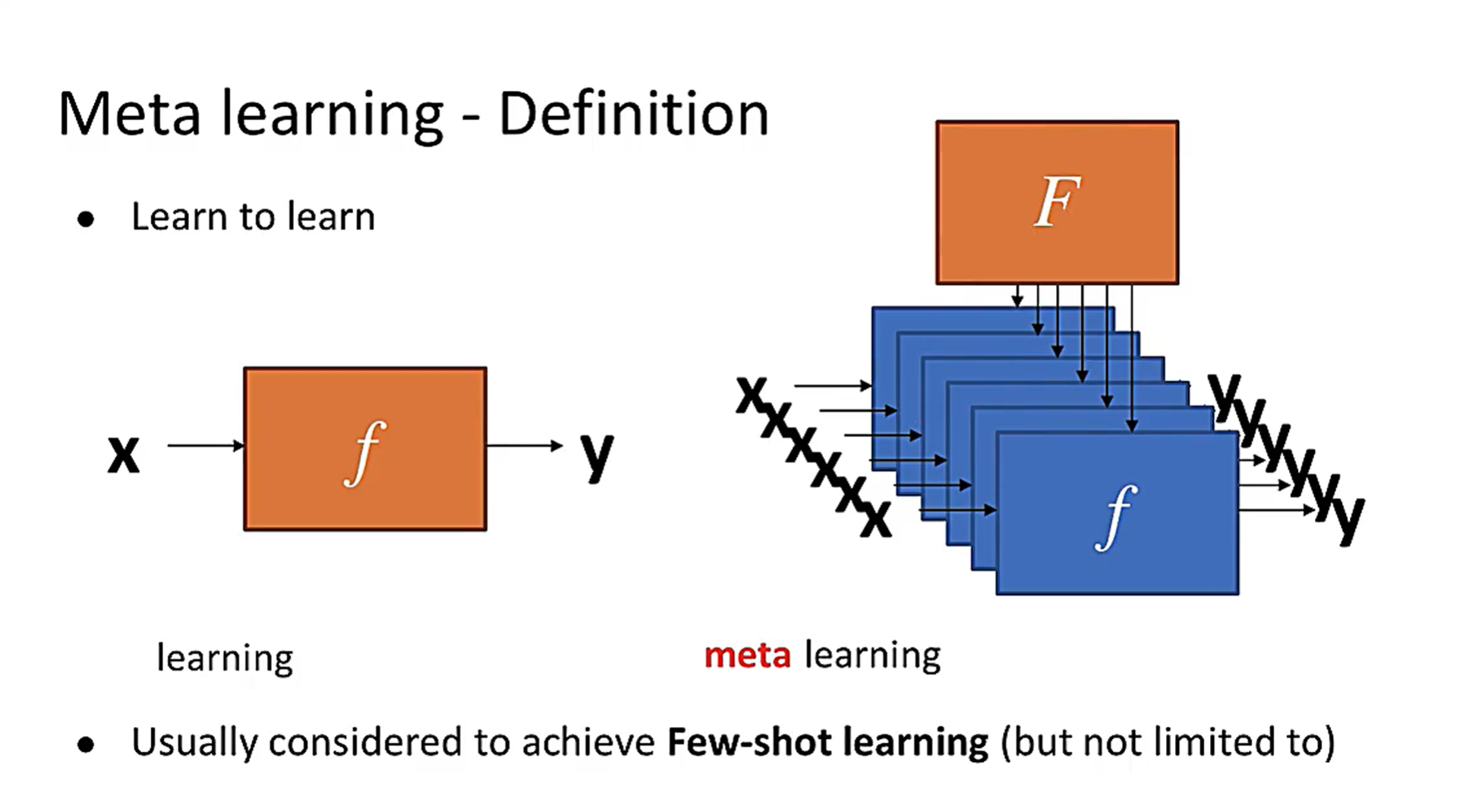
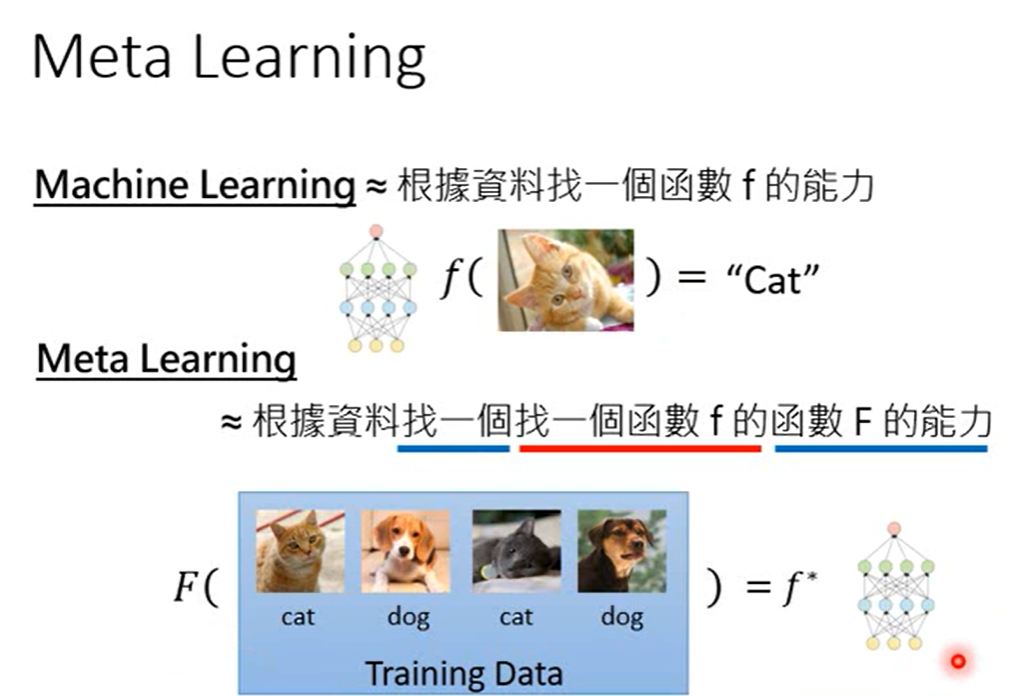
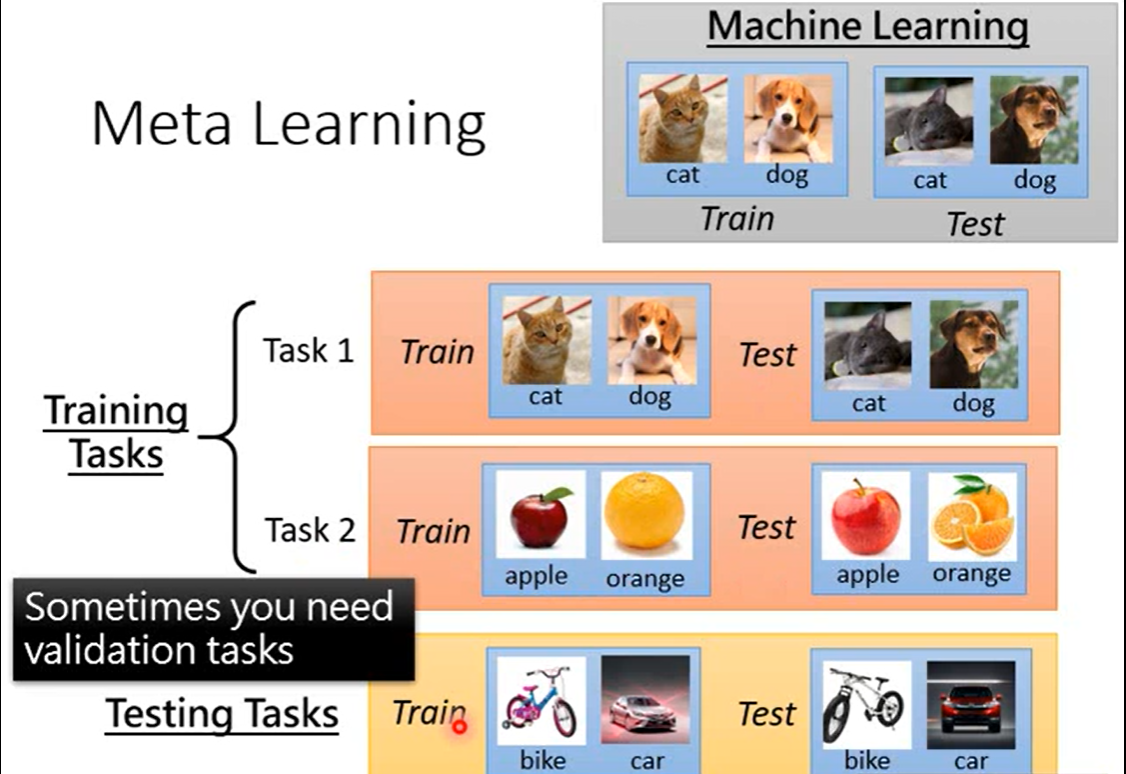
元学习:又称“学习如何学习”,就像我们人类学习新知识往往从以往得经验出发而很少从头开始一样,元学习以一种系统得、数据驱动得方式从先前得经验中学习,是一个可用于描述所以基于其他先前任务经验来学习的方法的概念。学习学习的方法
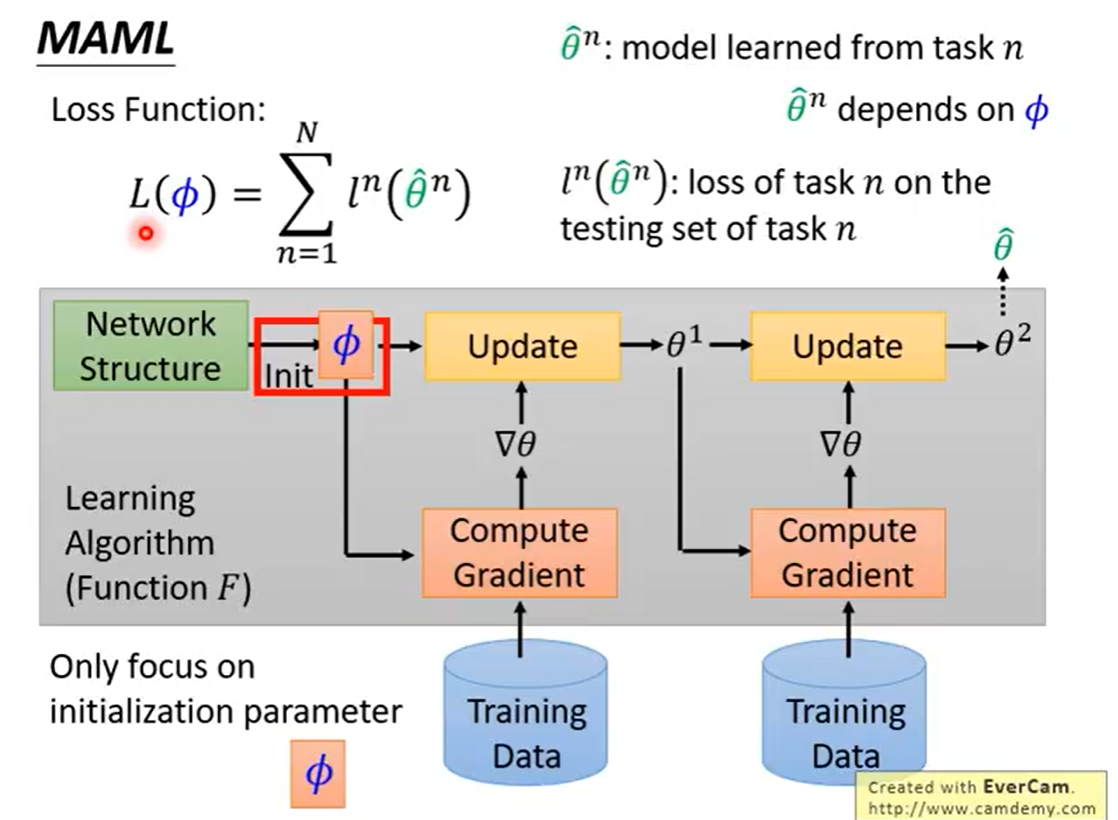
MAML and Model Pre-training
区别:
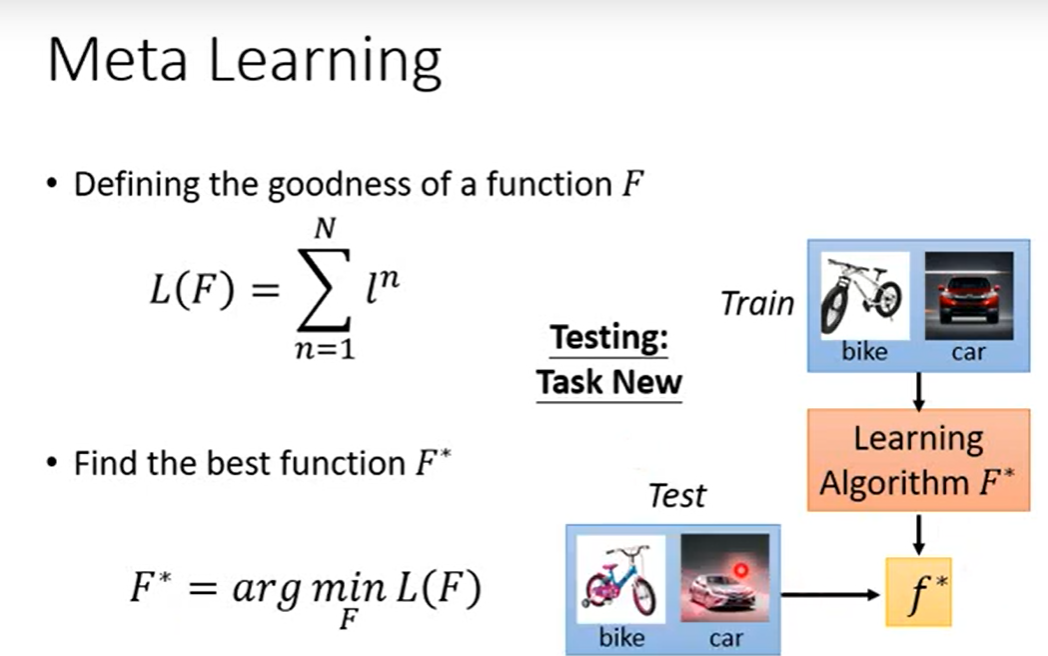
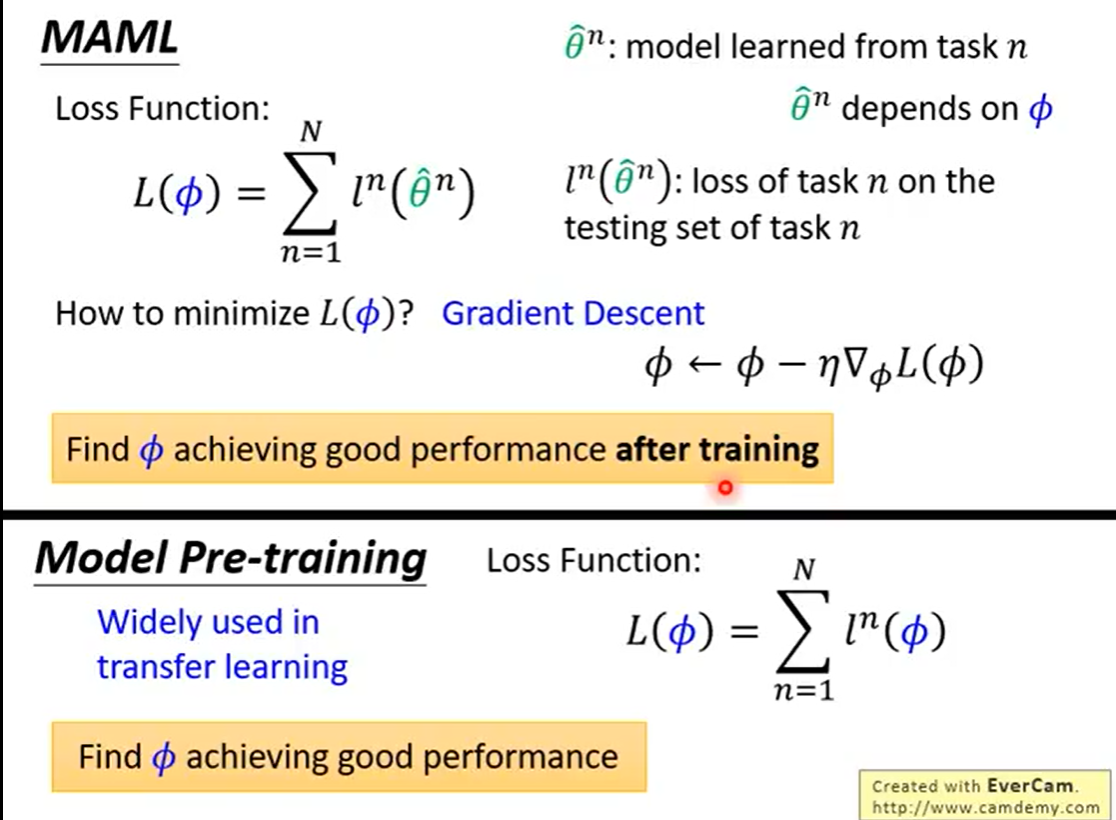
MAML:MAML的loss是训练后的结果在评估模型上计算得到
Pre-training:loss在预训练上的模型上计算的
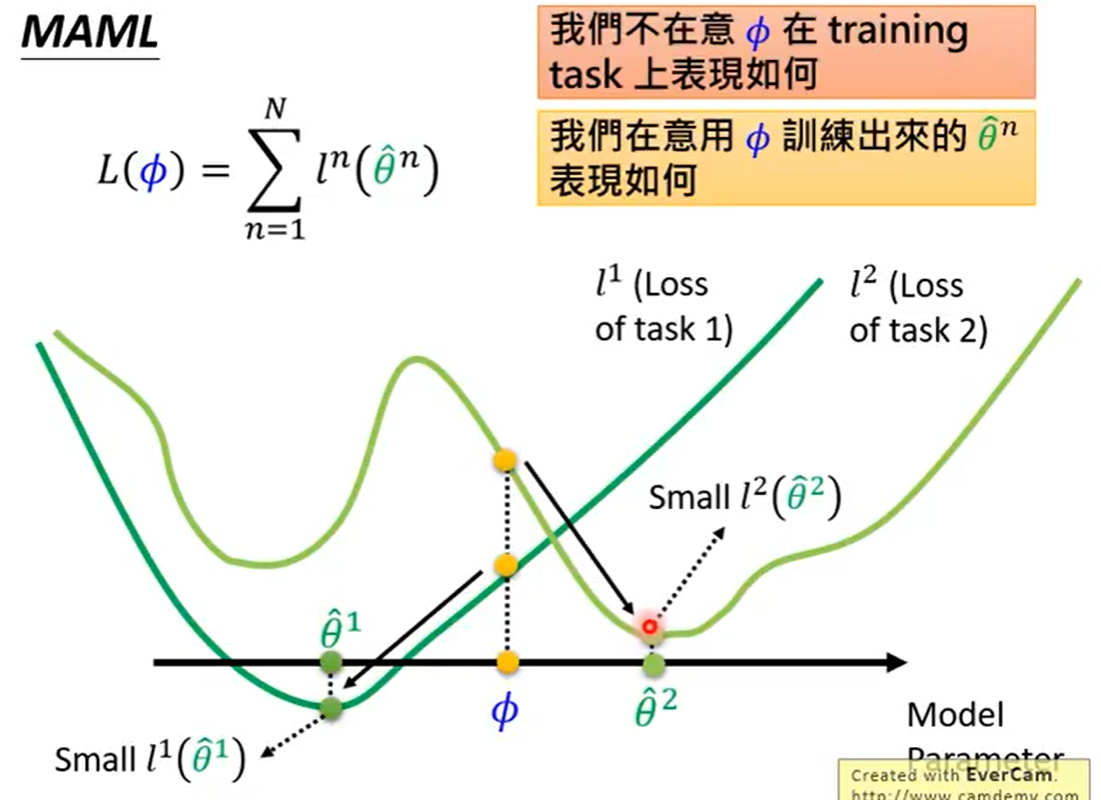
为了进一步区分两者,MAML在意训练后KaTeX parse error: Undefined control sequence: \thea at position 6: \hat{\̲t̲h̲e̲a̲}^{n}表现得好,如图处,对task1和task2都下降很快
MAML:
-
MAML注重找到一个任务最优点,对于所有的任务都能较快收敛,关注于潜力都不关注于此时任务上的收敛情况
-
在MAML中找到的 ϕ \phi ϕ在task1上不是全局最优解,但是他在两个任务上都下降很快
Pre-training: -
预训练在训练任务上找最优,收敛
-
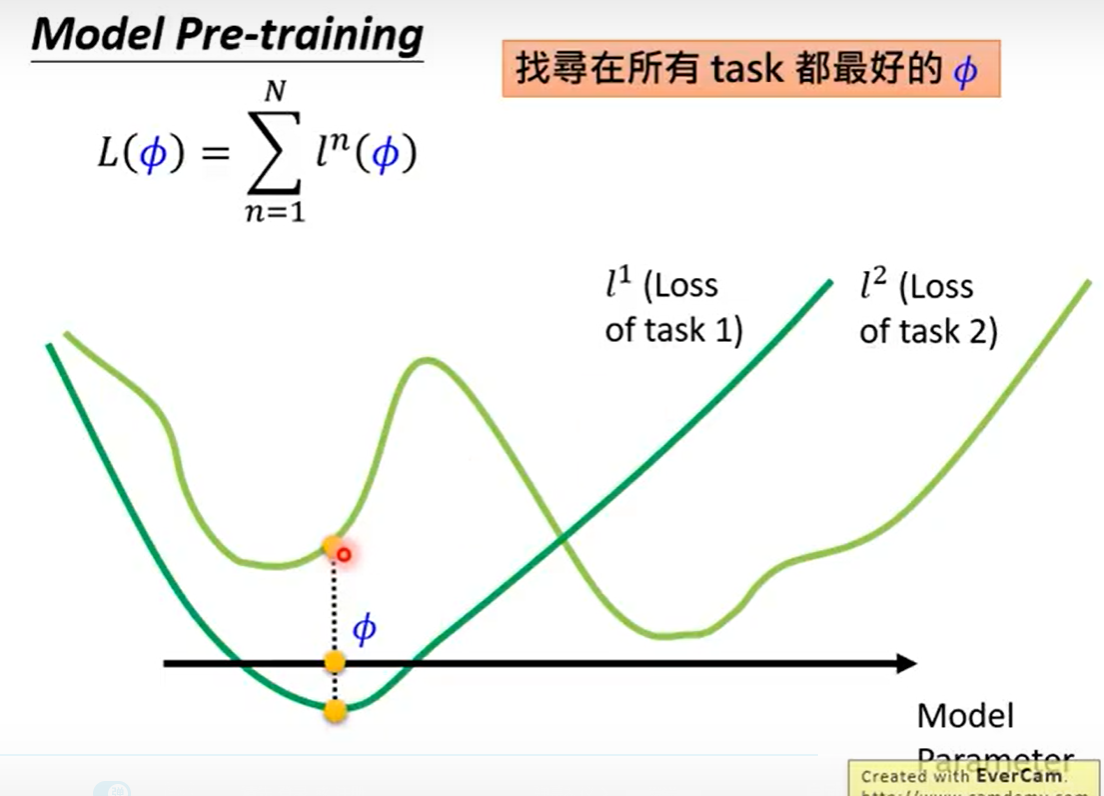
在Pre-training在task1上找到全局最优作为初始值可能就在task2上陷入局部最优
在图中Model Pre-training在所有task上都最好
两者就像刚毕业学生一样,Model Pre-training就是直接毕业工作拿工资,对于当前是很好,MAML相当于去读博,有了高学历对于以后发展会很好。
Example

可以看到
- Model Pre-training,学习到的网络初始参数预测出来的是绿色曲线,找到不同的sin函数上都好的,而不同sin函数叠加起来波峰与波谷抵消,为了使每个任务上都好最后得到一条近乎水平的线,所以用transfering learning在新任务上用这几个点迭代几次依然不好
- 而MAML学习到了初始参数预测有一些波动,在经过几个训练点上几次迭代很快就能拟合到橙色曲线。
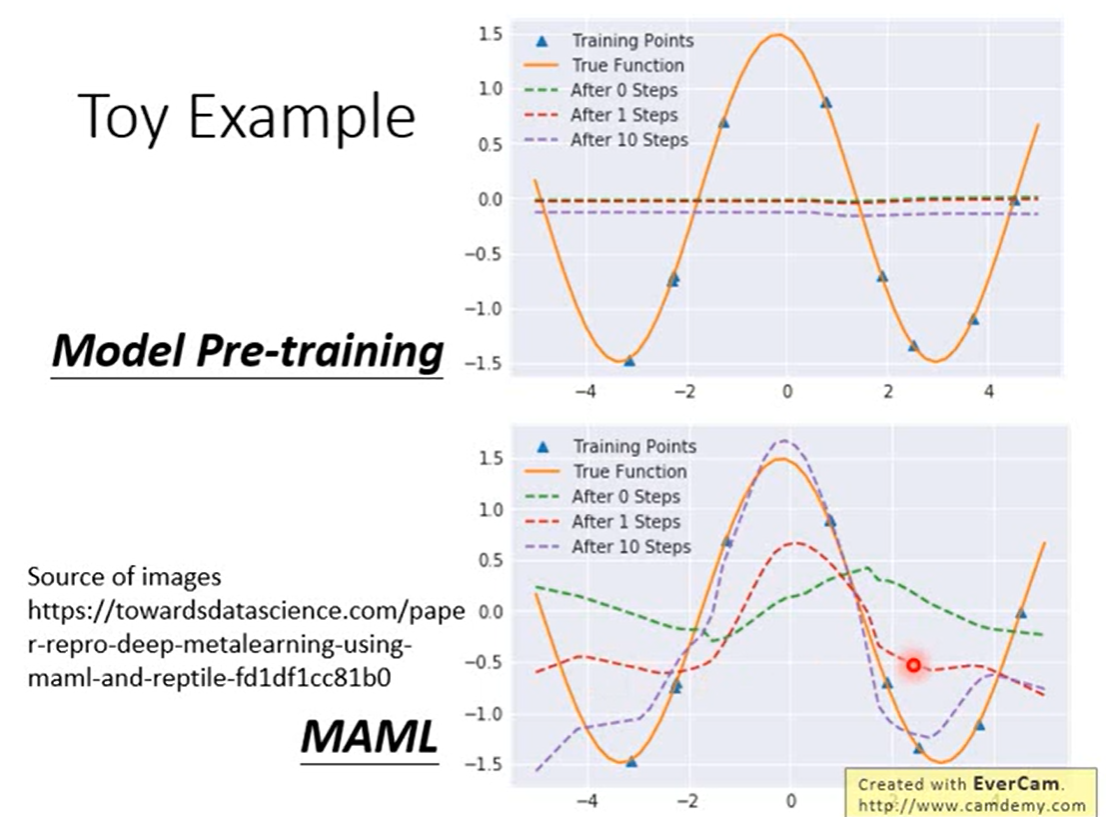
https://towardsdatascience.com/paper-repro-deep-metalearning-using-maml-and-reptile-fd1df1cc81b0
Two way one shot

理论证明

算法分析
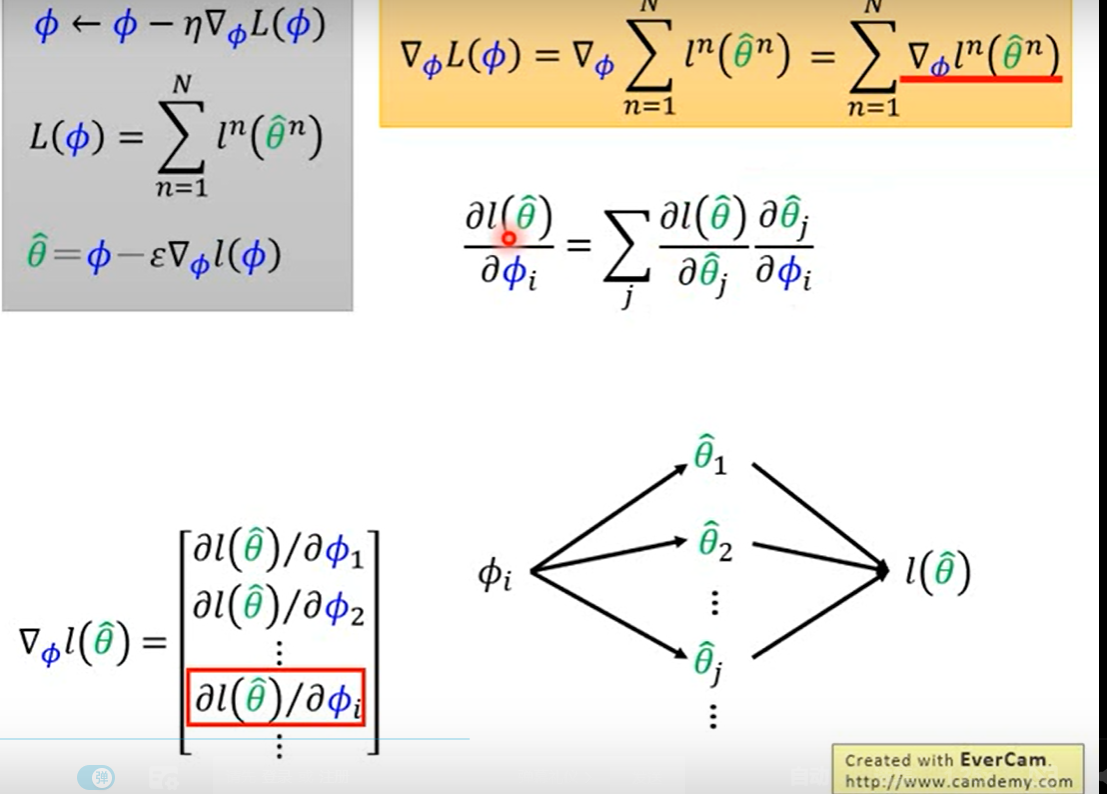
- 给定task分布,由于MAML执行两次梯度更新,所以可以设置两个学习率
- 第一步随机初始化参数
- 2,相当于epocjh
- 3,采batch task
- 4-7在采的task上计算梯度
- 8在第一次所有采样任务上再算一次梯度,然后将梯度方向作用于 θ \theta θ



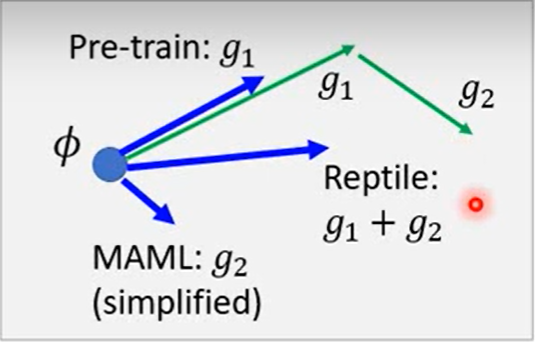
Reptile

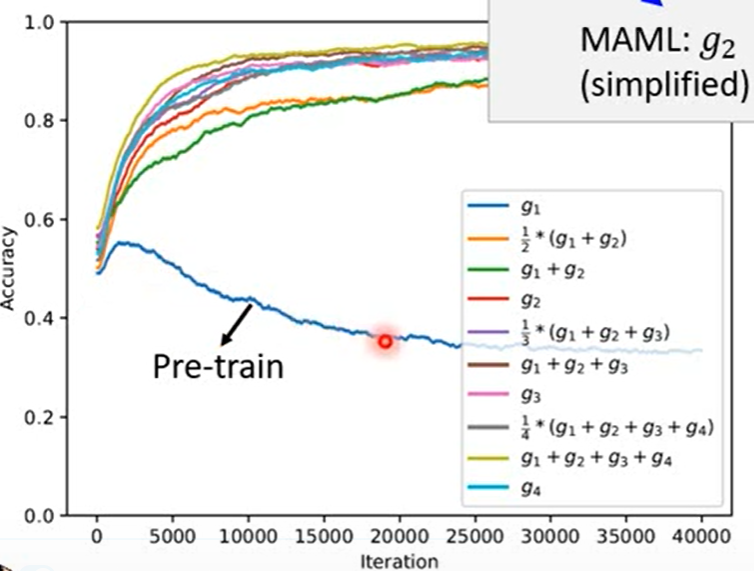
元学习应用

迁移学习其实也可以算元学习的一种,但是更多关注于两个相似模型上的关联性,其原理更多偏向于预训练,而不是元学习的典型算法MAML,迁移学习可以称为单独的一种学习方式


变形
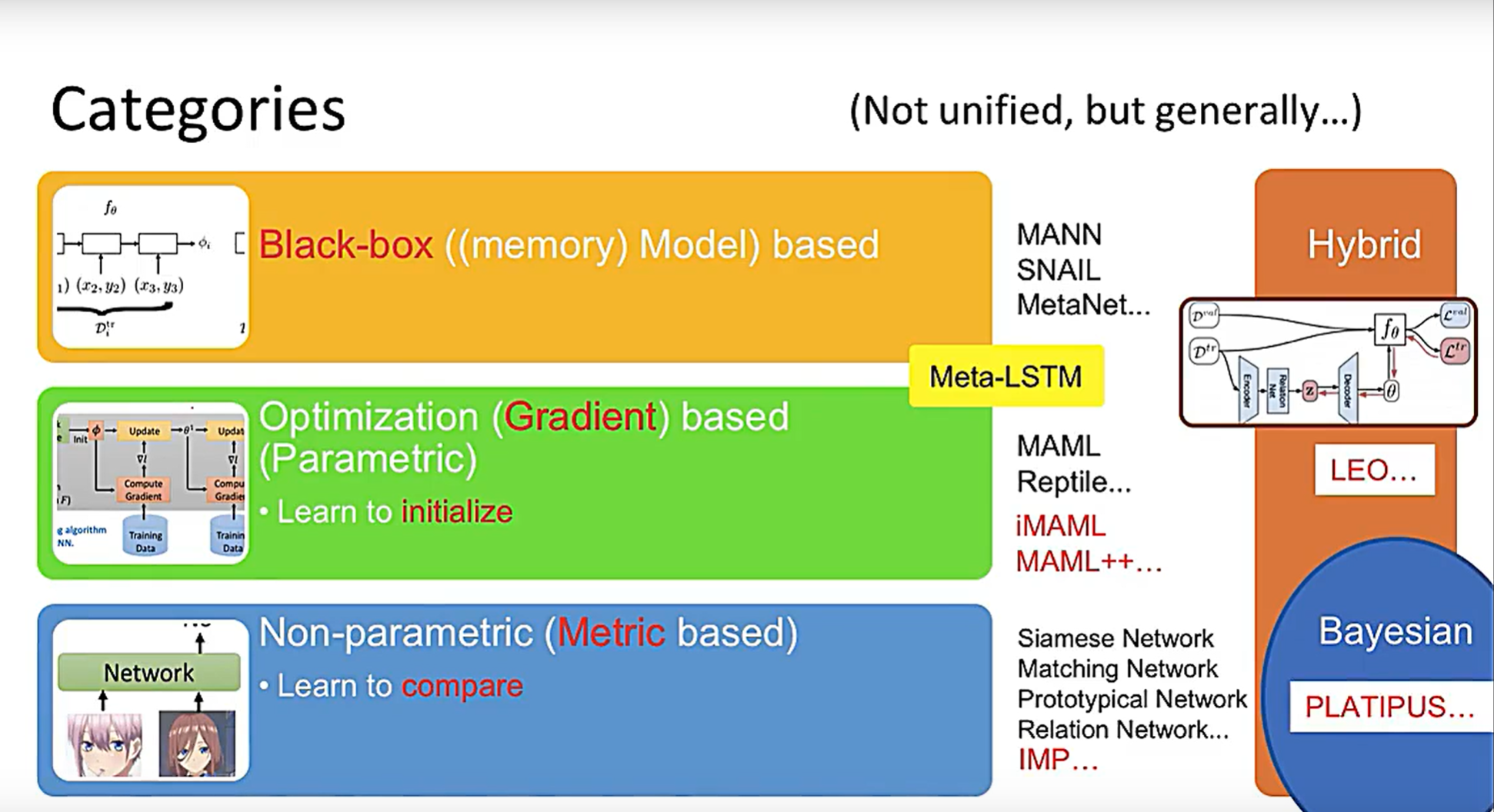

问题

解决




















 8877
8877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











