







时间步合成扩散模型的鲁棒半监督分割
摘要
医学图像分割是一项具有挑战性的任务,由于许多数据集的大小和注释的限制,使得分割更加困难。消噪扩散概率模型(DDPM)最近在模拟自然图像的分布方面显示出前景,并成功地应用于各种医学成像任务。这项工作的重点是使用扩散模型进行半监督图像分割,特别是处理域泛化。首先,我们证明了较小的扩散步长产生的潜在表征对下游任务比较大步长更鲁棒。其次,我们利用这一见解提出了一种改进的相似方案,该方案利用信息密集的小步骤和大步骤的正则化效应来生成预测。我们的模型在领域转移设置中表现出明显更好的性能,同时在领域内保持竞争性能。总的来说,这项工作突出了ddpm在半监督医学图像分割方面的潜力,并提供了在域移位下优化其性能的见解。
1 介绍
去噪扩散概率模型(DDPM) (Sohl-Dickstein等,2015;Ho等人,2020)最近成为自然图像分布建模的一种有前途的方法,在样本真实感和多样性方面优于其他方法。最近,DDPM也成功地应用于各种医学成像任务,如合成图像生成(Kim and Ye, 2022),图像重建(Xie and Li, 2022;Peng et al ., 2022),异常检测(Wolleb et al ., 2022;Pinaya等人,2022),诊断(Aviles-Rivero等人,2022)和分割(Wolleb等人,2022)。
图像分割在医学成像中至关重要,需要准确有效的方法来支持诊断、治疗计划和疾病监测。然而,医学成像数据集通常规模有限,可能缺乏足够的注释,这使得训练准确的分割模型具有挑战性。此外,由于采集参数、扫描仪类型和患者人口统计数据的差异,医学成像数据具有高度可变性的特点。这种现象,也被称为领域转移,对应用于新数据集的分割模型的泛化提出了重大挑战,导致临床环境中潜在的性能不佳。
最近对扩散模型的研究显示了半监督学习的有希望的结果(Baranchuk等人,2021;Deja等人,2023)基于瓶颈网络的发现,瓶颈网络的任务是学习从图像中去除噪声的反向过程,也学习了一种富有表现力的特征表示,可以有利于其他下游分析任务。已经提出了几种技术来利用中间扩散步骤来改善域内下游性能。然而,需要对这些设计选择对模型泛化的影响进行更多的研究。
我们的工作重点是后一个问题。
具体来说,我们研究了如何最优地利用扩散步骤来提高域移位下半监督图像分割的泛化。
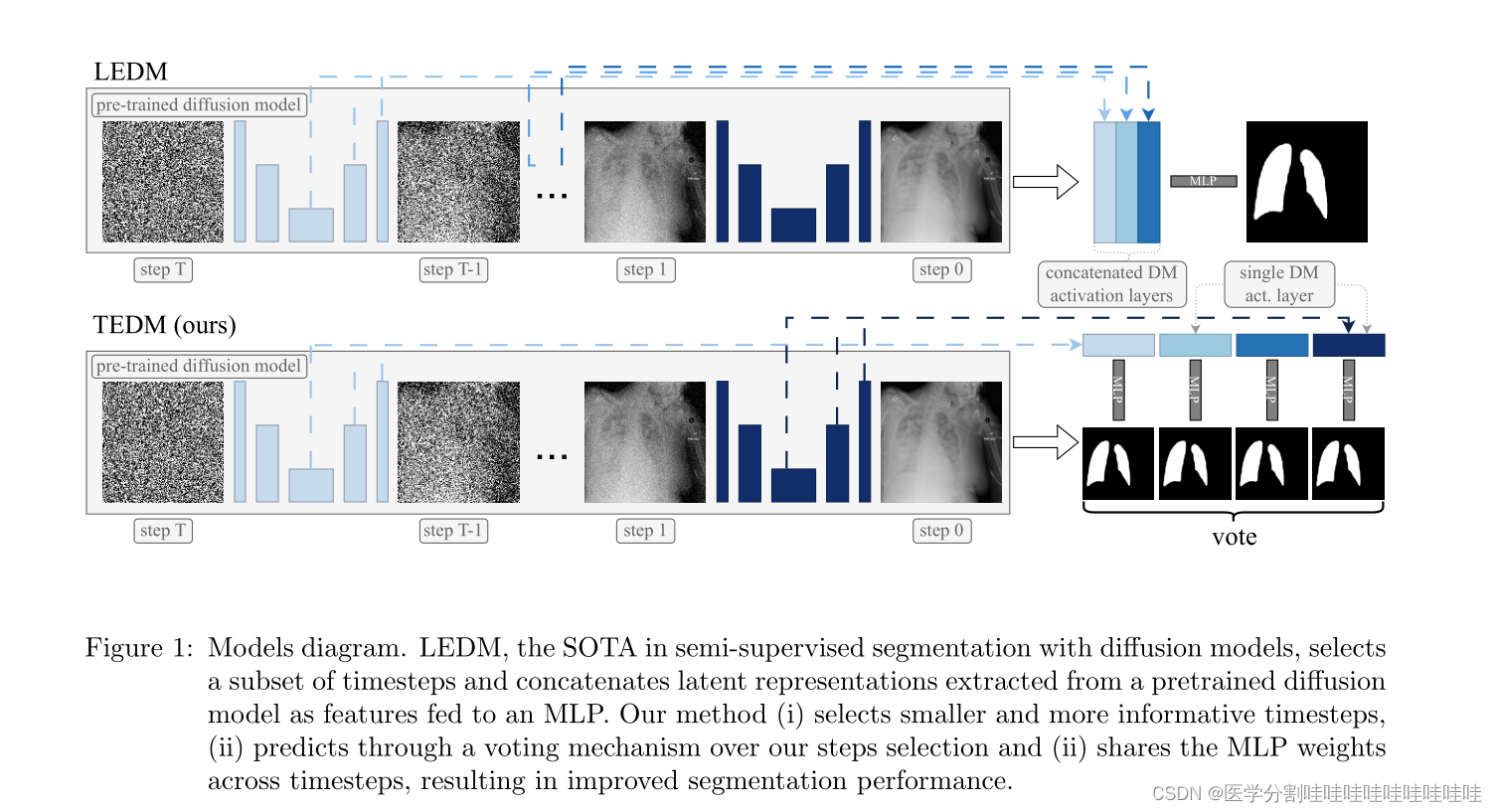
图1:模型图。LEDM是带有扩散模型的半监督分割中的SOTA,它选择一个时间步长子集,并将从预训练的扩散模型中提取的潜在表征连接起来作为特征馈入MLP。我们的方法(i)选择更小和更有信息量的时间步长,(ii)通过投票机制对我们的步骤选择进行预测,(ii)跨时间步长共享MLP权重,从而提高分割性能。
基于对不同成像方式和域转移的数据集的分析,我们的研究结果表明,使用五种不同的数据集,比现有的基线有了显著的改进。我们的主要发现可以总结如下:
①小的扩散步骤对模型泛化至关重要;
②通过步骤串联潜在表示来预测分割图可能会损害泛化;
③相反,通过(i)优化在测试时使用的时间步长,(ii)使用共享预测器从单个时间步长集成预测,以及(iii)在训练期间使用这些单个预测进行正则化,可以显著改善泛化。
2. 背景及相关工作
2.1. 扩
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2990
2990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









