









目录
背景:
继提出Faster RCNN之后,大神何凯明进一步提出了新的实例分割网络Mask RCNN,该方法在高效地完成物体检测的同时也实现了高质量的实例分割,获得了ICCV 2017的最佳论文!一举完成了object instance segmentation!!(不仅仅时语义分割,而且是实例分割:不仅仅识别不同类,还要是要识别大类下面的小类)该方法在有效地目标的同时完成了高质量的语义分割。 文章的主要思路就是把原有的Faster-RCNN进行扩展,添加一个分支使用现有的检测对目标进行并行预测。同时,这个网络结构比较容易实现和训练,速度5fps也算比较快点,可以很方便的应用到其他的领域,像目标检测,分割,和人物关键点检测等。

论文地址:
整体结构:
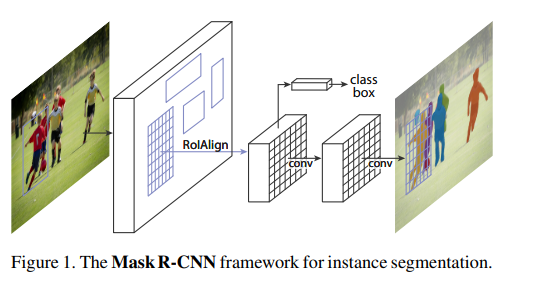
较为清楚的图:
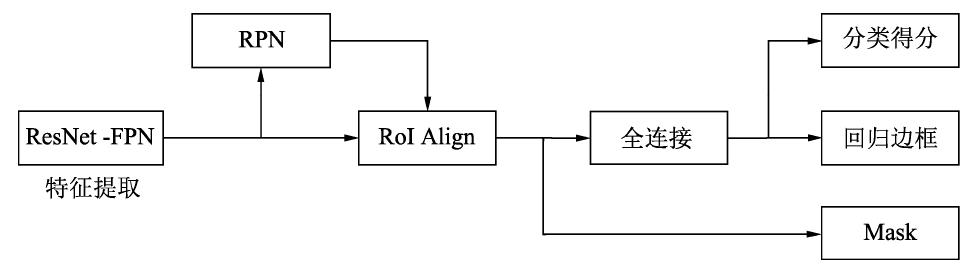
Mask RCNN的网络结构如上图所示,可以看到其结构与Faster RCNN非常类似,但有3点主要区别:
-
在基础网络中采用了较为优秀的ResNet-FPN结构,多层特征图有利于多尺度物体及小物体的检测。
-
提出了RoI Align方法来替代RoI Pooling,原因是RoI Pooling的取整做法损失了一些精度,而这对于分割任务来说较为致命。
-
得到感兴趣区域的特征后,在原来分类与回归的基础上,增加了一个Mask分支来预测每一个像素的类别。
下面将详细介绍这3部分。
1.特征提取网络
当前多尺度的物体检测越来越重要,对于基础的特征提取网络来说,不同层的特征图恰好拥有着不同的感受野与尺度,因此可以利用多层特征图来做多尺度的检测,例如我的另一篇文章HyperNet的详细介绍。 基于ResNet的FPN基础网络也是一个多层特征结合的结构,包含了自下而上、自上而下及横向连接3个部分,这种结构可以将浅层、中层、深层的特征融合起来,使得特征同时具备强语义性与强空间性,具体可参考我的一篇博客FPN简述。 原始的FPN会输出P2、P3、P4与P5 4个阶段的特征图,但在Mask RCNN中又增加了一个P6。将P5进行最大值池化即可得到P6,目的是获得更大感受野的特征,该阶段仅仅用在RPN网络中。原始的Faster RCNN使用单层的特征图时,筛选出的RoI可以直接作用到特征图上进行RoI Pooling,但如果使用FPN作为基础网络时,由于其包含了P2、P3、P4、P5这4个阶段的特征图,筛选出的RoI应该对应到哪一个特征图呢? 对于此问题,Mask RCNN的做法与FPN论文中的方法一致,从合适尺度的特征图中切出RoI,大的RoI对应到高语义的特征图中,如P5,小的RoI对应到高分辨率的特征图中,如P3。式(4-7)中给出了精确的计算公式:

公式中的224代表着ImageNet预训练图片的大小,k0默认值为4,表示大小为224×224的RoI应该对应的层级为4,计算后做取整处理。 这样的分配方法保证了大的RoI从高语义的特征图上产生,有利于检测大尺度物体,小的RoI从高分辨率的特征图上产生,有利于小物体的检测。
2.RoI Align部分
Faster RCNN原始使用的RoI Pooling存在两次取整的操作,导致RoI选取出的特征与最开始回归出的位置有一定的偏差,称之为不匹配问题(Missalignment),严重影响了检测或者分割的准确度。
那么什么是Missalignment(特征失调问题)?
目标检测中的Feature Alignment问题主要分为:
1.分类与回归特征不匹配问题,即分类与回归部分所需要的特征不同,当前使用共享全连接层或者卷积层的操作会带来特征冲突问题。
2.Anchor与特征不对齐问题,主要包含两个:
-
feature map上的同一个点同时对应了大小不同的多个anchor,这里存在一个对齐的问题,可以使用FPN结构缓解;
-
回归后的Anchor相对于原始位置已经发生了较大变化,但是分类和回归仍然使用原始位置特征进行预测,这也是特征对不齐的问题。
Maks RCNN提出的RoI Align取消了取整操作,而是保留所有的浮点,然后通过双线性插值的方法获得多个采样点的值,再将多个采样点进行最大值的池化,即可得到该点最终的值。 由于使用了采样点与保留浮点的操作,RoI Align获得了更好的性能。这部分在前面已经详细介绍过,在此不再重复。
3.损失任务设计
在得到感兴趣区域的特征后,Mask RCNN增加了Mask分支来进行图像分割,确定每一个像素具体属于哪一个类别。具体实现时,采用了FCN(Fully Convolutional Network)的网络结构,利用卷积与反卷积构建端到端的网络,最后对每一个像素分类,实现了较好的分割效果。由于属于分割领域、在此不对FCN细节做介绍,感兴趣的读者可以查看相关资料。 假设物体检测任务的类别是21类,则Mask分支对于每一个RoI,输出的维度为21×m×m,其中m×m表示mask的大小,每一个元素都是二值的,相当于得到了21个二值的mask。在训练时,如果当前RoI的标签类别是5,则只有第5个类别的mask参与计算,其他的类别并不参与计算。这种方法可以有效地避免类间竞争,将分类的任务交给更为专业的分类分支去处理。 增加了Mask分支后,损失函数变为了3部分,如式所示。
公式中前两部分Lcls、Lbox与Faster RCNN中相同,最后一部分Lmask代表了分割的损失。对mask上的每一个像素应用Sigmoid函数,送到交叉熵损失中,最后取所有像素损失的平均值作为Lnask。 Mask RCNN算法简洁明了,在物体检测与实例分割领域都能得到较高的精度,在实际应用中,尤其是涉及多任务时,可以采用Mask RCNN算法。
4.相应代码:
训练代码:
import logging
import os
from collections import OrderedDict
import torch
import detectron2.utils.comm as comm
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import MetadataCatalog
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, hooks, launch
from detectron2.evaluation import (
CityscapesInstanceEvaluator,
CityscapesSemSegEvaluator,
COCOEvaluator,
COCOPanopticEvaluator,
DatasetEvaluators,
LVISEvaluator,
PascalVOCDetectionEvaluator,
SemSegEvaluator,
verify_results,
)
from detectron2.modeling import GeneralizedRCNNWithTTA
def build_evaluator(cfg, dataset_name, output_folder=None):
"""
Create evaluator(s) for a given dataset.
This uses the special metadata "evaluator_type" associated with each builtin dataset.
For your own dataset, you can simply create an evaluator manually in your
script and do not have to worry about the hacky if-else logic here.
"""
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
evaluator_list = []
evaluator_type = MetadataCatalog.get(dataset_name).evaluator_type
if evaluator_type in ["sem_seg", "coco_panoptic_seg"]:
evaluator_list.append(
SemSegEvaluator(
dataset_name,
distributed=True,
output_dir=output_folder,
)
)
if evaluator_type in ["coco", "coco_panoptic_seg"]:
evaluator_list.append(COCOEvaluator(dataset_name, output_dir=output_folder))
if evaluator_type == "coco_panoptic_seg":
evaluator_list.append(COCOPanopticEvaluator(dataset_name, output_folder))
if evaluator_type == "cityscapes_instance":
assert (
torch.cuda.device_count() > comm.get_rank()
), "CityscapesEvaluator currently do not work with multiple machines."
return CityscapesInstanceEvaluator(dataset_name)
if evaluator_type == "cityscapes_sem_seg":
assert (
torch.cuda.device_count() > comm.get_rank()
), "CityscapesEvaluator currently do not work with multiple machines."
return CityscapesSemSegEvaluator(dataset_name)
elif evaluator_type == "pascal_voc":
return PascalVOCDetectionEvaluator(dataset_name)
elif evaluator_type == "lvis":
return LVISEvaluator(dataset_name, output_dir=output_folder)
if len(evaluator_list) == 0:
raise NotImplementedError(
"no Evaluator for the dataset {} with the type {}".format(dataset_name, evaluator_type)
)
elif len(evaluator_list) == 1:
return evaluator_list[0]
return DatasetEvaluators(evaluator_list)
class Trainer(DefaultTrainer):
"""
We use the "DefaultTrainer" which contains pre-defined default logic for
standard training workflow. They may not work for you, especially if you
are working on a new research project. In that case you can write your
own training loop. You can use "tools/plain_train_net.py" as an example.
"""
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
return build_evaluator(cfg, dataset_name, output_folder)
@classmethod
def test_with_TTA(cls, cfg, model):
logger = logging.getLogger("detectron2.trainer")
# In the end of training, run an evaluation with TTA
# Only support some R-CNN models.
logger.info("Running inference with test-time augmentation ...")
model = GeneralizedRCNNWithTTA(cfg, model)
evaluators = [
cls.build_evaluator(
cfg, name, output_folder=os.path.join(cfg.OUTPUT_DIR, "inference_TTA")
)
for name in cfg.DATASETS.TEST
]
res = cls.test(cfg, model, evaluators)
res = OrderedDict({k + "_TTA": v for k, v in res.items()})
return res
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg()
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
cfg.freeze()
default_setup(cfg, args)
return cfg
def main(args):
cfg = setup(args)
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if cfg.TEST.AUG.ENABLED:
res.update(Trainer.test_with_TTA(cfg, model))
if comm.is_main_process():
verify_results(cfg, res)
return res
"""
If you'd like to do anything fancier than the standard training logic,
consider writing your own training loop (see plain_train_net.py) or
subclassing the trainer.
"""
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)框架代码:
import fvcore.nn.weight_init as weight_init
import torch.nn.functional as F
from detectron2.layers import CNNBlockBase, Conv2d, get_norm
from detectron2.modeling import BACKBONE_REGISTRY
from detectron2.modeling.backbone.resnet import (
BasicStem,
BottleneckBlock,
DeformBottleneckBlock,
ResNet,
)
class DeepLabStem(CNNBlockBase):
"""
The DeepLab ResNet stem (layers before the first residual block).
"""
def __init__(self, in_channels=3, out_channels=128, norm="BN"):
"""
Args:
norm (str or callable): norm after the first conv layer.
See :func:`layers.get_norm` for supported format.
"""
super().__init__(in_channels, out_channels, 4)
self.in_channels = in_channels
self.conv1 = Conv2d(
in_channels,
out_channels // 2,
kernel_size=3,
stride=2,
padding=1,
bias=False,
norm=get_norm(norm, out_channels // 2),
)
self.conv2 = Conv2d(
out_channels // 2,
out_channels // 2,
kernel_size=3,
stride=1,
padding=1,
bias=False,
norm=get_norm(norm, out_channels // 2),
)
self.conv3 = Conv2d(
out_channels // 2,
out_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False,
norm=get_norm(norm, out_channels),
)
weight_init.c2_msra_fill(self.conv1)
weight_init.c2_msra_fill(self.conv2)
weight_init.c2_msra_fill(self.conv3)
def forward(self, x):
x = self.conv1(x)
x = F.relu_(x)
x = self.conv2(x)
x = F.relu_(x)
x = self.conv3(x)
x = F.relu_(x)
x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
return x
@BACKBONE_REGISTRY.register()
def build_resnet_deeplab_backbone(cfg, input_shape):
"""
Create a ResNet instance from config.
Returns:
ResNet: a :class:`ResNet` instance.
"""
# need registration of new blocks/stems?
norm = cfg.MODEL.RESNETS.NORM
if cfg.MODEL.RESNETS.STEM_TYPE == "basic":
stem = BasicStem(
in_channels=input_shape.channels,
out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
norm=norm,
)
elif cfg.MODEL.RESNETS.STEM_TYPE == "deeplab":
stem = DeepLabStem(
in_channels=input_shape.channels,
out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
norm=norm,
)
else:
raise ValueError("Unknown stem type: {}".format(cfg.MODEL.RESNETS.STEM_TYPE))
# fmt: off
freeze_at = cfg.MODEL.BACKBONE.FREEZE_AT
out_features = cfg.MODEL.RESNETS.OUT_FEATURES
depth = cfg.MODEL.RESNETS.DEPTH
num_groups = cfg.MODEL.RESNETS.NUM_GROUPS
width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP
bottleneck_channels = num_groups * width_per_group
in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS
stride_in_1x1 = cfg.MODEL.RESNETS.STRIDE_IN_1X1
res4_dilation = cfg.MODEL.RESNETS.RES4_DILATION
res5_dilation = cfg.MODEL.RESNETS.RES5_DILATION
deform_on_per_stage = cfg.MODEL.RESNETS.DEFORM_ON_PER_STAGE
deform_modulated = cfg.MODEL.RESNETS.DEFORM_MODULATED
deform_num_groups = cfg.MODEL.RESNETS.DEFORM_NUM_GROUPS
res5_multi_grid = cfg.MODEL.RESNETS.RES5_MULTI_GRID
# fmt: on
assert res4_dilation in {1, 2}, "res4_dilation cannot be {}.".format(res4_dilation)
assert res5_dilation in {1, 2, 4}, "res5_dilation cannot be {}.".format(res5_dilation)
if res4_dilation == 2:
# Always dilate res5 if res4 is dilated.
assert res5_dilation == 4
num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
stages = []
# Avoid creating variables without gradients
# It consumes extra memory and may cause allreduce to fail
out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
max_stage_idx = max(out_stage_idx)
for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
if stage_idx == 4:
dilation = res4_dilation
elif stage_idx == 5:
dilation = res5_dilation
else:
dilation = 1
first_stride = 1 if idx == 0 or dilation > 1 else 2
stage_kargs = {
"num_blocks": num_blocks_per_stage[idx],
"stride_per_block": [first_stride] + [1] * (num_blocks_per_stage[idx] - 1),
"in_channels": in_channels,
"out_channels": out_channels,
"norm": norm,
}
stage_kargs["bottleneck_channels"] = bottleneck_channels
stage_kargs["stride_in_1x1"] = stride_in_1x1
stage_kargs["dilation"] = dilation
stage_kargs["num_groups"] = num_groups
if deform_on_per_stage[idx]:
stage_kargs["block_class"] = DeformBottleneckBlock
stage_kargs["deform_modulated"] = deform_modulated
stage_kargs["deform_num_groups"] = deform_num_groups
else:
stage_kargs["block_class"] = BottleneckBlock
if stage_idx == 5:
stage_kargs.pop("dilation")
stage_kargs["dilation_per_block"] = [dilation * mg for mg in res5_multi_grid]
blocks = ResNet.make_stage(**stage_kargs)
in_channels = out_channels
out_channels *= 2
bottleneck_channels *= 2
stages.append(blocks)
return ResNet(stem, stages, out_features=out_features).freeze(freeze_at)比较完整的项目代码,可参考下面地址:
具体代码可参考:Github地址
【我有预感,点赞、评论和关注我的人,痘痘会慢慢消下去,皮肤会变白,变瘦变高,成绩上升,事业突出,会越来越好,喜欢你的人会向你表白,世人如满天星斗,而你皆如万人捧花,祝你也祝我!!!】
















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











