







 本文深入探讨元学习的概念、方法及其实现,包括MAML和Reptile算法的代码复现,对比不同元学习方法,解释元学习在监督学习、迁移学习中的应用。
本文深入探讨元学习的概念、方法及其实现,包括MAML和Reptile算法的代码复现,对比不同元学习方法,解释元学习在监督学习、迁移学习中的应用。
喜欢可点赞关注,并收藏,您的支持就是我的写作的动力
文章目录
1.1Motivation
What if you need to quickly learn something new?

few-shot learning:知道六个学习样本,目标是从很小的数据集中,对新的数据点进行预测
How did you accomploish this?
by leveraging prior experience!
你可能之前没有见过这个作家的画,但是你之前见过这些物体是什么,纹理是什么,通过之前的经验,找到对应的作家。
What if you want a more general-purpose AI system?
What if you don’t have a large dataset?
What if your data has a long tail?
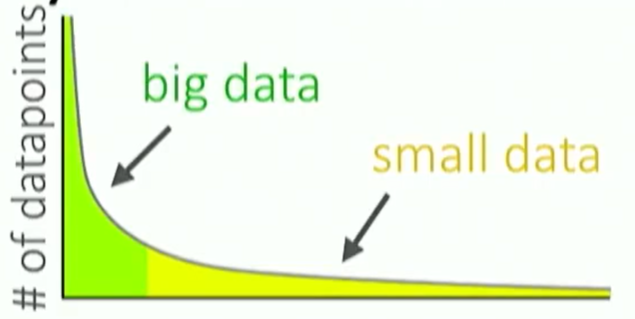
What if you need to quickly learn something new?
This is where elements of meta-learning can come into play.
这些都是mutil-task learning/meta-learning的工作环境
学习潜在任务的结构,这样就能更快学会一项新任务,如果没有任何共享结构,那你学习的速度就不会比从零开始快了
The mutil-task learning problem:learn all of the tasks more quickly or more proficirntly than learning them independtly.
努力学习所有给你的任务,更快或者更熟练的而不是独立学习任务
The meta-learning problem:Given data/experience on previous tasks, learn a new task more quickly and/or more proficiently.
给出的数据或经验的一组以前的任务下,学习一个新任务比从零开始学习更快,充分利用你之前任务中的经验。
1.2 什么是元学习
元学习是什么呢?我们知道,有监督学习是要学习一个从样本X到标签Y的映射
X
→
Y
:
y
=
f
(
x
)
X \rightarrow Y: y=f(x)
X→Y:y=f(x),我们学习到了这个函数,便可以用这个函数对所有可能的样本的标签进行预测。但是,不同的学习任务,比如桌子和椅子的分类,或者人和动物的分类,映射f是不一样的,所以当我们学习了一个任务的映射f后,若要再学习另外一个任务,那么一切只能从头开始。
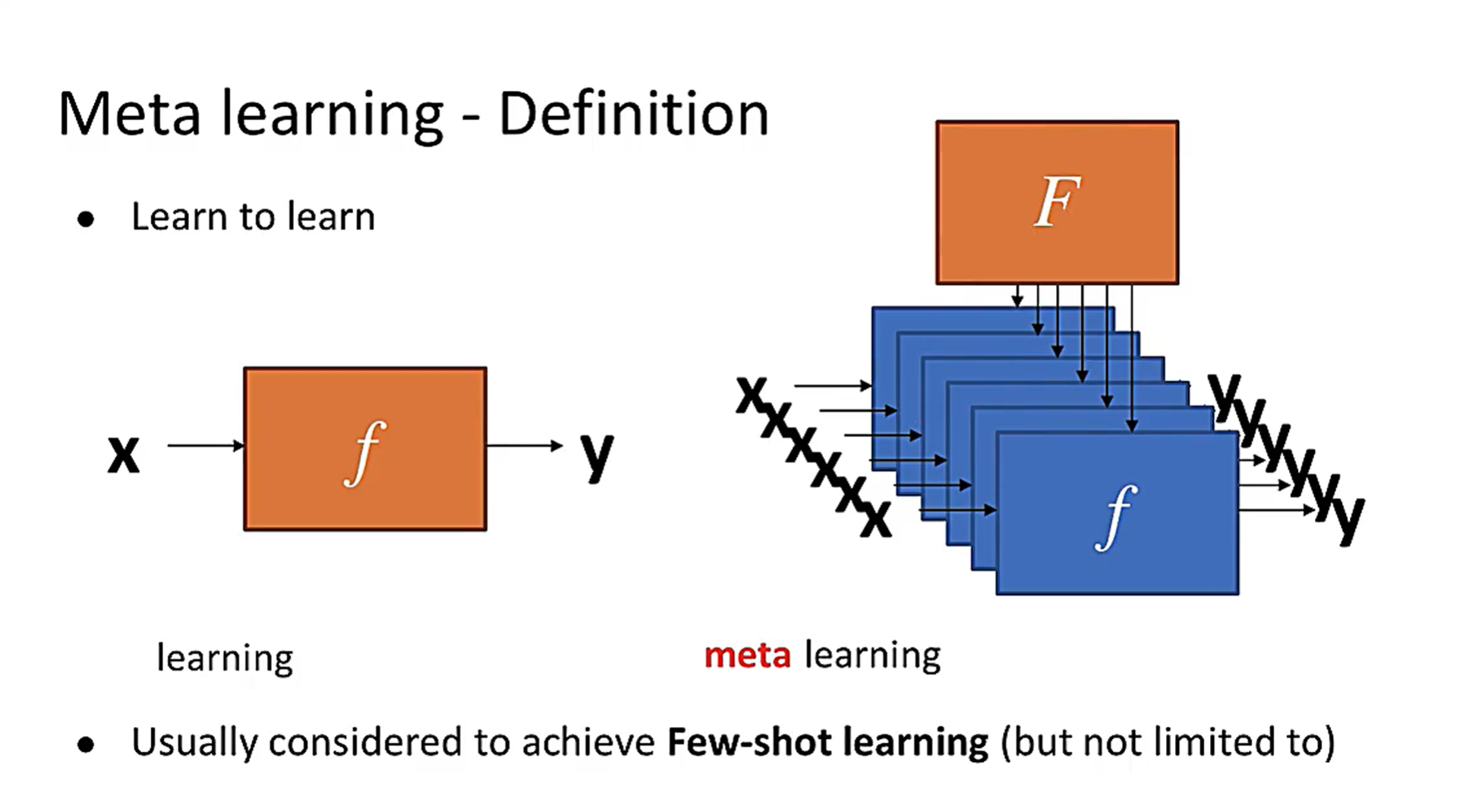
实际上,不同的相似任务之间是有联系的。人类能够做到只观看一个物体的一张或几张图片,便在之后的照片中准确地识别。这就是利用了不同任务间的联系,让我们积累了对学习这类任务的经验,并用这份经验快速地对新任务进行学习,这便是learn-to-learn(学习如何学习)。我们希望计算机也像人类一样,捕捉不同任务之间的相似之处,从而快速对新任务进行适应,而这就是元学习。举一个现实生活的例子。我们教小朋友读英语时,可以直接让他们模仿apple、banana的发音。但是他们很快又会遇到新的单词,例如strawberry,这是小朋友就需要重新听你的发音,才能正确地读出这个新单词。我们换一种方式,这一次我们不教每个单词的发音,而是教音标的发音,让小朋友们学到不同任务直接的关系,学到了音标。从此小朋友再遇见新单词,他们只要根据音标,就可以正确地读出这个单词。学习音标的过程,正是一个元学习的过程。
元学习就是要学习如何学习,从数学上来看就是,有了数据集 D = { X i , Y i } n ∈ N D=\left\{X_{i}, Y_{i}\right\}_{n \in N} D={Xi,Yi}n∈N,从数据集 D D D到函数 f f f有这样一个映射 F ( D ) = f F(D)=f F(D)=f,这个函数 F F F是从数据集到函数的映射,这个映射函数 F F F,与我们一般学习的函数不同。
我们来看看这个其中涉及的基本定义:
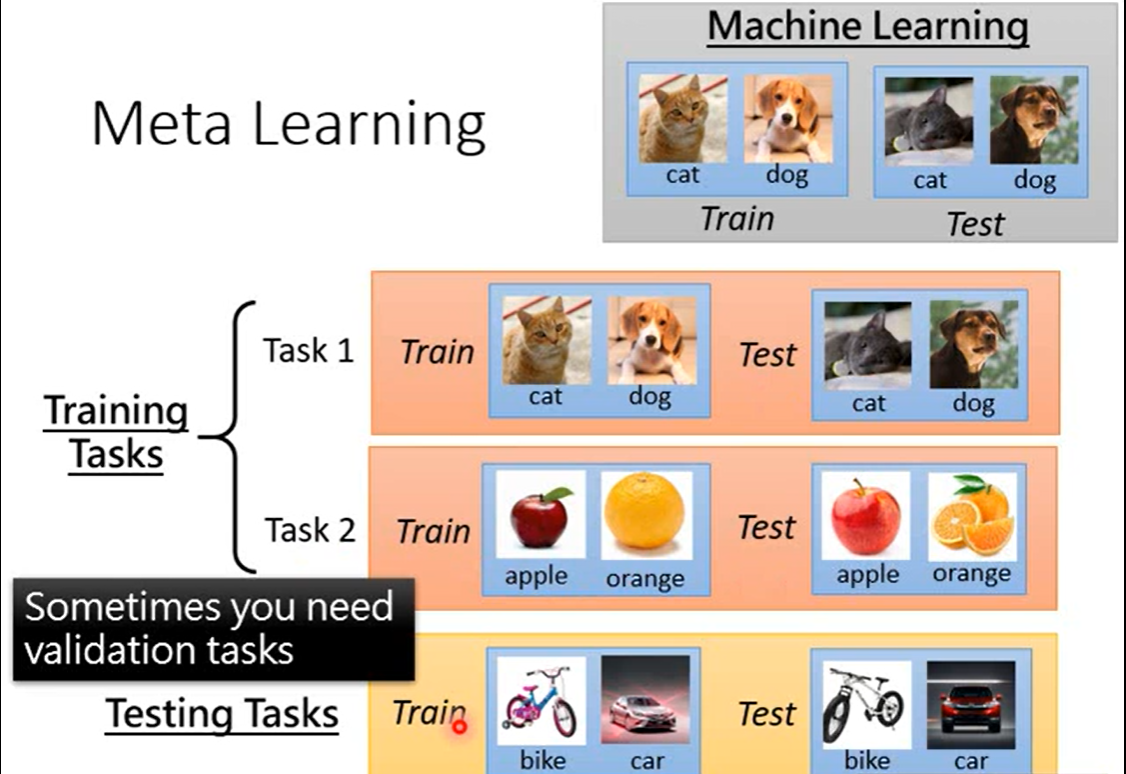
我们的学习目标是让函数
F
F
F对各种任务的数据集作用都能得到对应任务的泛化能力很强的模型
f
f
f,需要将每个数据集分成两类Train,和Test,训练时
F
F
F作用于task中的Train,然后
F
F
F对Test中样本进行测试,得到预测值与真实值之间的
l
o
s
s
loss
loss,然后梯度回传更新
F
F
F,这个
F
F
F能够产生的是具有更强泛化能力的 f,这是一般的监督学习无法完成的,因为传统监督学习只能用训练集进行训练,泛化能力无法保证。
为了区分,训练集中support set以及query set
1.3 方法
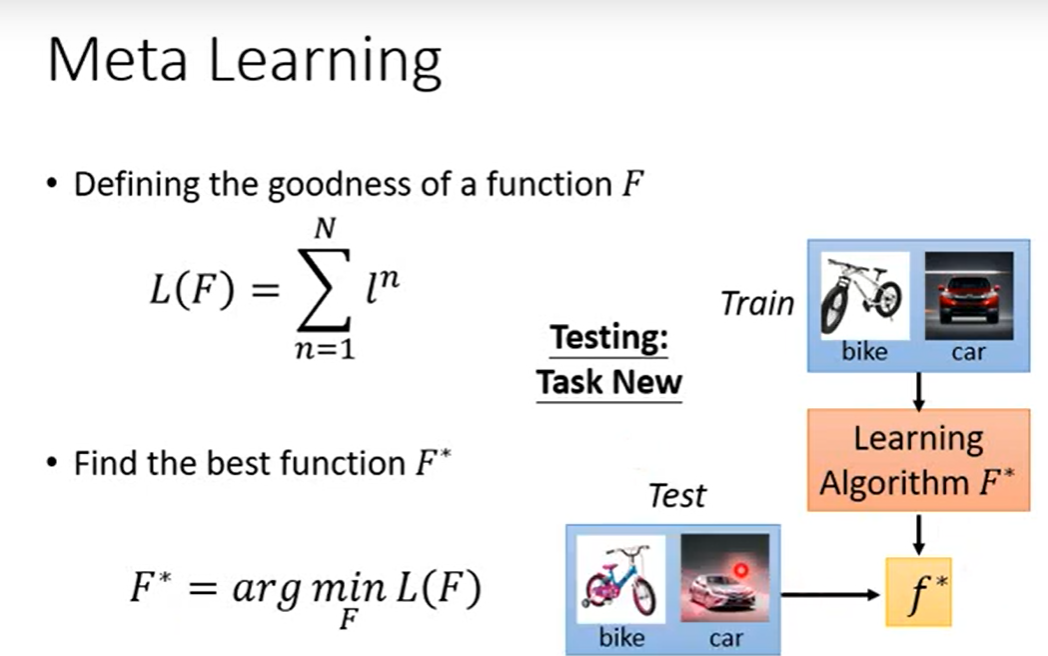
从概率论角度来看
learn meta-papameters
θ
\theta
θ:
p
(
θ
∣
D
meta-train
)
p\left(\theta \mid \mathcal{D}_{\text {meta-train }}\right)
p(θ∣Dmeta-train )
D
meta-train
=
{
(
D
1
tr
,
D
1
ts
)
,
…
,
(
D
n
tr
,
D
n
ts
)
}
\mathcal{D}_{\text {meta-train }}=\left\{\left(\mathcal{D}_{1}^{\text {tr }}, \mathcal{D}_{1}^{\text {ts }}\right), \ldots,\left(\mathcal{D}_{n}^{\text {tr }}, \mathcal{D}_{n}^{\text {ts }}\right)\right\}
Dmeta-train ={(D1tr ,D1ts ),…,(Dntr ,Dnts )}
D
i
tr
=
{
(
x
1
i
,
y
1
i
)
,
…
,
(
x
k
i
,
y
k
i
)
}
\mathcal{D}_{i}^{\text {tr }}=\left\{\left(x_{1}^{i}, y_{1}^{i}\right), \ldots,\left(x_{k}^{i}, y_{k}^{i}\right)\right\}
Ditr ={(x1i,y1i),…,(xki,yki)}
D
i
ts
=
{
(
x
1
i
,
y
1
i
)
,
…
,
(
x
l
i
,
y
l
i
)
}
\mathcal{D}_{i}^{\text {ts }}=\left\{\left(x_{1}^{i}, y_{1}^{i}\right), \ldots,\left(x_{l}^{i}, y_{l}^{i}\right)\right\}
Dits ={(x1i,y1i),…,(xli,yli)}
process:
- meta-learning: θ ⋆ = arg max θ log p ( θ ∣ D meta-train ) \theta^{\star}=\arg \max _{\theta} \log p\left(\theta \mid \mathcal{D}_{\text {meta-train }}\right) θ⋆=argmaxθlogp(θ∣Dmeta-train )
- adaptation: ϕ ⋆ = arg max ϕ log p ( ϕ ∣ D tr , θ ⋆ ) \phi^{\star}=\arg \max _{\phi} \log p\left(\phi \mid \mathcal{D}^{\operatorname{tr}}, \theta^{\star}\right) ϕ⋆=argmaxϕlogp(ϕ∣Dtr,θ⋆)
- 前两步可以简化为 ϕ ⋆ = f θ ⋆ ( D t r ) \phi^{\star}=f_{\theta^{\star}}\left(\mathcal{D}^{\mathrm{tr}}\right) ϕ⋆=fθ⋆(Dtr)
meta-learning:
θ
⋆
=
max
θ
∑
i
=
1
n
log
p
(
ϕ
i
∣
D
i
t
s
)
where
ϕ
i
=
f
θ
(
D
i
t
r
)
\begin{aligned} \theta^{\star}=& \max _{\theta} \sum_{i=1}^{n} \log p\left(\phi_{i} \mid \mathcal{D}_{i}^{\mathrm{ts}}\right) \\ & \text { where } \phi_{i}=f_{\theta}\left(\mathcal{D}_{i}^{\mathrm{tr}}\right) \end{aligned}
θ⋆=θmaxi=1∑nlogp(ϕi∣Dits) where ϕi=fθ(Ditr)
1.4 对比
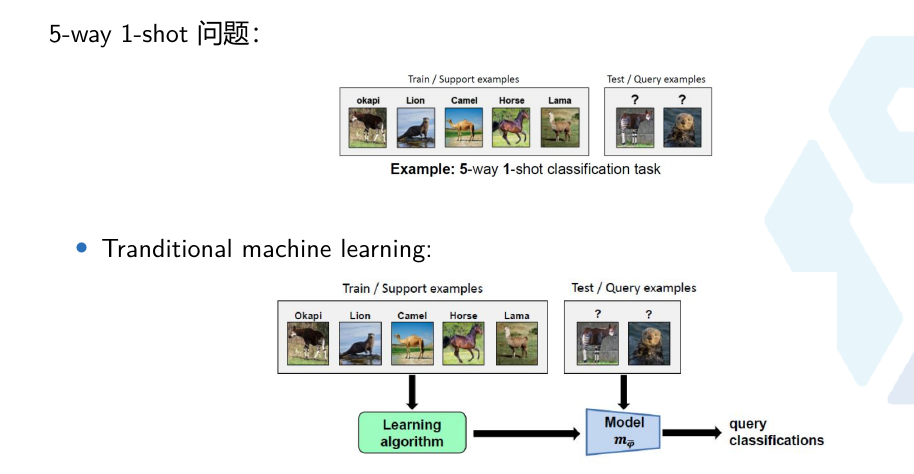


How to evaluate a meta-learning algorithm
- the Omniglot dataset lake et al.Science 2015
1623 characters from 50 different alphabets
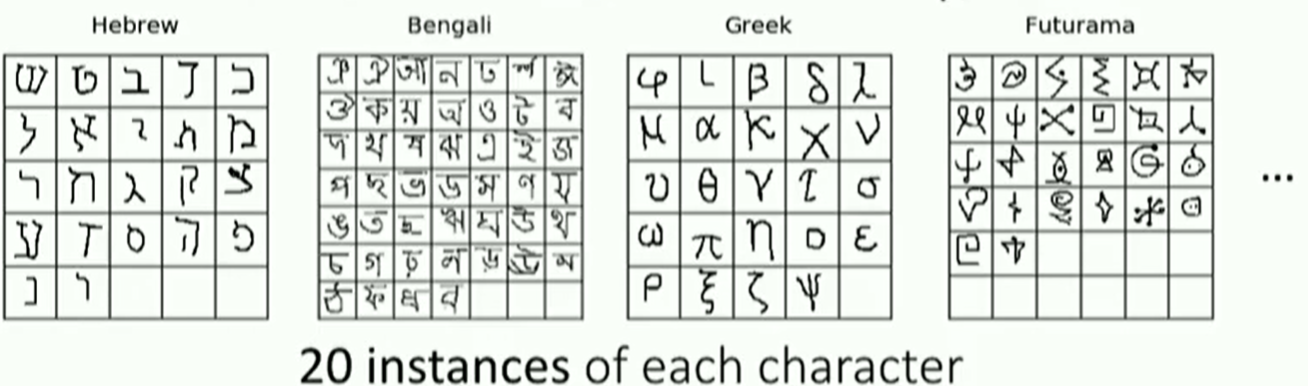
特点:每个类,只有很少的数据
结果:像一般的深度网络会在这种问题上struggle
Black-Box Adaptation
key idea :Train a neural net work to represent
p
(
ϕ
i
∣
D
i
tr
,
θ
)
p\left(\phi_{i} \mid \mathcal{D}_{i}^{\operatorname{tr}}, \theta\right)
p(ϕi∣Ditr,θ)
For now: Use dterministic(point estimate)
ϕ
i
=
f
θ
(
D
i
t
r
)
\phi_{i}=f_{\theta}\left(\mathcal{D}_{i}^{\mathrm{tr}}\right)
ϕi=fθ(Ditr)
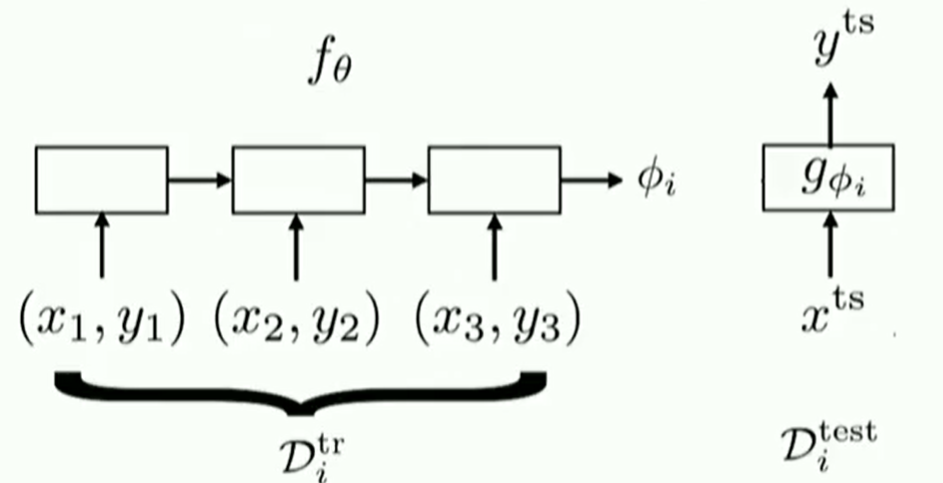
Then train with standard supervised learning
max
θ
∑
T
i
∑
(
x
,
y
)
∼
D
i
test
log
g
ϕ
i
(
y
∣
x
)
\max _{\theta} \sum_{\mathcal{T}_{i}} \sum_{(x, y) \sim \mathcal{D}_{i}^{\text {test }}} \log g_{\phi_{i}}(y \mid x)
maxθ∑Ti∑(x,y)∼Ditest loggϕi(y∣x)
L
(
ϕ
i
,
D
i
test
)
\mathcal{L}\left(\phi_{i}, \mathcal{D}_{i}^{\text {test }}\right)
L(ϕi,Ditest )




元学习领域的论文经常使用 k 和 N,k 代表了快速学习器学习的机会,N 代表了快速学习器被要求分类的数量。在我们的例子中,N = 2,k = 3,说明这是一个「两步三次」(two-way three-shot)的元学习设置。
在这里引出了Meta-learning的两个主要方法:度量学习(Matrix-based Meta-learning)和MAML(Optimization-based Meta-learning)
首先介绍下度量学习(Metric Learning):度量学习是一种空间映射的方法,其能够学习到一种特征(Embedding)空间,在此空间中,所有的数据都被转换成一个特征向量,并且相似样本的特征向量之间距离小,不相似样本的特征向量之间距离大,从而对数据进行区分。
以经典的原型网络Prototypical Networks为例,如图[7]:将Support set投影到一个度量空间,且在这个空间中同类样本距离较近,异类样本的距离较远。为了对Query set中的X进行预测,则将样本X投影至这个空间并计算X距哪个类别较近,则认为X属于哪个类别。
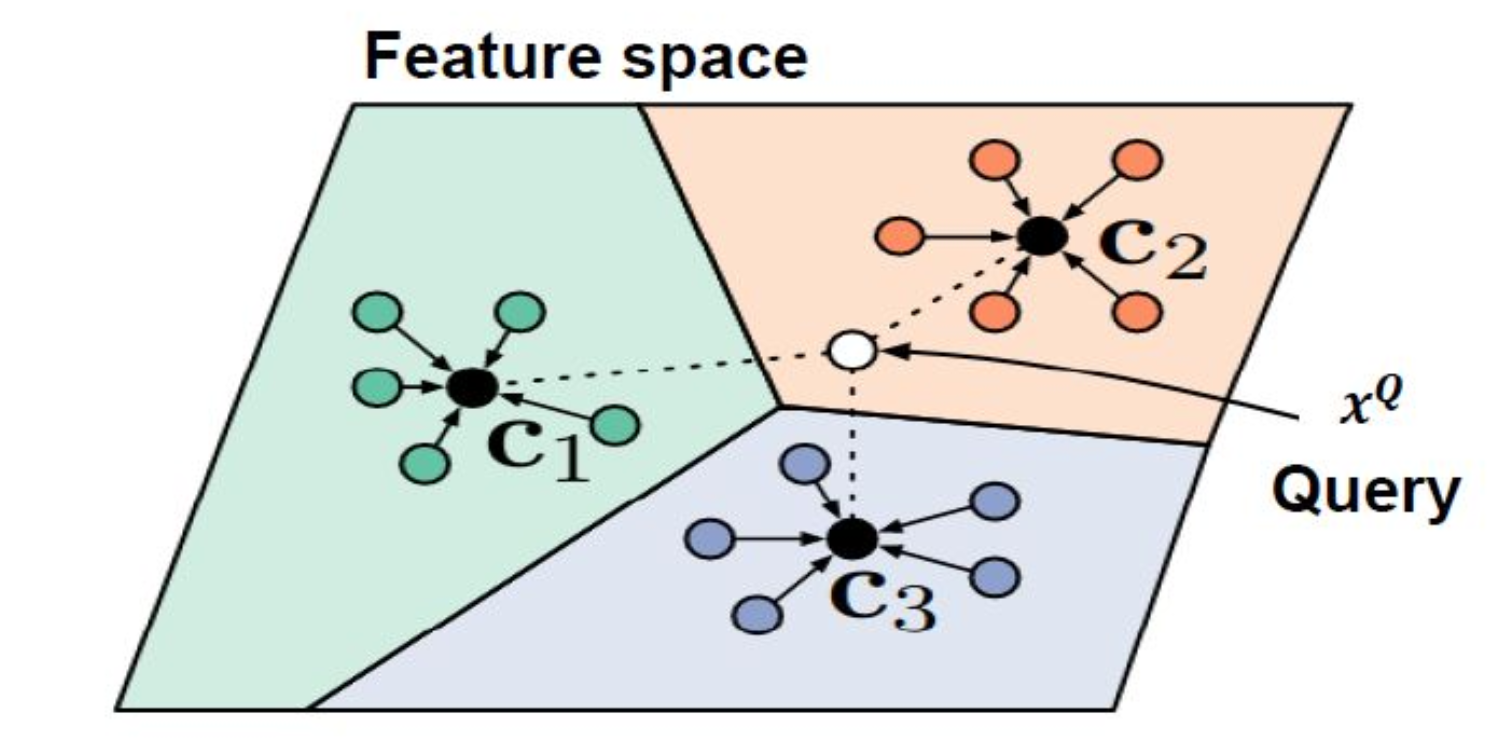
采用度量学习好处是,在生成这个元学习模型阶段,不需要参数优化,这种方法思想来源机器学习算法(KNN,K-means等算法),距离通常使用欧式距离和cos距离等等。这里不做重点介绍。
MAML的优点
- 与标准的fine-tuning 方法一致。通过在大量任务上的训练得到模型初始化参数,使得在新任务上利用少量样本实现收敛
- Model-agnostic: 适用于各种网络backbone,可用于Few-shot learning。
MAML的缺点: - 相比度量学习的投影方式,MAML需要学习的参数量更多,需要更多的算力;
- 另外由于这个原因也导致没有办法训练大型网络;与其说MAML是为了解决小样本问题而生的,不如说MAML更适用于小样本学习问题
2 元学习相关算法
2.1 MAML
Chelsea Finn,现任Google Brain研究科学家,同时也是伯克利人工智能研究实验室(BAIR)的博士后。其博士毕业于伯克利计算机系,拥有强大的学术背景,可以算是AI圈最牛逼的博士之一了。她的博士论文——基于梯度的元学习(Learning to Learn with Gradients)很值得一读,该论文系统性地阐述了Meta Learning以及她提出的MAML的方法和相关改进。Chelsea Finn从Meta Learning问题出发,然后提出了MAML理论,再进行一系列基于该理论的应用尝试。感兴趣的同学可以仔细品味这一系统性的博士论文和其代表性工作。
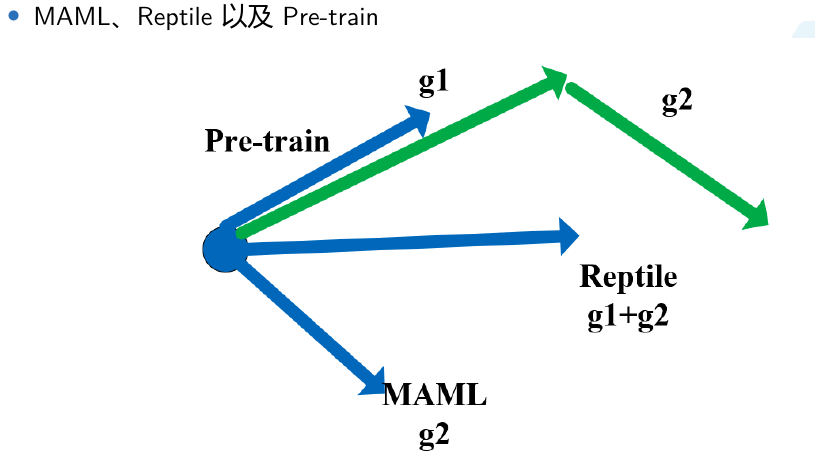
同时启动多个任务,然后获取不同任务学习的合成梯度方向来更新,从而学习一个共同的最佳base。

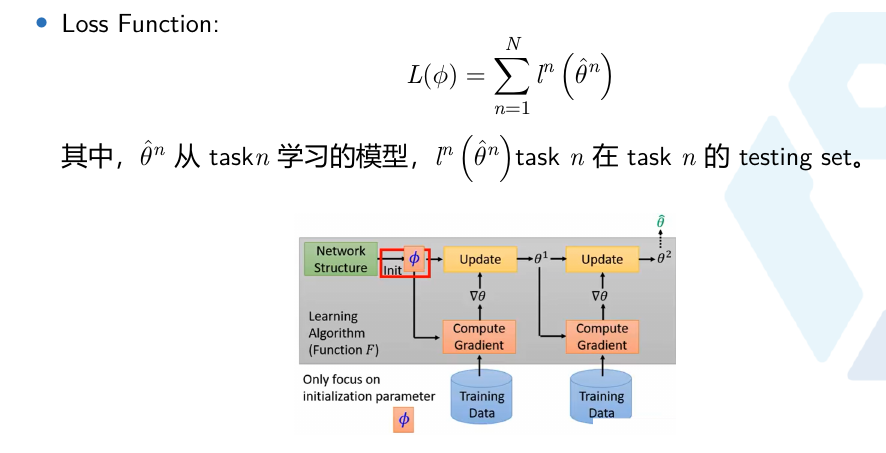

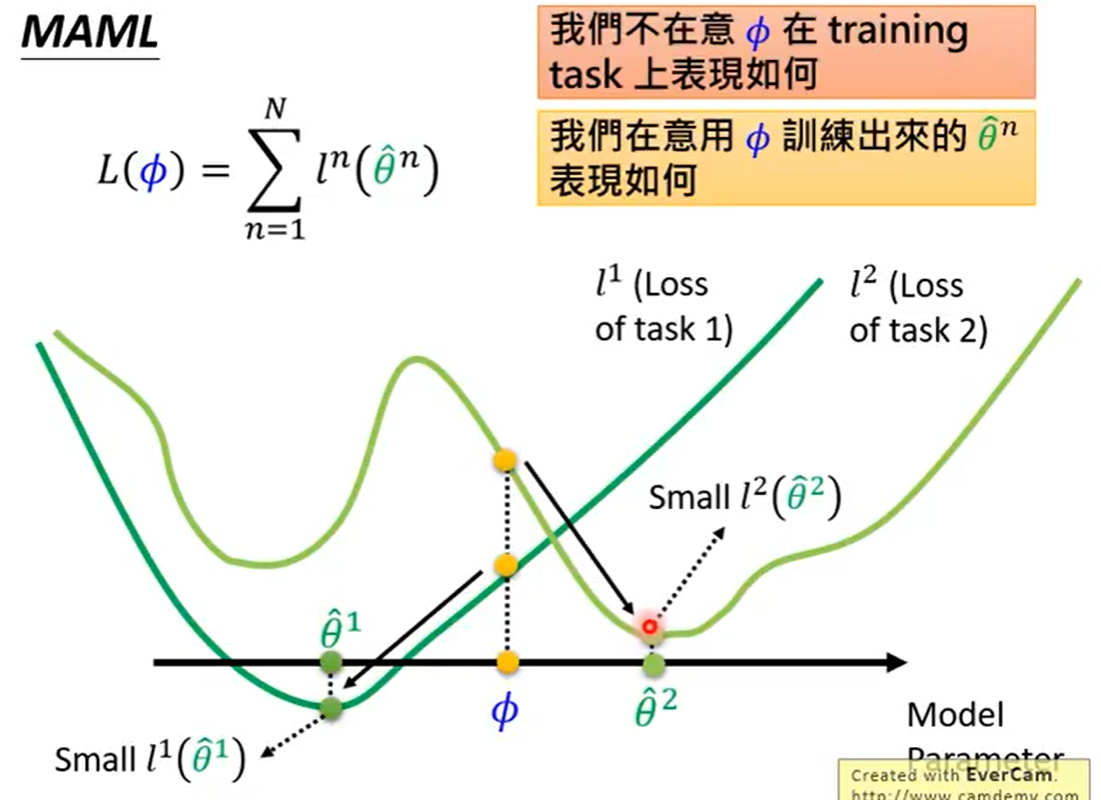
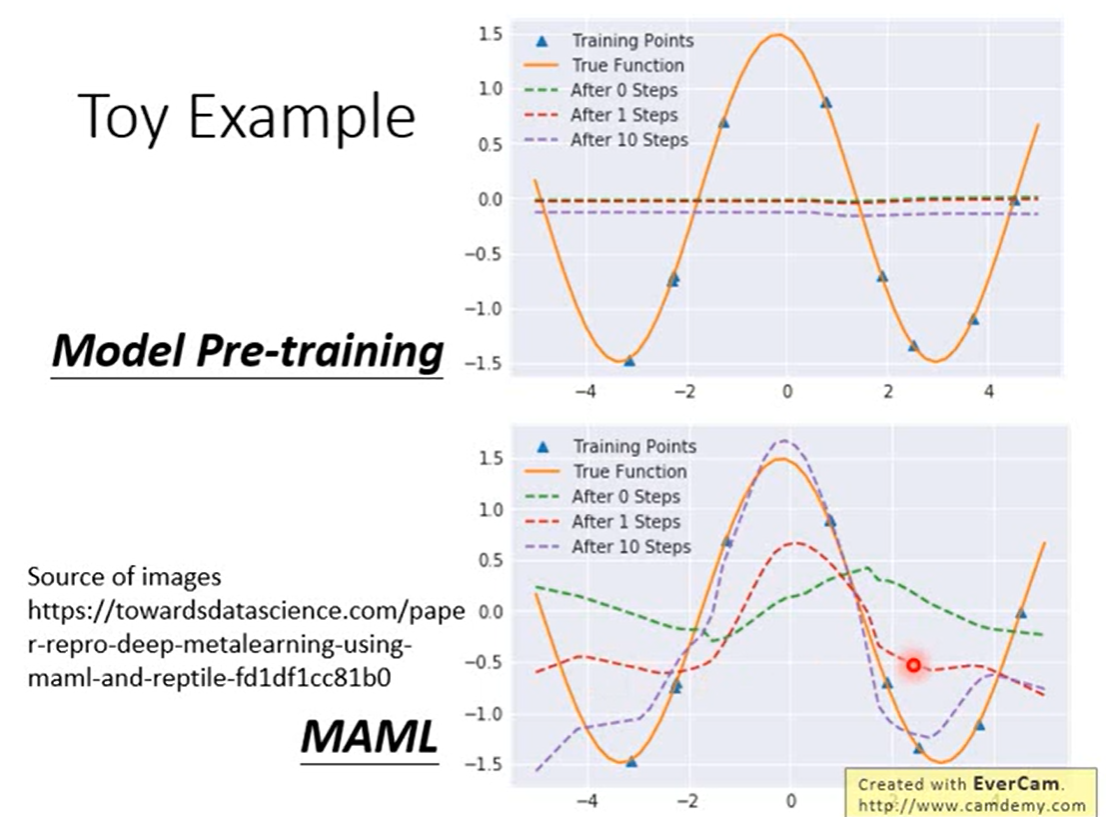
在图中Model Pre-training在所有task上都最好
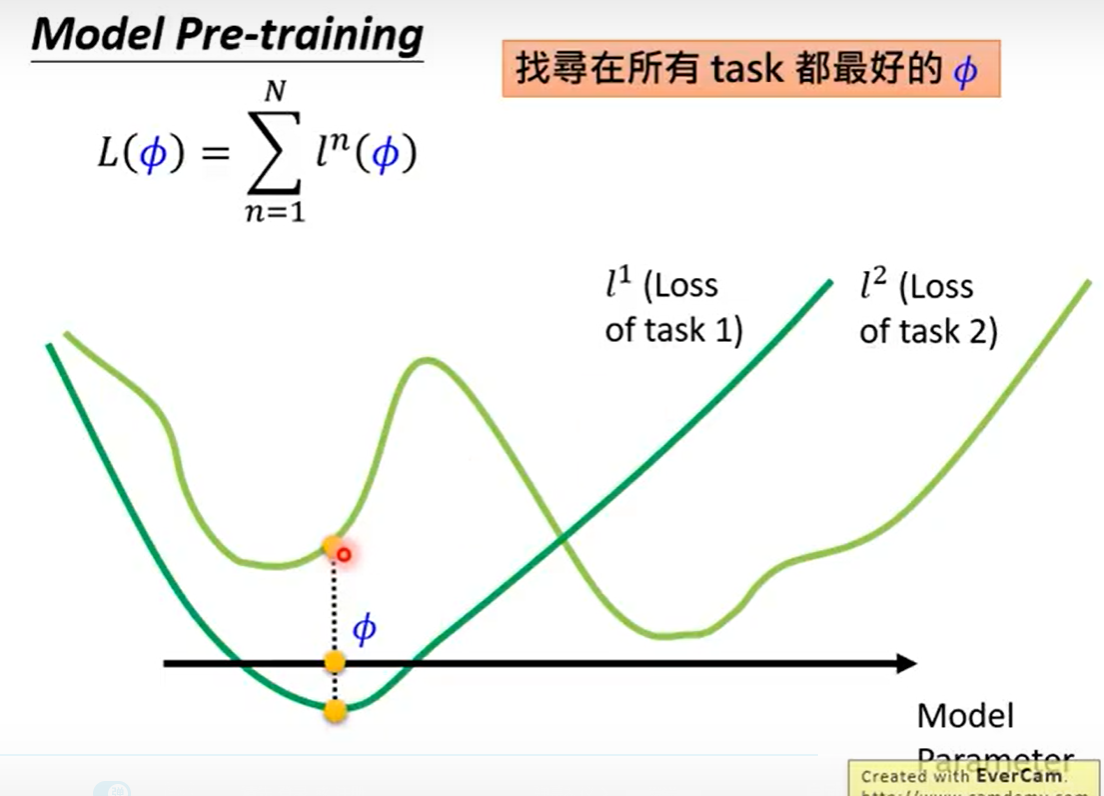
两者就像刚毕业学生一样,Model Pre-training就是直接毕业工作拿工资,对于当前是很好,MAML相当于去读博,有了高学历对于以后发展会很好。
2.2 Reptile
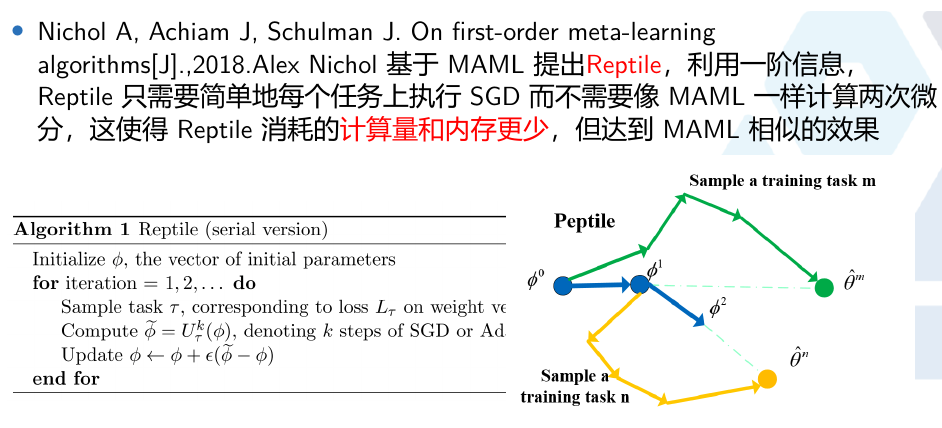
2.3 梯度对比
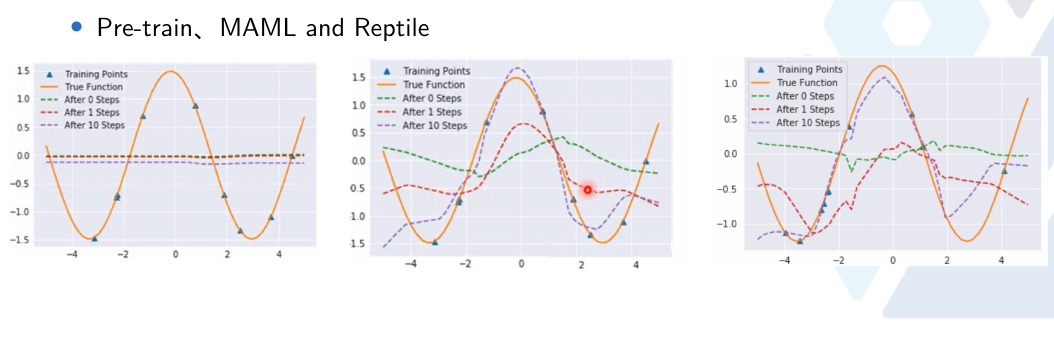
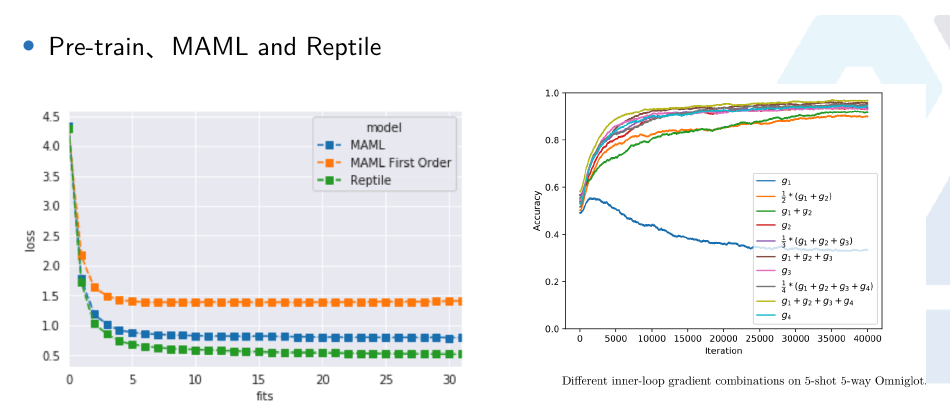
2.4 实验对比

可以看到
- Model Pre-training,学习到的网络初始参数预测出来的是绿色曲线,找到不同的sin函数上都好的,而不同sin函数叠加起来波峰与波谷抵消,为了使每个任务上都好最后得到一条近乎水平的线,所以用transfering learning在新任务上用这几个点迭代几次依然不好
- 而MAML学习到了初始参数预测有一些波动,在经过几个训练点上几次迭代很快就能拟合到橙色曲线。
由于跨多个任务的每个x都有多个可能的值,如果我们训练一个神经网络同时处理多个任务,它的最佳选择将是为每个x返回跨所有任务的平均y值。
3 MAML代码复现
3.1 问题阐述
考虑画几个例子正弦波的任务:
class SineWaveTask:
def __init__(self):
self.a = np.random.uniform(0.1, 5.0)
self.b = np.random.uniform(0, 2*np.pi)
self.train_x = None
def f(self, x):
return self.a * np.sin(x + self.b)
def training_set(self, size=10, force_new=False):
if self.train_x is None and not force_new:
self.train_x = np.random.uniform(-5, 5, size)
x = self.train_x
elif not force_new:
x = self.train_x
else:
x = np.random.uniform(-5, 5, size)
y = self.f(x)
return torch.Tensor(x), torch.Tensor(y)
def test_set(self, size=50):
x = np.linspace(-5, 5, size)
y = self.f(x)
return torch.Tensor(x), torch.Tensor(y)
def plot(self, *args, **kwargs):
x, y = self.test_set(size=100)
return plt.plot(x.numpy(), y.numpy(), *args, **kwargs)
SineWaveTask().plot()
SineWaveTask().plot()
SineWaveTask().plot()
plt.show()
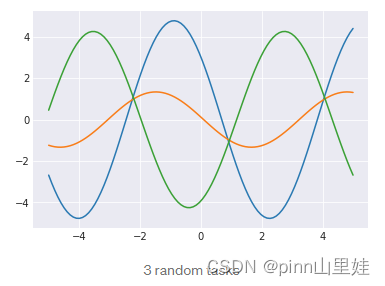
为了理解为什么这将成为迁移学习的一个问题,再画出其中的1000个:
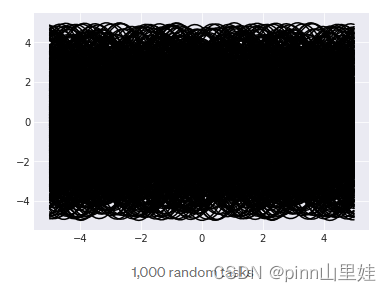
看起来在每个x值处都有很多重叠。此外,由于在多个任务中每个
x
x
x都有多个可能的值,如果训练单个神经网络同时处理多个任务,那么最好的方法就是返回所有任务中每个
x
x
x的平均
y
y
y值。那么每个
x
x
x的平均
y
y
y值是多少?将会得到如下结果。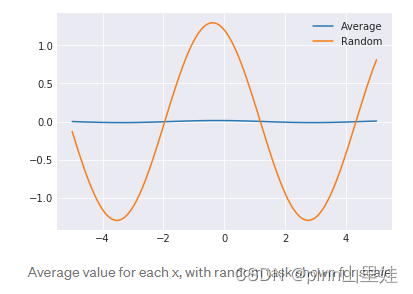
平均值基本上是0,这意味着在许多任务中训练的神经网络会简单地在所有地方返回0 。目前还不清楚这是否真的有很大帮助,但在这种情况下,这就是迁移学习方法。
再看看它的表现如何,通过实际实现一个简单的模型来解决这些正弦波任务,并使用迁移学习来训练它。首先,模型本身:
class SineModel(ModifiableModule):
def __init__(self):
super().__init__()
self.hidden1 = GradLinear(1, 40)
self.hidden2 = GradLinear(40, 40)
self.out = GradLinear(40, 1)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
return self.out(x)
def named_submodules(self):
return [('hidden1', self.hidden1), ('hidden2', self.hidden2), ('out', self.out)]
注意到它以一种奇怪的方式实现(“ModifiableModule”是什么?什么是“GradLinear”?)这是因为稍后将使用MAML来训练它。有关其中一些类的详细信息,请参阅本子,但目前您可以假设它们类似于nn。模块和nn.Linear。现在,让我们用一系列不同的随机任务来训练它:
SINE_TRANSFER = SineModel()
def sine_fit1(net, wave, optim=None, create_graph=False, force_new=False):
net.train()
if optim is not None:
optim.zero_grad()
x, y = wave.training_set(force_new=force_new)
loss = F.mse_loss(net(V(x[:, None])), V(y))
loss.backward(create_graph=create_graph, retain_graph=True)
if optim is not None:
optim.step()
return loss.data.cpu().numpy()[0]
def fit_transfer(epochs=1):
optim = torch.optim.Adam(SINE_TRANSFER.params())
for _ in range(epochs):
for t in random.sample(SINE_TRAIN, len(SINE_TRAIN)):
sine_fit1(SINE_TRANSFER, t, optim)
fit_transfer()
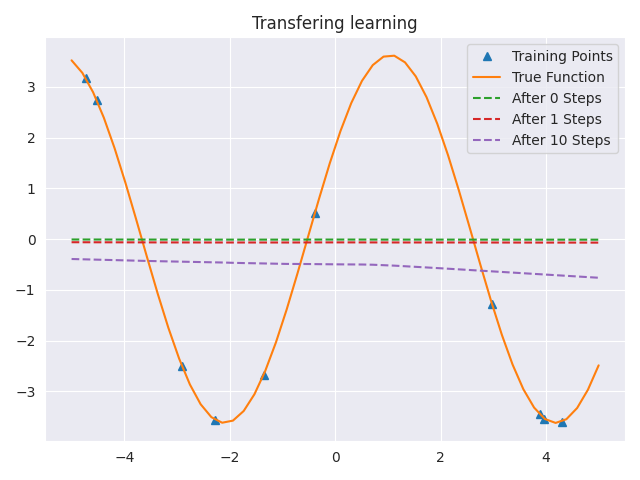
当试图将这个转移模型微调到一个特定的随机任务时,会发生以下情况:
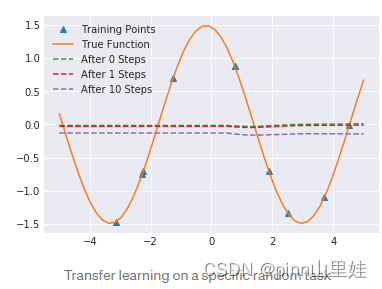
基本上,看起来传递模型学习了一个常数函数,很难对它进行微调,使其达到更好的效果。甚至不清楚我们的迁移学习是否比随机初始化更好。事实上也不是,随机初始化最终会比微调我们的转移模型得到更好的损失。
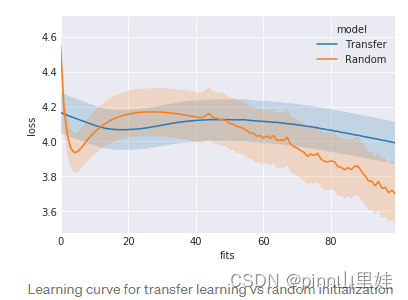
下面我们将介绍如何MAML算法对任务学习进行调整,从而实现更高效,更好的迁移效果。
MAML算法复现
如前3.1问题所述,我们试图找到一组权重,以便在类似的任务中运行梯度下降,使进展尽可能快。MAML通过运行一次梯度下降迭代,然后根据一次迭代更新初始权重,从而非常准确地实现了这一点。更具体地说:
- 创建初始化权重的copy;
- 在copy上利用随机任务执行梯度下降迭代。
- 通过梯度下降迭代将测试集上的损失反向传播,并返回到初始权值,这样就可以按更容易更新的方向更新初始权值。
因此需要取一个梯度的梯度,也就是这个过程中的二阶导数,这是PyTorch现在支持的。我们将使用二阶导数,需要确保允许我们计算原始梯度的计算图保持不变,这就是为什么我们将create_graph=True传递给.backward()的原因。
def maml_sine(model, epochs, lr_inner=0.01, batch_size=1):
optimizer = torch.optim.Adam(model.params())
for _ in range(epochs):
for i, t in enumerate(random.sample(SINE_TRAIN, len(SINE_TRAIN))):
new_model = SineModel()
new_model.copy(model, same_var=True)
loss = sine_fit1(new_model, t, create_graph=not first_order)
for name, param in new_model.named_params():
grad = param.grad
new_model.set_param(name, param - lr_inner * grad)
sine_fit1(new_model, t, force_new=True)
if (i + 1) % batch_size == 0:
optimizer.step()
optimizer.zero_grad()
那么它是如何在一个特定的随机任务中起作用的呢?利用MAML学习如下的随机函数。
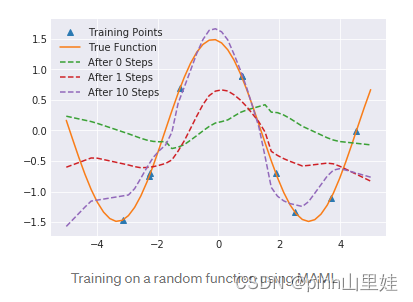
即使在一个梯度下降的步骤后,正弦形状开始可见,10步后,波的中心几乎完全正确。这是也反映在学习曲线。
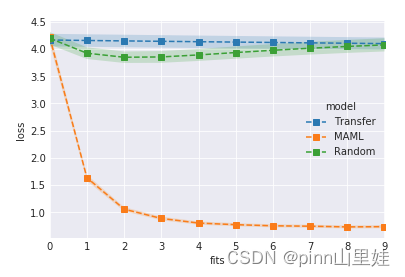
不幸的是,我们不得不使用二阶导数,这迫使代码变得复杂,也让计算变得有点慢(根据论文,大约33%,这与将在这里看到的相匹配)。
考虑MAML是否有一个不使用二阶导数的近似?当然!可以简单地假设我们用于内梯度下降的梯度是凭空出现的,因此只是改进了初始参数而不考虑这些二阶导数。让我们在MAML训练函数中添加一个first_order形参来处理这个问题:
def maml_sine(model, epochs, lr_inner=0.01, batch_size=1, first_order=False):
optimizer = torch.optim.Adam(model.params())
for _ in range(epochs):
for i, t in enumerate(random.sample(SINE_TRAIN, len(SINE_TRAIN))):
new_model = SineModel()
new_model.copy(model, same_var=True)
loss = sine_fit1(new_model, t, create_graph=not first_order)
for name, param in new_model.named_params():
grad = param.grad
if first_order:
grad = V(grad.detach().data)
new_model.set_param(name, param - lr_inner * grad)
sine_fit1(new_model, t, force_new=True)
if (i + 1) % batch_size == 0:
optimizer.step()
optimizer.zero_grad()
这个一阶近似有多好呢?事实证明,它几乎和最初的MAML一样好,而且确实快了33%。
3.2 Reptiles代码复现
MAML的一阶近似告诉我们一些有趣的事情正在发生:毕竟,梯度是如何生成的似乎应该与良好的初始化相关,但它显然不是那么多。Reptile将这个想法进一步发扬光大,它告诉我们做以下事情:在给定的任务上运行SGD进行几次迭代,然后将初始化权值向SGD迭代 k k k次后获得的权值方向移动一点。算法如此简单,只需要几行伪代码:
在这里插入图片描述

实际上,如果运行SGD进行一次迭代,将得到与上面描述的迁移学习等价的东西,但使用几次迭代后并没有,所以实际上每次更新的权重实际上间接依赖于损失的二阶导数,类似于MAML。但是为什么会这样呢?Well Reptile提供了一个令人信服的直觉:对于每个任务,都有最优的权重。事实上,可能有许多组的权重是最优的。这意味着,如果您执行多个任务,则应该有一组权值,每个任务与至少一组最优权值的距离最小。这组权值是我们想要初始化网络的地方,因为它很可能是对任何任务来说,需要最少的工作才能达到最优的那个。这是Reptile找到的一组权重。
可以在下图中直观地看到这一点:两条黑线表示两个不同任务的最佳权重集,而灰色线表示初始化权重。Reptile试图使初始化权值越来越接近于最优权值彼此最接近的点。
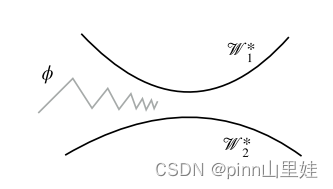
现在让实现Reptile并将其与MAML进行比较:
def reptile_sine(model, epochs, lr_inner=0.01, lr_outer=0.001, k=3, batch_size=32):
optimizer = torch.optim.Adam(model.params(), lr=lr_outer)
name_to_param = dict(model.named_params())
for _ in range(epochs):
for i, t in enumerate(random.sample(SINE_TRAIN, len(SINE_TRAIN))):
new_model = SineModel()
new_model.copy(model)
inner_optim = torch.optim.SGD(new_model.params(), lr=lr_inner)
for _ in range(k):
sine_fit1(new_model, t, inner_optim)
for name, param in new_model.named_params():
cur_grad = (name_to_param[name].data - param.data) / k / lr_inner
if name_to_param[name].grad is None:
name_to_param[name].grad = V(torch.zeros(cur_grad.size()))
name_to_param[name].grad.data.add_(cur_grad / batch_size)
if (i + 1) % batch_size == 0:
optimizer.step()
optimizer.zero_grad()
Reptile在一个随机问题上看起来效果非常好。
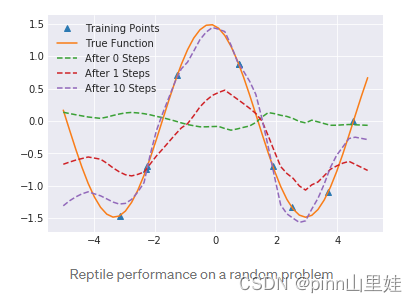
学习曲线如下:
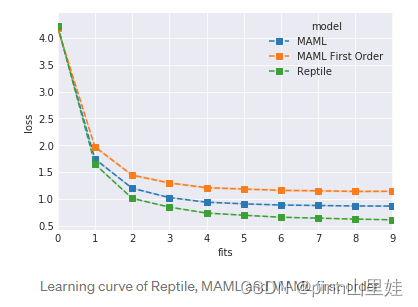
看起来Reptile确实通过更简单、更快的算法实现了与MAML类似甚至更好的性能。所有这些都适用于比正弦波这个toy例子更多的问题。要了解更多细节,建议你阅读论文。在这一点上,您应该有足够的背景知识来轻松理解它们。
未来真正有趣的是将这些方法不仅应用于K-shot学习问题,而且应用于更大的问题:转移学习在基于中等规模数据集(几百或几千个,与K-shot学习中常见的大约10个左右的数据集相比)的图像分类领域中已经非常成功。使用Reptile训练一个resnet网络会产生比我们现在的模型更适合迁移学习的东西吗?
4 元学习分类
4.1 元学习分类
当前针对实验“元学习”的方法有很多,具体可以分为以下几类:
Meta-Learning in Neural Networks: A Survey
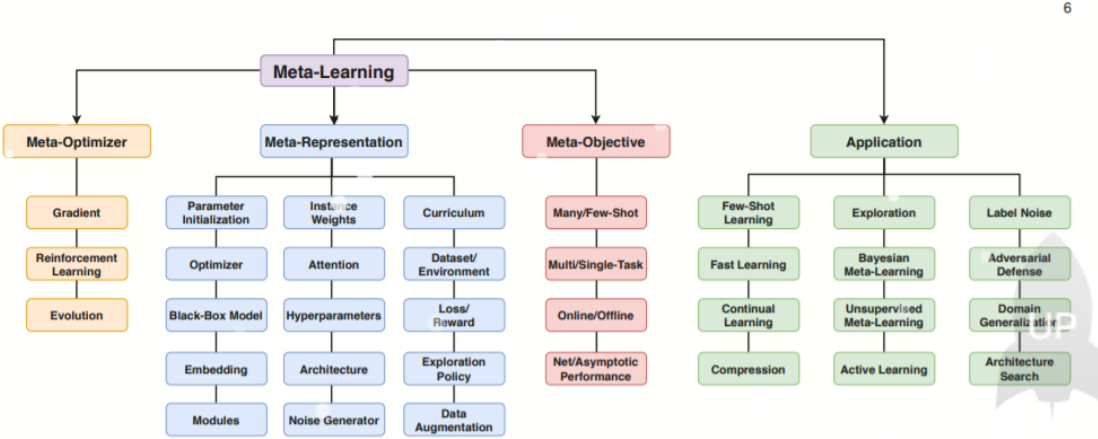
详细介绍
- 基于记忆Memory的方法。
基本思路:因为要通过以往的经验来学习,那就可以通过在神经网络中添加Memory来实验。 - 基于预测梯度的方法。
基本思路:Meta Learning的目的是实现快速学习,而实现快速学习的关键点是神经网络的梯度下降要准和快,那么就可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测的准,那么学习就会快。 - 利用Attention注意力机制
基本思路:训练一个Attention模型,在面对新任务时,能够直接的关注最重要部分。 - 借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么能否利用LSTM的结构训练处一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数 - 面向RL的Meta Learning方法
基本思路:既然Meta Learning可以用在监督学习,那么增强学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,和之前的action来实验。 - 通过训练一个base model的方法,能同时应用到监督学习和增强学习上
基本思路:之前的方法只能局限在监督学习或增强学习上,能否做出一个更通用的模型。 - 利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,那么能否照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据。 - 预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的Loss,那么学习的速度也会更快,因此,可以构建一个模型利用以往的任务来学习如何预测Loss
4.2 相关信息
1 Few-shot Learning
Few-shot Learning 是 Meta Learning 在监督学习领域的应用
早期的 Few-shot Learning 算法研究多集中在图像领域,如图 2 所示,Few-shot Learning 模型大致可分为三类:Model Based,Metric Based 和 Optimization Based。
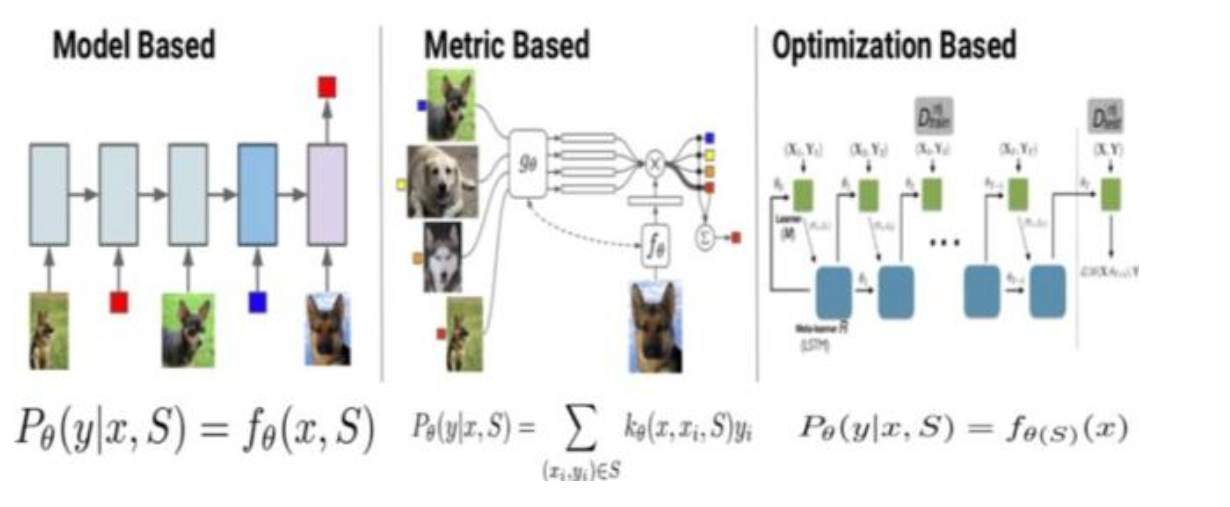
其中 Model Based 方法旨在通过模型结构的设计快速在少量样本上更新参数,直接建立输入 x 和预测值 P 的映射函数;Metric Based 方法通过度量 batch 集中的样本和 support 集中样本的距离,借助最近邻的思想完成分类;Optimization Based 方法认为普通的梯度下降方法难以在 few-shot 场景下拟合,因此通过调整优化方法来完成小样本分类的任务。
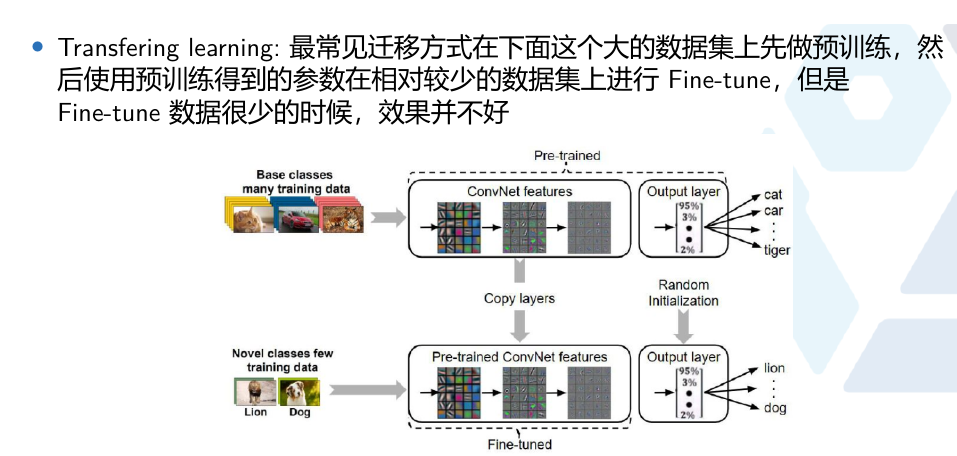
2 迁移学习
利用Base-classes中的大量数据进行网络训练,得到的Pre-trained模型迁移到Novel-classes进行Fine-tune
迁移学习基本思路是:
- pretrained模型迁移到新任务上进行fine-tun,但是微调数据很少的时候,效果并不好。
- 我们首先训练一个具有初始参数的模型,即在新任务中使用一个 eposide的数据进行训练。在训练中,初始的参数被更新。模型的目标是寻找一组初始的参数,在新任务的评价中,可以使损失在使用新参数的时候很小。
这一思路是由迁移学习启发而来,但是迁移学习需要一定数量的数据集,所以在数据集非常小或在和预训练数据非常不同的数据集上效果不佳。元学习中的优化策略则是:优化一组初始参数,或优化一个可以快速在每个任务上表现良好的模型,尝试用系统性的方法去学习一种在各种任务中都非常优秀的初始化参数。
在传统的机器学习问题中,我们关注获取一个类别中大量的样本。在元学习中,我们的关注点转向收集许多种类的任务。间接的,这说明我们需要收集许多不同类别的数据。
参考:
Stanford cs330深度多任务和元学习
https://www.cnblogs.com/zhengzhicong/p/12964727.html
https://www.codenong.com/cs106970179/
https://www.zhihu.com/question/299020462
https://zhuanlan.zhihu.com/p/138827574
https://blog.csdn.net/wangkaidehao/article/details/103789820
https://towardsdatascience.com/paper-repro-deep-metalearning-using-maml-and-reptile-fd1df1cc81b0


















 8815
8815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











