







1 字符串
1.1 字符串的各种内置方法
Python字符串的方法及含义


1.2 格式化
格式化字符串,就是按照统一的规格去输出一个字符串。如果规格不统一,就很可能造成误会。
1.2.1 format
format()方法接收位置参数和关键字参数,二者均传递到一个名为replacement的字段。而这个replacement字段在字符串内用大括号({})表示。
举几个例子就能理解了:
- "{0} love {1}.{2}".format("I", "FishC", "com")
- "{a} love {b}.{c}".format(a="I", b="FishC", c="com")
- "{0} love {b}.{c}".format("I", b="FishC", c="com")
- "{0}:{1:.2f}".format("圆周率", 3.14159)
要注意的是,如果将位置参数和关键字参数综合在一起使用,那么位置参数必须在关键字参数之前,否则就会出错。可以看到,位置参数{1}跟平常有些不同,后边多了个冒号。在替换域中,冒号表示格式化符号的开始,“.2”的意思是四舍五入到保留两位小数点,而f的意思是浮点数,所以按照格式化符号的要求打印出了3.14。
1.2.2 格式化操作符:%
当%的左右均为数字的时候,它表示求余数的操作;但当它出现在字符中的时候,它表示的是格式化操作符。下表列举了Python的格式化符号及含义。

举几个例子:
- '%c' % 97;
- '%d转换为八进制是:%o' % (123, 123);
- '%f用科学计数法表示为:%e' % (149500000, 149500000);
字符串格式化:
- str1 = "一支穿云箭,千军万马来相见;"
- str2 = "两副忠义胆,刀山火海提命现。"
- "%s%s" % (str1, str2)
三种方法可以对字符串进行拼接了。什么时候用哪种方法,根据不同情况,可以参考下面三条准则进行选择:
- 简单字符串连接时,直接使用加号(+),例如:full_name = prefix + name;
- 复杂的,尤其有格式化需求时,使用格式化操作符(%)进行格式化连接,例如:result = "result is %s:%d" % (name, score);
- 当有大量字符串拼接,尤其发生在循环体内部时,使用字符串的join()方法无疑是最棒的,例如:result = "".join(iterator);
Python还提供了格式化操作符的辅助指令,如下表所示:

举例:
>>> '%5.1f' % 27.658
' 27.7'
>>> '%.2e' % 27.658
'2.77e+01'
>>> '%10d' % 5
' 5'
>>> '%-10d' % 5
'5 '
>>> '%010d' % 5
'0000000005'
>>> '%#X' % 100
'0X64'python转义字符及含义

2 序列
列表、元组和字符串统称为序列。它们之间有很多共同点:
- 都可以通过索引得到每一个元素;
- 默认索引值总是从0开始(当然灵活的Python还支持负数索引);
- 可以通过切片的方法得到一个范围内的元素的集合;
- 有很多共同的操作符(重复操作符、拼接操作符、成员关系操作符);
关于序列的常用BIF(内建方法)总结如下:
- list([iterable]):list()方法用于把一个可迭代对象转换为列表;
- tuple([iterable]):tuple()方法用于把一个可迭代对象转换为元组,具体的用法和list()一样;
- str(obj):str()方法用于把obj对象转换为字符串;
- len(sub):用于返回sub参数的长度;
- max():max()方法用于返回序列或者参数集合中的最大值;
- min():min()方法跟max()用法一样,但效果相反:返回序列或者参数集合中的最小值;需要注意的是,使用max()方法和min()方法都要保证序列或者参数的数据类型统一,否则会出错;
- sum(iterable[, start]):sum()方法用于返回序列iterable的所有元素值的总和,用法跟max()和min()一样。但sum()方法有一个可选参数(start),如果设置该参数,表示从该值开始加起,默认值是0;
- sorted(iterable, key=None, reverse=False):sorted()方法用于返回一个排序的列表,大家还记得列表的内建方法sort()吗?它们的实现效果一致,但列表的内建方法sort()是实现列表原地排序;而sorted()是返回一个排序后的新列表;
- reversed(sequence):reversed()方法用于返回逆向迭代序列的值。同样的道理,实现效果
- 跟列表的内建方法reverse()一致。区别是:列表的内建方法是原地翻转,而reversed()是返回一个翻转后的迭代器对象。你没看错,它不是返回一个列表,而是返回一个迭代器对象。
- enumerate(iterable):enumerate()方法生成由二元组(二元组就是元素数量为2的元组)
- 构成的一个迭代对象,每个二元组由可迭代参数的索引号及其对应的元素组成;
- zip(iter1 [,iter2 [...]]):zip()方法用于返回由各个可迭代参数共同组成的元组;
3 函数
- 形参与实参:形参指的是函数定义的过程中小括号里的参数,而实参则指的是函数在被调用的过程中传递进来的参数;
- 函数文档:作用是描述该函数的功能以及一些注意事项,举例如:

- 位置参数:在定义函数的时候,就已经把参数的名字和位置确定下来,Python中这类位置固定的参数称为位置参数。对于函数的调用者来说,只需要知道按照顺序传递正确的参数就可以了;
举例说明:

在调用函数的时候,位置参数必须在关键字参数的前面,否则就会出错。
- 默认参数:Python的函数允许为参数指定默认的值,那么在函数调用的时候如果没有传递实参,则采用默认参数值;

- 收集参数:大多数时候它也被称为可变参数。有时候,可能函数也不知道调用者实际上会传入多少个实参 。若实参个数不确定,在定义函数的时候,形参就可以使用收集参数来“搞定”。而语法也很简单,仅需要在参数前面加上星号(*)即可:

建议如果定义的函数中带有收集参数,那么可以将其他参数设置为默认参数,例如,print()的原型如下:
![]()
- 闭包:Python中的闭包从表现形式上定义为:如果在一个内部函数里,对在外部作用域但不是在全局作用域的变量进行引用(简言之:就是在嵌套函数的环境下,内部函数引用了外部函数的局部变量),那么内部函数就被认为是闭包。
举例:

4 函数式编程
4.1 lambda
Python使用lambda关键字来创建匿名函数。基本语法是使用冒号(:)分隔函数的参数及返回值:冒号的左边放置函数的参数,如果有多个参数,使用逗号(,)分隔即可;冒号右边是函数的返回值。
执行完lambda语句后实际上返回一个函数对象,如果要对它进行调用,只需要给它绑定一个临时的名字即可。举例如下:
普通函数:

转换为lambda表达式:
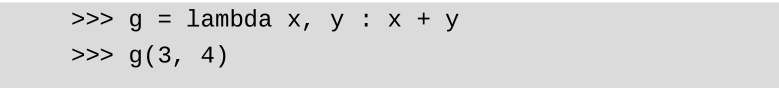
4.2 filter()
filter()函数是一个过滤器,它的作用就是在海量的数据里面提取出有用的信息。

filter()这个内置函数有两个参数:第一个参数可以是一个函数也可以是None,如果是一个函数的话,则将第二个可迭代对象里的每一个元素作为函数的参数进行计算,把返回True的值筛选出来;如果第一个参数为None,则直接将第二个参数中为True的值筛选出来。
4.3 map()
映射。map()这个内置函数也有两个参数,仍然是一个函数和一个可迭代对象,将可迭代对象的每一个元素作为函数的参数进行运算加工,直到可迭代序列每个元素都加工完毕。
map()的第二个参数是收集参数,支持多个可迭代对象。map()会从所有可迭代对象中依次取一个元素组成一个元组,然后将元组传递给func。注意:如果可迭代对象的长度不一致,则以较短的迭代结束为止。举例:
![]()
5 字典与集合
5.1 字典的几种创建方式
创建一个字典:dict1={键:值,键:值,键:值......}。其中键不能重复,且也不能为变量。举例下面这几种方法都是创建同样的字典:

有别于序列,字典是不支持拼接和重复操作的。
各种内置方法如下:
- fromkeys(seq[, value]):fromkeys()方法用于创建并返回一个新的字典,它有两个参数;第一个参数是字典的键;第二个参数是可选的,是传入键对应的值,如果不提供,那么默认是None;
- keys(),values()和items():keys()用于返回字典中的键,values()用于返回字典中所有的值,那么,items()当然就是返回字典中所有的键值对(也就是项);
- get(key[, default]):get()方法提供了更宽松的方式去访问字典项,当键不存在的时候,get()方法并不会报错,只是默默地返回了一个None,表示啥都没找到。如果希望找不到数据时返回指定值,那么可以在第二个参数设置对应的默认返回值;
![]()
- 确认一个键是否在字典中:

- 清空一个字典:dict1.clear()
- copy()方法是用于拷贝(浅拷贝)整个字典:b = a.copy()
- pop(key[, default])和popitem():a.pop(2)—相当于将字典a的键值为2的键值对给去掉,a.popitem()—弹出一个键值对,感觉和pop差不多
- setdefault(key[, default]):setdefault()方法和get()方法有点相似,但是,setdefault()在字典中找不到相应的键时会自动添加:

- update([other]):利用它来更新字典—pets.update(小白="狗");
- 收集参数(**):收集参数其实有两种打包形式:一种是以元组的形式打包;另一种则是以字典的形式打包。当参数带两个星号(**)时,传递给函数的任意数量的key=value实参会被打包进一个字典中。


5.2 集合
主要有以下几个特征:
- (1)无序;
- (2)唯一;
- (3)frozenset()函数,就是把元素给frozen(冰冻)起来。防止集合被修改。
6 文件的读写、文件系统
6.1 文件的读取与写入
尽量少讲些基础概念,直接上实例来进行说明吧。
seek()方法可以调整文件指针的位置。seek(offset, from)方法有两个参数,表示从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset字节。因此将文件指针设置到文件起始位置,使用seek(0, 0)即可。
例1,读取一个文件并打印出来。有一个文件如下所示

(1)要遍历每行的打印文件信息:
>>> file_path='C:/file/data1.txt'
>>> f=open(file_path,'r')
>>> f.seek(0,0)
0
>>> for i in f:
print(i)
dd
dddd
fff
ggh
hh
f这种方式就比较不太友好,每行都把‘/n’换行符带出来了。
(2)通过列表来实现操作每一行信息:
>>> file_path='C:/file/data1.txt'
>>> f=open(file_path,'r').read()
>>> c=f.split('\n')
>>> c
['dd', 'dddd', 'fff', 'ggh', 'hh', 'f']接下来就可以对每个元素进行操作了。一般用的也比较多。
前面主要是说了文件的读取,文件的写入更简单,此处就不多说了。下面介绍一个常用的模块——文件系统。
6.2 文件系统
我们写的每一个源代码文件(*.py)都是一个模块。Python自身带有非常多实用的模块,下面主要介绍os模块。
6.2.1 OS模块
Python是跨平台的语言,也就是说,同样的源代码在不同的操作系统不需要修改就可以同样实现。有了OS模块,不需要关心什么操作系统下使用什么模块,OS模块会帮你选择正确的模块并调用。下面列举了OS模块中关于文件/目录常用的函数使用方法。

另外OS模块还提供了一些很实用的定义,分别是:os.curdir表示当前目录;os.pardir表示上一级目录('..');os.sep表示路径的分隔符,如Windows系统下为'\\',Linux下为'/';os.linesep表示当前平台使用的行终止符(在Windows下为'\r\n',Linux下为'\n');os.name表示当前使用的
操作系统。
6.2.2 OS.path模块
OS.path模块可以完成一些针对路径名的操作。

7 pickle(将数据打包成二进制文件)
Python提供了一个标准模块,使用这个模块,就可以非常容易地将列表、字典这类复杂数据类型存储为文件了。这个模块就是本节要介绍的pickle模块。用官方文档中的话说,这是一个令人惊叹(amazing)的模块,它几乎可以把所有Python的对象都转化为二进制的形式存放,这个过程称为pickling,那么从二进制形式转换回对象的过程称为unpickling。
下面列举相关实例:
将python对象转换成二进制文件:

将刚dump到my_list.pkl文件的数据进行加载,还原成原本的数据:

利用pickle模块,不仅可以保存列表,事实上pickle还可以保存任何你能想象得到的东西。
8 异常处理
python主要有以下这些异常:
- AssertionError:断言语句(assert)失败。例如当assert这个关键字后面的条件为假时,程序将停止并抛出AssertionError异常。assert语句一般是在测试程序的时候用于在代码中置入检查点;
- AttributeError:尝试访问未知的对象属性。当试图访问的对象属性不存在时抛出AttributeError异常;
- IndexError:索引超出序列的范围;
- KeyError:字典中查找一个不存在的关键字;
- NameError:尝试访问一个不存在的变量;
- OSError:操作系统产生的异常;
- SyntaxError:Python的语法错误;
- TypeError:不同类型间的无效操作;
- ZeroDivisionError:除数为零;
异常捕获可以使用try语句来实现,任何出现在try语句范围内的异常都会被及时捕获到。try语句有两种实现形式:一种是try-except;另一种是try-finally。
try......except的语法结构如下:

(1) 针对不同异常设置多个except:

(2)对多个异常统一处理

(3)捕获所有异常
try:
......
except Exception as err:
print("异常:%s"%err)8.1 try......finally语句
引入finally来扩展try。意思是当try内的语句出错时,执行完except后还需要再执行finally内的语句。如果try语句块中没有出现任何运行时错误,会跳过except语句块执行finally语句块的内容。如果出现异常,则会先执行except语句块的内容再执行finally语句块的内容。总之,finally语句块中的内容就是确保无论如何都将被执行的内容。
例如:

8.2 raise语句(给自己的代码抛出异常)
我的代码能不能自己抛出一个异常呢?答案是可
以的例如:

8.3 else语句与try配合
else语句还能与刚刚学的异常处理进行搭配,实现方法与循环语句搭配差不多:只要try语句块里没有出现任何异常,那么就会执行else语句块里的内容。
8.4 with语句
即要打开文件又要关闭文件,还要关注异常处理,有点烦琐,所以Python提供了一个with语句,利用这个语句抽象出文件操作中频繁使用的try/except/finally相关的细节。避免出现文件打开了忘记关闭的问题了(with会自动帮助关闭文件)

9 类和对象(待更)
9.1 对象
总体来说,对象等于属性+方法。用一个例子来说明对象、类、实例是什么关系。

以上代码定义了对象的特征(属性)和行为(方法),但还不是一个完整的对象,将定义的这些称为类(class)。需要使用类来创建一个真正的对象,这个对象就称为这个类的一个实例(instance),也叫实例对象(instance objects)。就好比模具(类)和制造出来的玩具(对象)、图纸(类)和实际建出来的房子(对象)之间的关系。
如何创建一个对象,并根据对象来使用对象里的方法接着上面的例子说。类名后面跟着小括号,这与调用函数是一样的,所以在Python中,类名约定用大写字母开头,函数用小写字母开头,这样更容易区分。
创建对象:

调用对象里的方法:

9.2 面向对象编程
9.2.1 self
同一个类可以生成无数对象,当一个对象的方法被调用的时候,对象会将自身的引用作为第一个参数传给该方法(self),那么Python就知道需要操作哪个对象的方法了。就比如:一张图纸(类)就可以设计出成千上万的房子(对象),它们长得都差不多,但它们都有不同的主人。每个人都只能回自己的家里,陪伴自己的孩子,所以self就相当于每个房子的门牌号,有了self,就可以轻松地找到自己的房子。例如:

9.2.2 构造方法__init__()
通常把_ _init_ _()方法称为构造方法,_ _init_ _()方法的魔力体现在只要实例化一个对象,这个方法就会在对象被创建时自动调用(在C++里也可以看到类似的东西,叫“构造函数”)。其实,实例化对象时是可以传入参数的,这些参数会自动传入_ _init_ _()方法中,可以通过重写这个方法来自定义对象的初始化操作。
举个例子:

9.2.3 公有和私有
默认对象的属性和方法都是公开的,可以直接通过点操作符(.)进行访问:

为了实现类似私有变量的特征,Python内部采用了一种叫Name Mangling(名字改编)的技术,在Python中定义私有变量只需要在变量名或函数名前加上“_ _”两个下画线,那么这个函数或变量就会成为私有的了:

这样要想访问就得从这个类里进行引用。
name mangling(名字改编)——Python只是动了一下手脚,把两个下画线开头的变量进行了改名而已。实际上在外部使用“_类名_ _变量名”即可访问两个下画线开头的私有变量了:

![]()
Python目前的私有机制其实是伪私有,Python的类是没有权限控制的,所有变量都是可以被外部调用的。
9.3 继承
继承的由来——现在需要扩展游戏,对鱼类进行细分,有金鱼(Goldfish)、鲤鱼(Carp)、鲨鱼(Shark),还有好吃的三文鱼(Salmo)。那么再思考一个问题:能不能不要每次都从头到尾去重新定义一个新的鱼类呢?因为大部分鱼的属性和方法是相似的,如果有一种机制可以让这些相似的东西得以自动传递,那就方便、快捷多了。没错,这种机制就是本节要讲的:继承。
类继承的语法很简单:
![]()
被继承的类称为基类、父类或超类;继承者称为子类,一个子类可以继承它的父类的任何属性和方法。举例来说明:

需要注意的是,如果子类中定义与父类同名的方法或属性,则会自动覆盖父类对应的方法或属性。下面再举个例子:

程序实现如下:

这里抛出的异常,Shark对象没有x属性。原因其实是这样的:在Shark类中,重写了魔法方法_ _init_ _,但新的_ _init_ _方法里边没有初始化鲨鱼的x坐标和y坐标,因此调用move方法就会出
错。解决这个问题的方案有2种:(1)调用未绑定的父类方法。(2)使用super函数。推荐一般是用第(2)种。
第(1)种调用未绑定的父类方法:既是在类的构造方法里先调用一下每个父类的构造方法。

第(2)种使用super函数:自动找到基类的方法,而且还传入了self参数。

super函数的“超级”之处在于:不需要明确给出任何基类的名字,它会自动找出所有基类以及对应的方法。由于不用给出基类的名字,这就意味着如果需要改变类继承关系,只要改变class语句里的父类即可,而不必在大量代码中去修改所有被继承的方法。
9.3.1 多重继承
Python还支持多继承,就是可以同时继承多个父类的属性和方法。多重继承的语法如下:
![]()
多重继承很容易导致代码混乱,所以当不确定是否必须使用多重继承的时候,请尽量避免使用它,因为有些时候会出现不可预见的BUG。
9.3.2 组合
把需要的类放进去实例化就可以了,这就叫组合。举例如下:

直接调用pool = Pool(1, 10)即可运行。
9.3.3 类、类对象和实例对象

类中定义的属性是静态变量,也就是相当于C语言中加上static关键字声明的变量,类的属性是与类对象进行绑定,并不会依赖任何它的实例对象。另外,如果属性的名字与方法名相同,属性会覆盖方法,因此一般在定义属性和方法时需要注意两者名称不能重复。
一些约定俗成的规矩:
- (1)不要试图在一个类里边定义出所有能想到的特性和方法,应该利用继承和组合机制来进行扩展;
- (2)用不同的词性命名,如属性名用名词、方法名用动词,并使用骆驼命名法。骆驼式命名法(CamelCase)又称驼峰命名法,是电脑程式编写时的一套命名规则(惯例)。正如它的名称CamelCase所表示的那样,是指混合使用大小写字母来构成变量和函数的名字,程序员为了自己的代码能更容易在同行之间交流,所以多采取统一的可读性比较好的命名方式;
9.3.4 绑定
Python严格要求方法需要有实例才能被调用,这种限制其实就是Python所谓的绑定概念。
9.3.5 一些内置函数(BIF)
1)issubclass(class, classinfo)
如果第一个参数(class)是第二个参数(classinfo)的一个子类,则返回True,否则返回False。
- (1)一个类被认为是其自身的子类。
- (2)classinfo可以是类对象组成的元组,只要class是其中任何一个候选类的子类,则返回True。
- (3)在其他情况下,会抛出一个TypeError异常。
2)isinstance(object, classinfo)
如果第一个参数(object)是第二个参数(classinfo)的实例对象,则返回True,否则返回False。
- (1)如果object是classinfo的子类的一个实例,也符合条件。
- (2)如果第一个参数不是对象,则永远返回False。
- (3)classinfo可以是类对象组成的元组,只要object是其中任何一个候选类的子类,则返回True。
- (4)如果第二个参数不是类或者由类对象组成的元组,会抛出一个TypeError异常。
3)hasattr(object, name)
attr即attribute的缩写,属性的意思。接下来将要介绍的几个BIF都是与对象的属性有关系的,例如hasattr()函数的作用就是测试一个对象里是否有指定的属性。第一个参数(object)是对象,第二个参数(name)是属性名(属性的字符串名字)。
4)getattr(object, name[, default])
返回对象指定的属性值,如果指定的属性不存在,则返回default(可选参数)的值;若没有设置default参数,则抛出ArttributeError异常。
5)setattr(object, name, value)
与getattr()对应,setattr()可以设置对象中指定属性的值,如果指定的属性不存在,则会新建属性并赋值。
6)delattr(object, name)
与setattr()相反,delattr()用于删除对象中指定的属性,如果属性不存在,则抛出AttributeError异常。
7)property(fget=None, fset=None, fdel=None, doc=None)
property()是一个比较“奇葩”的BIF,它的作用是通过属性来设置属性。这个需要举例来说明:

property()返回一个可以设置属性的属性,当然如何设置属性还是需要人为来写代码。第一个参数是获得属性的方法名(例子中是getSize),第二个参数是设置属性的方法名(例子中是setSize),第三个参数是删除属性的方法名(例子中是delSize)。














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









