







基于容忍因子的近似最近邻混合查询算法
贺广福1,2, 薛源海1,陈翠婷1,2,俞晓明1,2,刘欣然1,3,程学旗1,2
1中国科学院计算技术研究所,北京 100190
2中国科学院大学,北京 101408
3北京邮电大学,北京 100876
摘要:近似最近邻搜索(ANNS)是计算机领域中一种重要的高效相似度搜索技术,可用于在大规模数据集中进行快速信息检索。随着人们对高精度信息检索的需求不断增长,同时使用结构化信息和非结构化信息进行混合查询的方式也得到了广泛应用。然而,基于近邻图的过滤贪心算法在混合查询时可能会因结构化约束条件的影响导致连通性降低,进而损害搜索精度。为此,提出了一种基于容忍因子的过滤贪心算法,通过容忍因子控制不满足结构化约束条件的顶点参与路由,在不改变索引结构的前提下维持原有近邻图的连通性,克服了结构化约束条件对检索精度的负面影响。实验结果证明,新算法可以在不同结构化约束强度下实现ANNS的高精度搜索,同时保持检索效率。该研究解决了基于近邻图的ANNS在混合查询场景中的问题,为大规模数据集的快速混合查询信息检索提供了一种有效的解决方案。
关键词:混合查询 ; 向量检索 ; 最近邻搜索 ; 过滤搜索

论文引用格式:
贺广福, 薛源海, 陈翠婷, 等. 基于容忍因子的近似最近邻混合查询算法[J]. 大数据, 2024, 10(1): 17-34.
HE G F, XUE Y H, CHEN C T, et al. Approximate nearest neighbor hybrid query algorithm based on tolerance factor[J]. Big Data Research, 2024, 10(1): 17-34.

0 引言
近年,近似最近邻搜索(approximate nearest neighbor search,ANNS)已经在图像搜索、信息推荐、序列匹配、大语言模型应用等领域成为一个重点研究课题。基于近似近邻图的ANNS算法在处理大规模高维数据搜索时显示出较高的搜索效率和准确性。随着人们对高精度信息检索的需求不断增长,同时使用结构化信息和非结构化信息进行混合查询(hybrid query)的方式也得到了广泛应用。例如在电商的商品搜索中,可能需要依据图片这类非结构信息和生产日期、价格、销量等结构化信息进行混合查询,精确地搜索相关产品。然而,ANNS主要关注非结构化信息,对结构化信息的影响关注较少,这导致ANNS在满足结构化约束信息检索需求方面的表现并不理想。
为了解决这类问题,研究者们在相关领域提出的混合查询方法一般可以分为3类,即前处理(pre-process)、后处理(post-process)和内联处理(inlineprocessing)。其中前处理需要大量的时间和空间来构建数据结构;后处理需要对检索的结果进行修正,存在一定的误差和不确定性;内联处理方法可以直接在查询过程中进行最近邻的计算,具有高效、准确的特点,尤其是对实时性要求较高的应用场景。
在非结构化信息检索中,基于近邻图类的ANNS算法在高维度、大规模数据集上表现优异,因此扩展此类方法的内联处理混合查询具有较好的应用前景,是ANNS领域的重要研究分支。基于近邻图的内联混合查询中,一般使用贪心过滤搜索(filtered greedy search,FGS)算法在近似近邻图上检索路由。但是,该方法在查询时仅依据满足结构化约束的点进行路由,降低了ANNS在构建索引时近邻图的连通性预期,导致检索结果的精确度下降。
针对上述挑战,本文提出了一种基于容忍因子的过滤贪心搜索(tolerance factor based filtered greedy search,TF-FGS)算法。TF-FGS算法通过引入容忍因子,在不改变索引结构的前提下保留近邻图的连通性,从而解决由于结构化约束对搜索算法造成的影响,提升了结果准确率。同时, TF-FGS算法保留了与没有结构化约束的ANNS近似的搜索效率。实验表明,在混合查询场景中,本文提出的方法在不牺牲检索效率的前提下,有更好的搜索准确率。
本文的主要贡献如下。
● 分析了FGS算法存在的问题。在搜索过程中,路由候选集合所有向量必须满足结构化约束,过度约束了可路由的路径,影响了路由过程中近邻图的连通性,导致搜索准确率下降。
● 提出了一种TF-FGS算法,在不改变索引结构的条件下,允许不满足结构化约束的向量参与路由,在维持原有检索效率的同时,提升了检索结果的准确率。
● 在不同类型的基准数据集上进行了实验,验证本文提出的TF-FGS算法相比FGS算法,在保持查询效率不变的情况下,提高了混合查询的准确率。
1 问题定义
本节定义了最近邻搜索、近似最近邻搜索、混合场景下的近似最近邻问题。
1.1 最近邻搜索和近似最近邻搜索
最近邻搜索问题是依据查询条件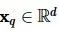 和
和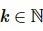 ,从包含 N 个
,从包含 N 个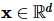 向量的数据集P中,搜索出离查询目标向量
向量的数据集P中,搜索出离查询目标向量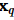 最近的k 个向量。距离的计算方式有多种,不限于欧氏距离、余弦距离等。本文以欧氏距离为例进行说明,计算方法如下:
最近的k 个向量。距离的计算方式有多种,不限于欧氏距离、余弦距离等。本文以欧氏距离为例进行说明,计算方法如下:
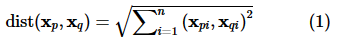
在实际应用中,需要在高维数据集中进行最近邻搜索。但是,高维数据距离计算开销很大,精确搜索的查询效率很低,无法满足实际需求。因此,一般设计近似最近邻搜索算法来解决最近邻搜索问题。ANNS算法的目标是最大化为:
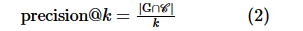
高效地召回拥有k 个向量的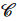 集合,其中,G 表示在P中距离
集合,其中,G 表示在P中距离 最近的k 个向量。
最近的k 个向量。
1.2 结构化约束
在数据集P中,向量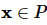 包含了若干属性或者标签
包含了若干属性或者标签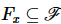 ,其中
,其中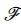 表示向量上有限个标签或者属性。结构化约束条件为
表示向量上有限个标签或者属性。结构化约束条件为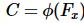 ,定义为由向量的属性或标签
,定义为由向量的属性或标签
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









