







 本文介绍了强化学习在解决大规模问题中的应用,重点讲解了值函数近似(线性函数近似和深度神经网络近似)以及策略梯度方法。值函数近似通过函数近似技术,如线性回归和神经网络,来估计状态或动作的价值。策略梯度则是直接优化策略参数,以最大化长期回报。文中还探讨了经验回放、DQN算法和策略梯度定理在强化学习中的作用。
本文介绍了强化学习在解决大规模问题中的应用,重点讲解了值函数近似(线性函数近似和深度神经网络近似)以及策略梯度方法。值函数近似通过函数近似技术,如线性回归和神经网络,来估计状态或动作的价值。策略梯度则是直接优化策略参数,以最大化长期回报。文中还探讨了经验回放、DQN算法和策略梯度定理在强化学习中的作用。
强化学习–值函数近似和策略梯度
文章目录
前两节内容都是强化学习的一些基础理论 ,只能解决一些中小规模的问题,实际情况下很多价值函数需要一张大表来存储,获取某一状态或动作价值的时候通常需要一个查表操作,这对于某些状态或动作空间很大的问题几乎无法求解,而许多实际问题拥有大量状态或动作,甚至是连续的状态和动作。那么,如何解决实际问题呢?主要有两种方法:值函数近似和策略梯度。
1. 值函数近似
强化学习可以用来解决大规模问题,例如西洋双陆棋(Backgammon)有 1 0 20 10^{20} 1020个状态空间,围棋AlphaGo有 1 0 170 10^{170} 10170状态空间,机器人控制以及无人机控制需要的是一个连续状态空间。如何才能将强化学习应用到这类大规模的问题中,进而进行预测和控制呢?
(1)使用值函数近似的解决思路可以是这样的:
①、通过函数近似来估计实际的价值函数:
v ^ ( s , ω ) ≈ v π ( s ) \hat v(s,\omega ) \approx {v_\pi }(s) v^(s,ω)≈vπ(s)
q ^ ( s , a , ω ) ≈ q π ( s , a ) \hat q(s,a,\omega ) \approx {q_\pi }(s,a) q^(s,a,ω)≈qπ(s,a)
其中, ω \omega ω表示函数的参数,如神经网络的参数;
②、把从已知状态学到的函数通用化推广到那些未碰到的状态中;
③、使用蒙特卡洛算法或时序差分学习来更新函数参数。
(2)值函数近似的类型:
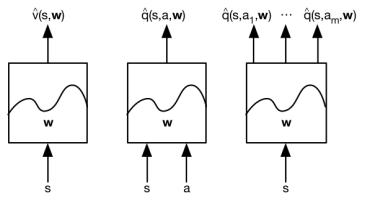
①、针对状态,输出这个状态的近似状态价值;
②、针对状态动作对,输出状态动作对的近似动态价值;
③、针对状态,输出一个向量,向量中每一个元素是该状态下采取一种可能动作的动作价值;注:此时不能用于连续的动作。
(3)有哪些函数近似器?
所有和机器学习相关的算法都可以应用到强化学习中来,其中线性回归和神经网络在强化学习里应用比较广泛,主要是因为这两类方法针对状态可导。
强化学习应用的场景其数据通常是非静态的(non-stationary)和非独立同分布(non-iid)的,因为一个状态数据是可能是持续流入的,而且下一个状态通常与前一个状态是高度相关的。因此,函数近似器也需要适用于非静态、非独立同分布的数据。
注:iid: independent and identically distributed 独立和均匀分布
独立:每次抽样之间是没有关系的,不会相互影响;就像抛骰子每次抛到几就是几这就是独立的,但如果要两次抛的和大于8,其余的不算,那么第一次抛和第二次抛就不独立了,因为第二次抛的时候结果是和第一次相关的。
同分布:每次抽样,样本都服从同样一个分布;抛骰子每次得到任意点数的概率都是1/6,这就是同分布的。但如果第一次抛一个6面的色子,第二次抛一个正12面体的色子,就不再是同分布了。
(4)值函数近似的目标:
寻找参数向量 ω \omega ω,从而最小化近似值函数 v ^ ( s , ω ) \hat v(s,\omega) v^(s,ω)和真实的值函数 v π ( s ) v_{\pi}(s) vπ(s)的均方误差(mean squared error,MSE):
J ( ω ) = E π [ ( v π ( S ) − v ^ ( S , ω ) ) 2 ] J(\omega ) = {E_\pi }[{({v_\pi }(S) - \hat v(S,\omega ))^2}] J(ω)=Eπ[(vπ(S)−v^(S,ω))2]
然后使用随机梯度下降对梯度进行更新。每一步,参数朝着实际的价值函数进行一度程度地逼近。
1.1 线性函数近似
1.1.1 状态价值函数近似
用一个特征向量表示一个状态:
x ( S ) = ( x 1 ( S ) ⋮ x n ( S ) ) x(S) = \left( \begin{array}{l} {x_1}(S)\\ \ \ \ \ \vdots \\ {x_n}(S) \end{array} \right) x(S)=⎝⎜⎛x1(S) ⋮xn(S)⎠⎟⎞
通过对特征的线性求和来近似状态价值函数:
v ^ ( S , ω ) = x ( S ) T ω = ∑ j = 1 n x j ( S ) ω j \hat v(S,\omega) = x(S)^T\omega = \sum\limits_{j = 1}^n {
{x_j}(S){\omega _j}} v^(S,ω)=x(S)Tω=j=1∑nxj(S)ωj
这样,目标函数可以表示为:
J ( ω ) = E π [ ( v π ( S ) − x ( S ) ⊤ ω ) 2 ] J(\omega ) = {E_\pi }[{({v_\pi }(S) - x(S)^{\top}\omega)^2}] J(ω)=Eπ[(vπ(S)−x(S)⊤ω)2]
使用随机梯度下降可以收敛至全局最优解。
参数更新规则比较简单:
∇ ω v ^ ( S , ω ) = x ( S ) {\nabla}_{\omega} \hat v(S,\omega)=x(S) ∇ωv^(S,ω)=x(S)
Δ ω = α ( v π ( S ) − v ^ ( S , ω ) ) x ( S ) \Delta \omega = \alpha(v_{\pi}(S)-\hat v(S,\omega))x(S) Δω=α(vπ(S)−v^(S,ω))x(S)
即:参数更新量=步长*预测误差*特征值;
“查表”方法是一个特殊的线性价值函数近似方法:每一个状态看成一个特征,个体具体处在某一个状态时,该状态特征取1,其余取0。参数的数目就是状态数,也就是每一个状态特征有一个参数。

事实上,之前所列的公式都不能直接用于强化学习,因为公式里都有一个实际价值函数 v π ( S ) v_{\pi}(S) vπ(S),但在强化学习环境中,只有即时奖励,没有真实的价值函数,因此不能直接使用上述公式,需要找到能代替 v π ( S ) v_{\pi}(S) vπ(S)的目标值。
①、对于蒙特卡洛算法,目标值就是回报:
Δ ω = α ( G t − v ^ ( S t , ω ) ) ∇ ω v ^ ( S t , ω ) \Delta \omega = \alpha(G_t-\hat v(S_t,\omega)){\nabla}_{\omega} \hat v(S_t,\omega) Δω=α(Gt−v^(St,ω))∇ωv^(St,ω)
其中,回报 G t G_t Gt是真实状态价值的无偏估计,可以把它看成是监督学习的标签数据,这时,训练数据集可以是: < S 1 , G 1 > , < S 2 , G 2 > , . . . , < S T , G T > <S_1,G_1>, <S_2,G_2>, ..., <S_T,G_T> <S1<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









